


















强化学习简介(第一部分)

强化学习是机器学习的一个方向,智能体通过执行某些操作并观察从这些操作中获得的奖励或者结果来学习在环境中行为。
机器人手臂操纵技术的进步,Google的Deep Mind击败专业的围棋玩家,以及最近OpenAI团队击败了专业的DOTA玩家,近年来强化学习领域处于爆发状态。

在本文中,我们将讨论:
- 什么是强化学习以及它的本质,如奖励,任务等
- 强化学习的分类
什么是强化学习?
首先让我们举个例子进行解释 - 比如有一个婴儿开始学习如何走路。
我们将这个例子分为两部分:
1. 宝宝开始走路,成功地达到了沙发上
由于沙发是最终目标,孩子和父母都很开心。
所以,宝宝很开心并得到父母的赞赏。这是积极的(或者说正向的/阳性的) - 宝宝感觉良好(正奖励+n)。
2. 宝宝开始走路,由于中间的障碍而摔倒,并被擦伤。
宝宝受伤并且疼痛。这是消极的 - 婴儿哭(负奖励-n)。
这就是我们人类学习的方式 - 通过跟踪和试错。强化学习在概念上与此相同的,它通过行为进行学习,但是一种计算的方法。
强化学习
让我们假设我们的强化学习智能体正在学习马里奥。强化学习过程可以建模为迭代循环,其工作方式如下:
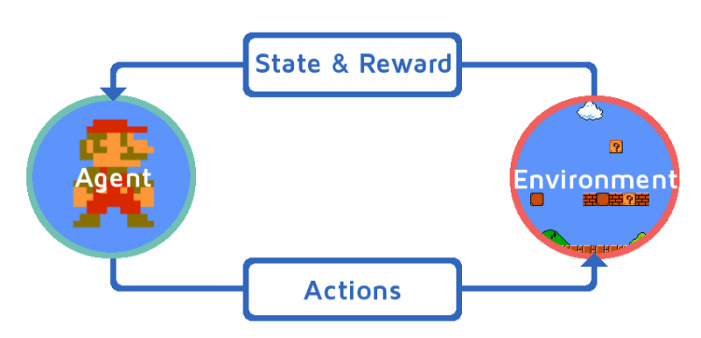
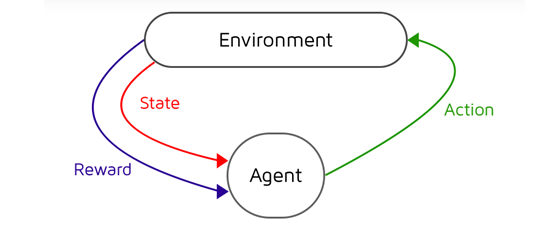
- RL智能体从环境(即马里奥)接收状态 S⁰
- 基于该状态S⁰, RL智能体采取动作A⁰,比如说 - 我们的RL智能体向右移动。最初,这是随机的。
- 现在,环境处于新的状态S¹(来自马里奥或游戏引擎的新帧)
- 环境给予RL智能体一些奖励 R¹。它可能会给出+1,因为智能体还没有死。
这个RL循环一直持续到我们死了或到达目的地,并且它不断输出一系列状态,动作和奖励。
我们的RL智能体的基本目标是最大化奖励。
奖励最大化
RL智能体的工作原理基于奖励最大化的假设。所以强化学习应该采取最佳行动以最大化奖励。
每个时间步与相应的操作的累积奖励为:
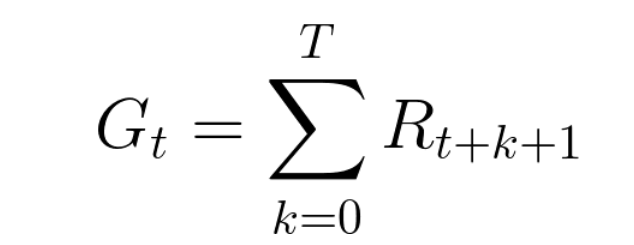
但是,在总结所有的奖励时,事情并不是这样运作的。
让我们详细了解一下:
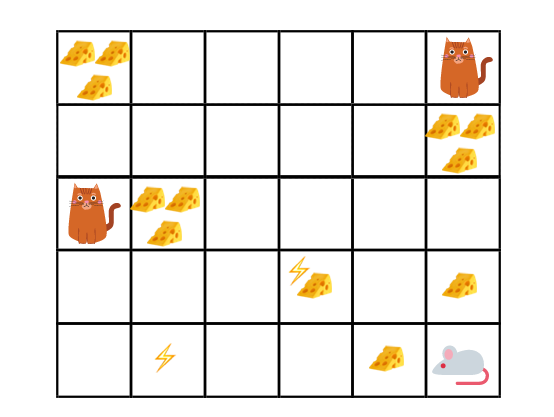
假设我们的RL智能体(机器老鼠)在迷宫中,其中包含奶酪,电击和猫。目标是在被猫吃掉或受到电击之前吃掉最多的奶酪。
很明显,最好吃我们附近的奶酪而不是靠近猫或有电击的奶酪,因为我们越接近电击或猫,死亡的危险就越大。因此,猫或电击附近的奖励,即使它更大(奶酪更多),也会打折扣。这是因为不确定因素。
让奖励打折的方法如下:
我们定义了一个名为gamma(γ)的折扣率。它应该在0和1之间。γ越大,折扣越小。
因此,我们的累计的预期(折扣)奖励是:

累积的预期奖励
强化学习中的任务及其类型
任务是强化学习问题的一个实例。一般有两种类型的任务:持续和偶发。
持续的任务
持续的任务类型。例如,一个做自动外汇/股票交易的RL智能体。
在这种情况下,智能体必须学习如何选择最佳操作,并且同时要与环境交互。没有起点和终点状态。
RL智能体必须持续运行,直到我们决定手动停止它。
偶发任务
在这种情况下,我们有一个起点和终点,称为终端状态(terminal state)。这会创建一个情节(episode):状态列表(S)、行为列表(a)、奖励列表(R)
例如,打一场反恐精英(CS),我们射杀我们的对手或者被他们杀死。我们射杀了他们,完成了这段情节,否则我们就会被杀死。所以,只有两种情况可以完成情节。
探索和开发的权衡
强化学习中有一个重要的探索和开发权衡概念。探索就是要找到有关环境的更多信息,而开发则利用已知信息来最大化回报。
真实生活示例:假设你每天都去同一家餐馆。你基本上是在开发。但是,如果你每次去这些餐馆都要去搜索的新餐馆,这就是探索。探索对于寻找未来的回报是非常重要的,未来的回报可能会高于近期的回报。
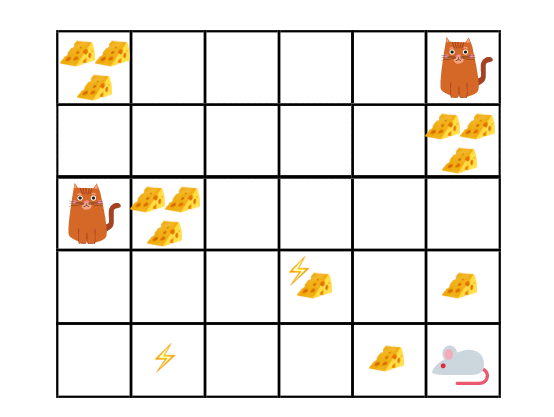
在上面的游戏中,我们的机器人鼠标可以有很多小奶酪(每个+0.5)。但在迷宫顶部有一堆奶酪(+100)。因此,如果我们只专注于最近的奖励,我们的机器鼠永远不会获得大堆的奶酪 - 它只会开发。
但是,如果机器人鼠标进行了一些探索,它可以找到大奖励,即大奶酪。
这是探索和开发权衡的基本概念。
强化学习的方法
现在让我们学习解决强化学习问题的方法。一般来说有3种方法,但我们在本文中只将两种主要方法:
1.基于策略的方法
在基于策略的强化学习中,我们有一个我们需要优化的策略。该策略主要定义了智能体的行为:

我们学习了一个策略函数,帮助我们将每种情况映射到最佳行为。
深入了解政策,我们进一步将策略分为两类:
- 确定性:给定状态下的策略将始终返回相同的行为(a)。这意味着,它被预映射为S =(s)→A=(a)。
- 随机:它给出了不同行为的概率分布。即随机策略→p(A = a | S = s)
2.基于价值
在基于价值的强化学习中,智能体的目标是优化价值函数V(s),这个函数被定义为告诉我们智能体要达到的每个状态下获得的最大预期未来奖励。
每个状态的价值是RL智能体可以预期从特定状态获得的奖励总额。
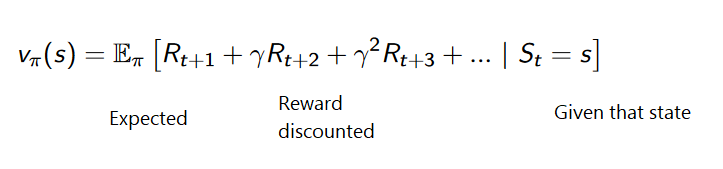
智能体将使用上述价值函数来挑选每个步骤中选择的状态。智能体将始终采用具有最大价值的状态。
在下面的例子中,我们看到,在每一步,我们将采取的最大价值,以实现我们的目标:1 → 3 → 4→6等等...
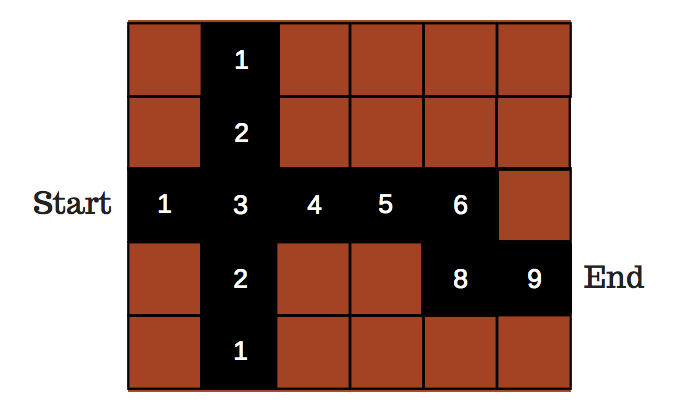
迷宫
案例研究:Pong游戏

让我们以Pong游戏为例。本案例研究将向你介绍强化学习如何运作。当然在这里还不会介绍的太详细,但本系列的下一篇文章中我们肯定会继续深入挖掘。
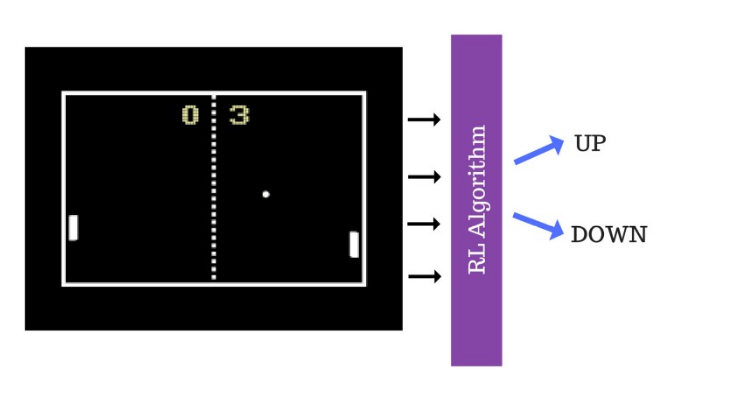
假设我们教RL智能体玩Pong游戏。
基本上,我们将游戏帧(新状态)输入到RL算法中,让算法决定向上或向下。这个网络就是一个策略网络。
用于训练该算法的方法称为策略梯度。我们从游戏引擎提供随机帧,算法关于产生随机输出,给出奖励,并将其反馈给算法或网络。循环此过程。
环境=游戏引擎和智能体=RL智能体
在游戏的上下文中,记分板充当奖励或反馈传给智能体。每当智能体倾向于获得+1时,它就会理解在该状态下它所采取的行动已经足够好了。
现在我们将训练智能体进行Pong游戏。首先,我们将向网络提供一串游戏帧(状态)并让其决定行为。智能体的初始行为显然会很糟糕,但我们的智能体有时可能会由于幸运得分,这是个随机事件。但由于这个幸运的随机事件使它收到奖励,有助于智能体了解这一系列行动足以获得奖励。
训练期间的结果
因此,在将来,智能体可能会采取获取奖励的行动。

限制
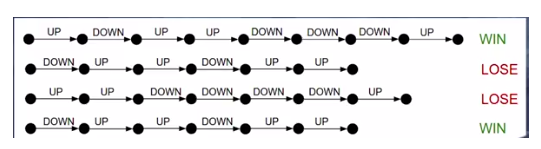
在智能体的训练期间,当智能体在一个情节中失败时,算法将丢弃或降低采取这个情节中存在的所有系列动作的可能性。
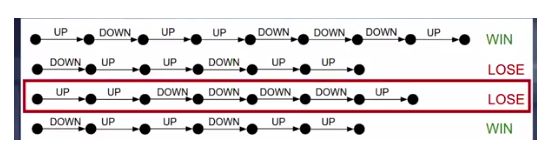 红色边框中显示失败情节中的所有动作
红色边框中显示失败情节中的所有动作
但是如果智能体一开始表现得很好,但由于最后2个行为智能体输掉了游戏,没有道理放弃所有行为。相反,我们最好只删除导致失败的最后2个行为。
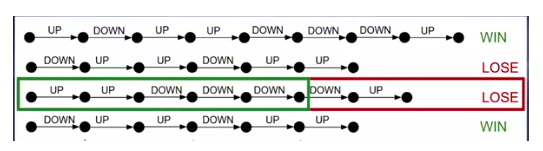
绿色划界显示了正确的行为,红色边框是应该被移除的行动。
这称为信用分配问题。产生这个问题的原因是奖励稀疏的设置。也就是说,我们不会在每一步获得奖励,而是在情节结束时获得奖励。因此,智能体可以了解哪些操作是正确的,哪些实际操作导致失去游戏。
因此,由于RL这种的稀疏奖励设置,算法采样效率很低。这意味着必须提供大量的训练实例,以训练智能体。但事实是,由于环境的复杂性,稀疏奖励设置在许多情况下都会失败。
因此,有一种称为奖励塑造(rewards shaping)的东西,用于解决这个问题。但同样,由于我们需要为每一款游戏设计一个自定义的奖励函数,所以奖励塑造也有一定的局限性。
总结
如今,强化学习是一个令人兴奋的研究领域。该领域已经取得了重大进展,其中深度强化学习就是其中之一。
但是,我想提一下,强化学习不是黑箱。我们今天在强化学习领域所看到的任何进步,都是一群头脑聪明的人夜以继日地研究特定应用的结果。
下一篇我们将介绍Q-learning智能体工作,并讨论一些强化学习的基础知识。









