











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌和OpenAI开发新工具,以更好地研究机器视觉算法如何理解世界
2019年03月07日 由 马什么梅 发表
711421
0
 AI的世界到底是什么样子的?几十年来,研究人员一直对此感到困惑,但近年来,机器视觉系统正在越来越多的生活领域得到应用,但是通过机器的眼睛去理解为什么它将行人和路标分别归类仍然是一个挑战。
AI的世界到底是什么样子的?几十年来,研究人员一直对此感到困惑,但近年来,机器视觉系统正在越来越多的生活领域得到应用,但是通过机器的眼睛去理解为什么它将行人和路标分别归类仍然是一个挑战。谷歌和OpenAI的新研究希望通过这些系统理解世界的视觉数据,进一步打开AI的黑匣子。这种被称为“激活地图集(Activation Atlases)”的方法让研究人员可以分析各种算法的工作原理,不仅揭示了它们识别的抽象形状,颜色和图案,还揭示了如何将这些元素结合起来识别特定的物体,动物和场景。
谷歌的Shan Carter是这项工作的首席研究员,他表示,如果先前的研究就像在算法的视觉字母表中显示单个字母一样,激活地图集提供了更类似整个字典的东西,显示字母是如何组合在一起制作实际字词的。因此,在像鲨鱼这样的图像类别中,会有很多激活因素,比如牙齿和水。
这项工作不一定是一个巨大的突破,但它在更广泛的特征可视化研究领域中向前迈出了一步佐治亚理工学院的博士生Ramprasaath Selvaraju虽然没有参与这项工作,但他说这项研究非常令人着迷,并结合了许多现有的想法创造出一个非常有用的新工具。
Selvaraju认为在未来,这样的工作将有很多用途,帮助我们建立更高效和先进的算法,并通过让研究人员进入内部来提高他们的安全性和消除偏见。由于神经网络固有的复杂性,它们缺乏可解释性,但未来,当这种网络经常用于驾驶汽车和引导机器人时,这将是必要的。
OpenAI的Chris Olah也参与了这个项目,他说:“感觉这有点像创造一个显微镜。至少,这就是我们所追求的目标。”
你可以在这个网站浏览下图所示的激活地图集的交互式版本:distill.pub/activation-atlas/

激活地图集让研究人员将视觉数据算法用于理解世界
激活神经元
要了解激活地图集和其他功能可视化工具的工作原理,首先需要了解一下AI系统如何识别对象。
实现这一目标的基本方法是使用神经网络:一种与人类大脑大致相似的计算结构(虽然它在复杂性方面落后了数年)。在每个神经网络内部是像网状物一样连接的人造神经元层。像大脑中的细胞一样,这些细胞会响应刺激,这一过程称为激活。重要的是,它们不仅可以开启或关闭,它们在光谱上登记,为每次激活赋予特定值或权重。
要将神经网络变为有用的东西,必须提供大量的训练数据。在视觉算法的情况下,这将意味着数十万甚至数百万的图像,每个图像都标记有特定的类别。在谷歌和OpenAI的研究人员为这项工作测试的神经网络的情况下,这些类别是广泛的:从羊毛到温莎领带,从安全带到太空加热器。

神经网络使用多层相连的人工神经元来处理数据。不同的神经元对图像的不同部分做出反应
当它提供这些数据时,神经网络中的不同神经元会响应每个图像而亮起。此模式连接到图像的标签,这种关联允许网络学习事物的样子。一旦经过训练,你就可以向网络显示以前从未见过的图片,并且神经元将激活,将输入与特定类别相匹配。
如果所有这些听起来都令人不安,那就是因为,在很多方面,它都是如此。像许多机器学习程序一样,视觉算法本质上只是模式匹配机器。这给了它们一定的优势(例如,只要你拥有必要的数据和计算能力,就可以直接进行训练)。但这也带来了某些弱点(它们很容易被之前从未见过的输入混淆)。
由于研究人员在2010年初发现了神经网络在视觉任务方面的潜力,他们一直在试图弄清楚它们是如何做到的。
早期的一项实验是DeepDream,这是2015年发布的计算机视觉计划,将任何图片变成了自身的幻觉版本。DeepDream的视觉效果肯定是有趣的(在某些方面,它们成为了AI的美学定义),但该程序也是一个像算法一样的早期尝试。从某些层面上讲,这一切都始于DeepDream。
后来的研究采用了同样的基本方法并对其进行了微调:首先针对网络中的单个神经元,看看是什么激发了它们,然后是神经元群,然后是网络不同层中神经元的组合。如果早期的实验是专也而非偶然的,就像牛顿用钝针在眼睛里捅自己来理解视力一样,最近的工作就已经类似于他用棱镜对准一缕光线——即更有针对性。通过绘制神经网络的每个部分中激活的视觉元素,一次又一次,最终,你得到地图集:它的大脑的视觉索引。

放大和缩小激活图集
机器视图
但激活地图集究竟向我们展示了算法的内部工作原理是什么呢?你可以从这里的谷歌和OpenAI的例子开始,它是用来解开著名的神经网络GoogLeNet或InceptionV1的内部结构的。
滚动屏幕,可以看到网络的不同部分如何响应不同的概念,以及这些概念是如何聚集在一起的。比如,狗在一个地方,鸟在另一个地方。你还可以看到网络的不同层如何表示不同类型的信息。较低的层次更抽象,对基本的几何形状做出响应,而较高的层次则将它们分解成可识别的概念。
当你深入研究个别分类时,这真的很有趣。谷歌和OpenAI给出的一个例子是“浮潜者”和“水肺潜水员”类别之间的区别。
在下图中,可以看到神经网络用于识别这些标签的各种激活。左边是与“浮潜者”密切相关的激活,右边是与“水肺潜水员”密切相关的激活。中间的激活是在两个类之间共享,而条纹上的那些是更多差异化。
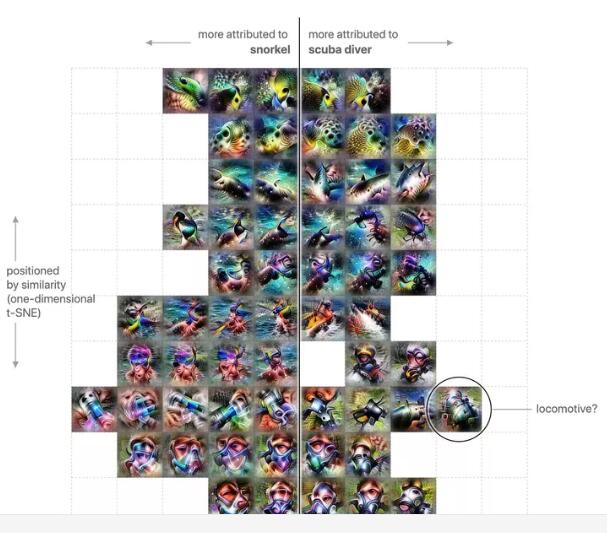
与“浮潜者”(左)和“水肺潜水员”(右)相关的激活
一目了然,你可以看出一些明显的颜色和图案。在顶部,看起来像鲜艳的鱼的斑点和条纹,而在底部,有看起来像面具的形状。但右侧突出显示的是一种不寻常的激活,一种与机车密切相关的激活。当研究人员发现这一点时,他们感到困惑。为什么这些关于机车的视觉信息对识别戴水肺的潜水员很重要?
Carter表示,“所以我们测试了它,如果我们放一张蒸汽机车的图片,它会把分类从浮潜者转换为水肺潜水员?结果确实如此。”
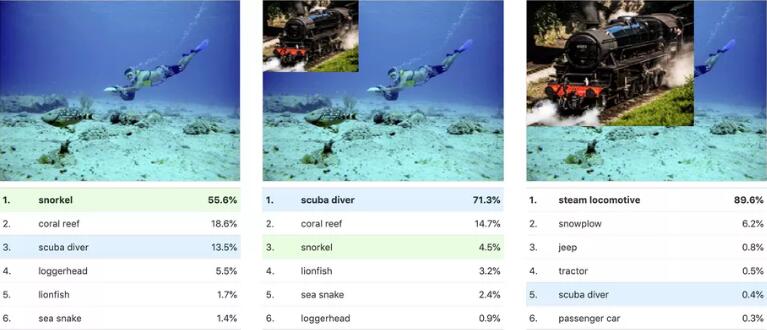
三个图像显示如何重新分类相同的图片。在左边,它被确定为浮潜者;在中间,随着机车的增加,它变成了水肺潜水员;当机车足够大时,它将接管整个分类。
团队最终找到了原因:这是因为机车的光滑金属曲线在视觉上类似于潜水员的空气罐。因此,对于神经网络来说,这是浮潜者和水肺潜水员之间的一个明显区别。为了节省区分这两个类别的时间,它只是从其他地方借用了所需的识别视觉数据。
这种例子神奇地揭示了神经网络的运作方式。对于怀疑论者,它显示了这些系统的局限性。他们说,视觉算法可能是有效的,但他们学到的信息实际上与人类如何理解世界无关。这使他们容易受到某些诡计的影响。例如,如果你只将一些精心挑选的像素投射到图像中,则可能足以使算法对其进行错误分类。
但对于研究者来说,激活地图集和类似工具所揭示的信息显示了这些算法的惊人的深度和灵活性。例如,Carter指出,为了使算法区分浮潜者和水肺潜水员,它还将不同类型的动物与每个类别联系起来。
“在深水中生活的动物,比如海龟,是通过水肺呼吸的;而在水面生活的动物,比如鸟类,是通过呼吸管呼吸的。”他指出,这是系统从来没有直接去学习的信息。相反,它只是自己找到了它。这就像是对世界更深层次的理解。
Olah表示同意,“我发现在高分辨率下透过这些地图集看起来几乎令人敬畏,只看到这些网络可以代表的巨大空间。”
他们希望通过开发这样的工具,将有助于推动AI的整个领域。通过了解机器视觉系统如何看待世界,理论上我们可以更有效地构建它们并更彻底地检查它们的准确性。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消