











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Python机器学习的练习三:逻辑回归
2018年06月01日 由 xiaoshan.xiang 发表
413246
0
Python机器学习的练习系列共有八个部分:
Python机器学习的练习一:简单线性回归
Python机器学习的练习二:多元线性回归
Python机器学习的练习三:逻辑回归
Python机器学习的练习四:多元逻辑回归
Python机器学习的练习五:神经网络
Python机器学习的练习六:支持向量机
Python机器学习的练习七:K-Means聚类和主成分分析
Python机器学习的练习八:异常检测和推荐系统
在这篇Python机器学习的练习中,我们将把我们的目标从预测连续值(回归)变成分类两个或更多的离散的储存器(分类),并将其应用到学生入学问题上。假设你是一个大学的管理人员,你想要根据两门考试的结果来确定每个申请人的录取机会。你可以把以前申请人的历史资料作为训练集使用。对于每一个训练例子,你有申请人的两门考试成绩和录取决定。为了达到这个目的,我们将根据考试成绩建立一个分类模型,使用一种叫逻辑回归的方法来估计录取的概率。
逻辑回归实际上是一种分类算法。我怀疑它这样命名是因为它与线性回归在学习方法上很相似,但是成本和梯度函数表述不同。特别是,逻辑回归使用了一个sigmoid或“logit”激活函数,而不是线性回归的连续输出。
首先导入和检查我们将要处理的数据集。
在数据中有两个连续的自变量——“Exam 1”和“Exam 2”。我们的预测目标是“Admitted”的标签。值1表示学生被录取,0表示学生没有被录取。我们看有两科成绩的散点图,并使用颜色编码来表达例子是positive或者negative。
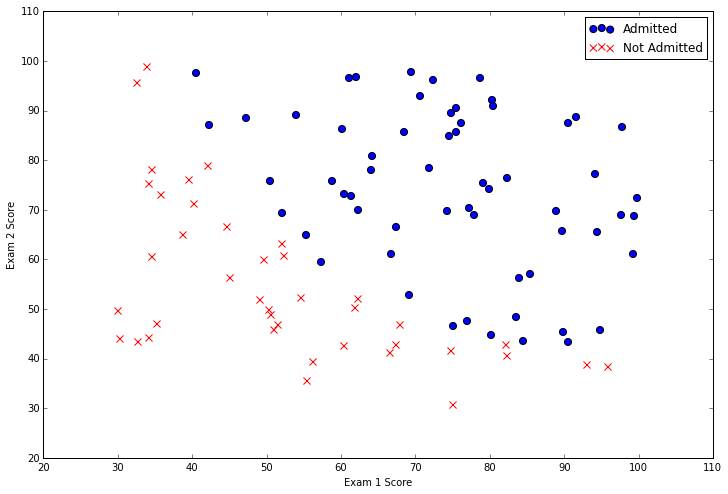
从这个图中我们可以看到,有一个近似线性的决策边界。它有一点弯曲,所以我们不能使用直线将所有的例子正确地分类,但我们能够很接近。现在我们需要实施逻辑回归,这样我们就可以训练一个模型来找到最优决策边界,并做出分类预测。首先需要实现sigmoid函数。
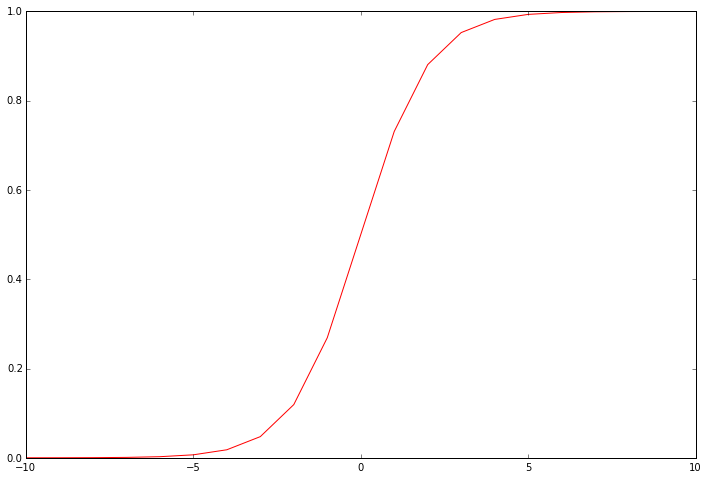
这个函数是逻辑回归输出的“激活”函数。它将连续输入转换为0到1之间的值。这个值可以被解释为分类概率,或者输入的例子应该被积极分类的可能性。利用带有界限值的概率,我们可以得到一个离散标签预测。它有助于可视化函数的输出,以了解它真正在做什么。
我们的下一步是写成本函数。成本函数在给定一组模型参数的训练数据上评估模型的性能。这是逻辑回归的成本函数。
注意,我们将输出减少到单个标量值,该值是“误差”之和,是模型分配的类概率与示例的真实标签之间差别的量化函数。该实现完全是向量化的——它在语句(sigmoid(X * theta.T))中计算模型对整个数据集的预测。
测试成本函数以确保它在运行,首先需要做一些设置。
检查数据结构的形状,以确保它们的值是合理的。这种技术在实现矩阵乘法时非常有用
((100L, 3L), (3L,), (100L, 1L))
现在计算初始解的成本,将模型参数“theta”设置为零,。
0.69314718055994529
我们已经有了工作成本函数,下一步是编写一个函数,用来计算模型参数的梯度,以找出改变参数来提高训练数据模型的方法。在梯度下降的情况下,我们不只是在参数值周围随机地jigger,看看什么效果最好。并且在每次迭代训练中,我们通过保证将其移动到减少训练误差(即“成本”)的方向来更新参数。我们可以这样做是因为成本函数是可微分的。这是函数。
我们并没有在这个函数中执行梯度下降——我们只计算一个梯度步骤。在练习中,使用“fminunc”的Octave函数优化给定函数的参数,以计算成本和梯度。因为我们使用的是Python,所以我们可以使用SciPy的优化API来做同样的事情。
0.20357134412164668
现在我们的数据集里有了最优模型参数,接下来我们要写一个函数,它使用我们训练过的参数theta来输出数据集X的预测,然后使用这个函数为我们分类器的训练精度打分。
accuracy = 89%
我们的逻辑回归分类器预测学生是否被录取的准确性可以达到89%,这是在训练集中的精度。我们没有保留一个hold-out set或使用交叉验证来获得准确的近似值,所以这个数字可能高于实际的值。
既然我们已经有了逻辑回归的工作实现,我们将通过添加正则化来改善算法。正则化是成本函数的一个条件,使算法倾向于更简单的模型(在这种情况下,模型会减小系数),原理就是帮助减少过度拟合和帮助模型提高通用化能力。我们使用逻辑回归的正则化版本去解决稍带挑战性的问题, 想象你是工厂的产品经理,你有一些芯片在两种不同测试上的测试结果。通过两种测试,你将会决定那种芯片被接受或者拒绝。为了帮助你做这个决定,你将会有以往芯片的测试结果数据集,并且通过它建立一个逻辑回归模型。
现在可视化数据。

这个数据看起来比以前的例子更复杂,你会注意到没有线性决策线,数据也执行的很好,处理这个问题的一种方法是使用像逻辑回归这样的线性技术,就是构造出由原始特征多项式派生出来的特征。我们可以尝试创建一堆多项式特性以提供给分类器。
现在我们需要去修改成本和梯度函数以包含正则项。在这种情况下,将正则化矩阵添加到之前的计算中。这是更新后的成本函数。
我们添加了一个名为“reg”的新变量,它是参数值的函数。随着参数越来越大,对成本函数的惩罚也越来越大。我们在函数中添加了一个新的“learning rate”参数。 这也是等式中正则项的一部分。 learning rate为我们提供了一个新的超参数,我们可以使用它来调整正则化在成本函数中的权重。
接下来,我们将在梯度函数中添加正则化。
与成本函数一样,将正则项加到最初的计算中。与成本函数不同的是,我们包含了确保第一个参数不被正则化的逻辑。这个决定背后的直觉是,第一个参数被认为是模型的“bias”或“intercept”,不应该被惩罚。
我们像以前那样测试新函数
0.6931471805599454
我们能使用先前的最优代码寻找最优模型参数。
(数组([ 0.35872309, -3.22200653, 18.97106363, -4.25297831, 18.23053189, 20.36386672, 8.94114455, -43.77439015, -17.93440473, -50.75071857, -2.84162964]), 110, 1)
最后,我们可以使用前面应用的相同方法,为训练数据创建标签预测,并评估模型的性能。
准确度 = 91%
Python机器学习的练习一:简单线性回归
Python机器学习的练习二:多元线性回归
Python机器学习的练习三:逻辑回归
Python机器学习的练习四:多元逻辑回归
Python机器学习的练习五:神经网络
Python机器学习的练习六:支持向量机
Python机器学习的练习七:K-Means聚类和主成分分析
Python机器学习的练习八:异常检测和推荐系统
在这篇Python机器学习的练习中,我们将把我们的目标从预测连续值(回归)变成分类两个或更多的离散的储存器(分类),并将其应用到学生入学问题上。假设你是一个大学的管理人员,你想要根据两门考试的结果来确定每个申请人的录取机会。你可以把以前申请人的历史资料作为训练集使用。对于每一个训练例子,你有申请人的两门考试成绩和录取决定。为了达到这个目的,我们将根据考试成绩建立一个分类模型,使用一种叫逻辑回归的方法来估计录取的概率。
逻辑回归
逻辑回归实际上是一种分类算法。我怀疑它这样命名是因为它与线性回归在学习方法上很相似,但是成本和梯度函数表述不同。特别是,逻辑回归使用了一个sigmoid或“logit”激活函数,而不是线性回归的连续输出。
首先导入和检查我们将要处理的数据集。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import os
path = os.getcwd() + '\data\ex2data1.txt'
data = pd.read_csv(path, header=None, names=['Exam 1', 'Exam 2', 'Admitted'])
data.head()
| Exam 1 | Exam 2 | Admitted | |
| 0 | 34.623660 | 78.024693 | 0 |
| 1 | 30.286711 | 43.894998 | 0 |
| 2 | 35.847409 | 72.902198 | 0 |
| 3 | 60.182599 | 86.308552 | 1 |
| 4 | 79.032736 | 75.344376 | 1 |
在数据中有两个连续的自变量——“Exam 1”和“Exam 2”。我们的预测目标是“Admitted”的标签。值1表示学生被录取,0表示学生没有被录取。我们看有两科成绩的散点图,并使用颜色编码来表达例子是positive或者negative。
positive = data[data['Admitted'].isin([1])]
negative = data[data['Admitted'].isin([0])]
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive['Exam 1'], positive['Exam 2'], s=50, c='b', marker='o', label='Admitted')
ax.scatter(negative['Exam 1'], negative['Exam 2'], s=50, c='r', marker='x', label='Not Admitted')
ax.legend()
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')
从这个图中我们可以看到,有一个近似线性的决策边界。它有一点弯曲,所以我们不能使用直线将所有的例子正确地分类,但我们能够很接近。现在我们需要实施逻辑回归,这样我们就可以训练一个模型来找到最优决策边界,并做出分类预测。首先需要实现sigmoid函数。
def sigmoid(z):
return 1 / (1 + np.exp(-z))
这个函数是逻辑回归输出的“激活”函数。它将连续输入转换为0到1之间的值。这个值可以被解释为分类概率,或者输入的例子应该被积极分类的可能性。利用带有界限值的概率,我们可以得到一个离散标签预测。它有助于可视化函数的输出,以了解它真正在做什么。
nums = np.arange(-10, 10, step=1)
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(nums, sigmoid(nums), 'r')
我们的下一步是写成本函数。成本函数在给定一组模型参数的训练数据上评估模型的性能。这是逻辑回归的成本函数。
def cost(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
return np.sum(first - second) / (len(X))
注意,我们将输出减少到单个标量值,该值是“误差”之和,是模型分配的类概率与示例的真实标签之间差别的量化函数。该实现完全是向量化的——它在语句(sigmoid(X * theta.T))中计算模型对整个数据集的预测。
测试成本函数以确保它在运行,首先需要做一些设置。
# add a ones column - this makes the matrix multiplication work out easier
data.insert(0, 'Ones', 1)
# set X (training data) and y (target variable)
cols = data.shape[1]
X = data.iloc[:,0:cols-1]
y = data.iloc[:,cols-1:cols]
# convert to numpy arrays and initalize the parameter array theta
X = np.array(X.values)
y = np.array(y.values)
theta = np.zeros(3)
检查数据结构的形状,以确保它们的值是合理的。这种技术在实现矩阵乘法时非常有用
X.shape, theta.shape, y.shape
((100L, 3L), (3L,), (100L, 1L))
现在计算初始解的成本,将模型参数“theta”设置为零,。
cost(theta, X, y)
0.69314718055994529
我们已经有了工作成本函数,下一步是编写一个函数,用来计算模型参数的梯度,以找出改变参数来提高训练数据模型的方法。在梯度下降的情况下,我们不只是在参数值周围随机地jigger,看看什么效果最好。并且在每次迭代训练中,我们通过保证将其移动到减少训练误差(即“成本”)的方向来更新参数。我们可以这样做是因为成本函数是可微分的。这是函数。
def gradient(theta, X, y):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
parameters = int(theta.ravel().shape[1])
grad = np.zeros(parameters)
error = sigmoid(X * theta.T) - y
for i in range(parameters):
term = np.multiply(error, X[:,i])
grad[i] = np.sum(term) / len(X)
return grad
我们并没有在这个函数中执行梯度下降——我们只计算一个梯度步骤。在练习中,使用“fminunc”的Octave函数优化给定函数的参数,以计算成本和梯度。因为我们使用的是Python,所以我们可以使用SciPy的优化API来做同样的事情。
import scipy.optimize as opt
result = opt.fmin_tnc(func=cost, x0=theta, fprime=gradient, args=(X, y))
cost(result[0], X, y)
0.20357134412164668
现在我们的数据集里有了最优模型参数,接下来我们要写一个函数,它使用我们训练过的参数theta来输出数据集X的预测,然后使用这个函数为我们分类器的训练精度打分。
def predict(theta, X):
probability = sigmoid(X * theta.T)
return [1 if x >= 0.5 else 0 for x in probability]
theta_min = np.matrix(result[0])
predictions = predict(theta_min, X)
correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y)]
accuracy = (sum(map(int, correct)) % len(correct))
print 'accuracy = {0}%'.format(accuracy)
accuracy = 89%
我们的逻辑回归分类器预测学生是否被录取的准确性可以达到89%,这是在训练集中的精度。我们没有保留一个hold-out set或使用交叉验证来获得准确的近似值,所以这个数字可能高于实际的值。
正则化逻辑回归
既然我们已经有了逻辑回归的工作实现,我们将通过添加正则化来改善算法。正则化是成本函数的一个条件,使算法倾向于更简单的模型(在这种情况下,模型会减小系数),原理就是帮助减少过度拟合和帮助模型提高通用化能力。我们使用逻辑回归的正则化版本去解决稍带挑战性的问题, 想象你是工厂的产品经理,你有一些芯片在两种不同测试上的测试结果。通过两种测试,你将会决定那种芯片被接受或者拒绝。为了帮助你做这个决定,你将会有以往芯片的测试结果数据集,并且通过它建立一个逻辑回归模型。
现在可视化数据。
path = os.getcwd() + '\data\ex2data2.txt'
data2 = pd.read_csv(path, header=None, names=['Test 1', 'Test 2', 'Accepted'])
positive = data2[data2['Accepted'].isin([1])]
negative = data2[data2['Accepted'].isin([0])]
fig, ax = plt.subplots(figsize=(12,8))
ax.scatter(positive['Test 1'], positive['Test 2'], s=50, c='b', marker='o', label='Accepted')
ax.scatter(negative['Test 1'], negative['Test 2'], s=50, c='r', marker='x', label='Rejected')
ax.legend()
ax.set_xlabel('Test 1 Score')
ax.set_ylabel('Test 2 Score')
这个数据看起来比以前的例子更复杂,你会注意到没有线性决策线,数据也执行的很好,处理这个问题的一种方法是使用像逻辑回归这样的线性技术,就是构造出由原始特征多项式派生出来的特征。我们可以尝试创建一堆多项式特性以提供给分类器。
degree = 5
x1 = data2['Test 1']
x2 = data2['Test 2']
data2.insert(3, 'Ones', 1)
for i in range(1, degree):
for j in range(0, i):
data2['F' + str(i) + str(j)] = np.power(x1, i-j) * np.power(x2, j)
data2.drop('Test 1', axis=1, inplace=True)
data2.drop('Test 2', axis=1, inplace=True)
data2.head()
| Accepted | Ones | F10 | F20 | F21 | F30 | F31 | F32 | |
| 0 | 1 | 1 | 0.051267 | 0.002628 | 0.035864 | 0.000135 | 0.001839 | 0.025089 |
| 1 | 1 | 1 | -0.092742 | 0.008601 | -0.063523 | -0.000798 | 0.005891 | -0.043509 |
| 2 | 1 | 1 | -0.213710 | 0.045672 | -0.147941 | -0.009761 | 0.031616 | -0.102412 |
| 3 | 1 | 1 | -0.375000 | 0.140625 | -0.188321 | -0.052734 | 0.070620 | -0.094573 |
| 4 | 1 | 1 | -0.513250 | 0.263426 | -0.238990 | -0.135203 | 0.122661 | -0.111283 |
现在我们需要去修改成本和梯度函数以包含正则项。在这种情况下,将正则化矩阵添加到之前的计算中。这是更新后的成本函数。
def costReg(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
reg = (learningRate / 2 * len(X)) * np.sum(np.power(theta[:,1:theta.shape[1]], 2))
return np.sum(first - second) / (len(X)) + reg
我们添加了一个名为“reg”的新变量,它是参数值的函数。随着参数越来越大,对成本函数的惩罚也越来越大。我们在函数中添加了一个新的“learning rate”参数。 这也是等式中正则项的一部分。 learning rate为我们提供了一个新的超参数,我们可以使用它来调整正则化在成本函数中的权重。
接下来,我们将在梯度函数中添加正则化。
def gradientReg(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
parameters = int(theta.ravel().shape[1])
grad = np.zeros(parameters)
error = sigmoid(X * theta.T) - y
for i in range(parameters):
term = np.multiply(error, X[:,i])
if (i == 0):
grad[i] = np.sum(term) / len(X)
else:
grad[i] = (np.sum(term) / len(X)) + ((learningRate / len(X)) * theta[:,i])
return grad
与成本函数一样,将正则项加到最初的计算中。与成本函数不同的是,我们包含了确保第一个参数不被正则化的逻辑。这个决定背后的直觉是,第一个参数被认为是模型的“bias”或“intercept”,不应该被惩罚。
我们像以前那样测试新函数
# set X and y (remember from above that we moved the label to column 0)
cols = data2.shape[1]
X2 = data2.iloc[:,1:cols]
y2 = data2.iloc[:,0:1]
# convert to numpy arrays and initalize the parameter array theta
X2 = np.array(X2.values)
y2 = np.array(y2.values)
theta2 = np.zeros(11)
learningRate = 1
costReg(theta2, X2, y2, learningRate)
0.6931471805599454
我们能使用先前的最优代码寻找最优模型参数。
result2 = opt.fmin_tnc(func=costReg, x0=theta2, fprime=gradientReg, args=(X2, y2, learningRate))
result2
(数组([ 0.35872309, -3.22200653, 18.97106363, -4.25297831, 18.23053189, 20.36386672, 8.94114455, -43.77439015, -17.93440473, -50.75071857, -2.84162964]), 110, 1)
最后,我们可以使用前面应用的相同方法,为训练数据创建标签预测,并评估模型的性能。
theta_min = np.matrix(result2[0])
predictions = predict(theta_min, X2)
correct = [1 if ((a == 1 and b == 1) or (a == 0 and b == 0)) else 0 for (a, b) in zip(predictions, y2)]
accuracy = (sum(map(int, correct)) % len(correct))
print 'accuracy = {0}%'.format(accuracy)
准确度 = 91%

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消