











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






自定义对象检测问题:使用TensorFlow追踪星球大战中的千年隼号宇宙飞船
2017年11月07日 由 yining 发表
839817
0

千年隼号宇宙飞船的检测
大多数的大型科技公司(如IBM,谷歌,微软,亚马逊)都有易于使用的视觉识别API。一些规模较小的公司也提供类似的产品,如Clarifai。但没有公司能够提供对象检测。
以下图片都使用Watson视觉识别默认分类器被作了相同的标记。第一张图,是先通过一个对象检测模型运行的。
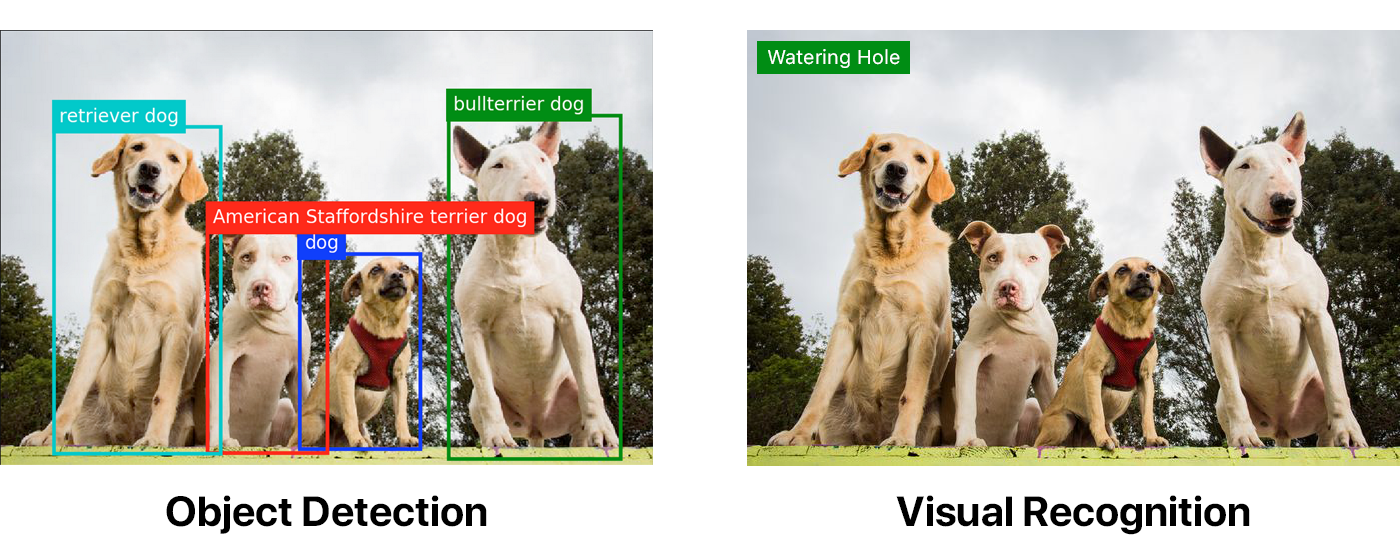
- Watson视觉识别默认分类器地址:https://www.ibm.com/watson/services/visual-recognition/
对象检测远远优于视觉识别。但如果你想要进行对象检测,你就得动手去操作。
根据你的用例,你可能不需要一个自定义对象检测模型。TensorFlow的对象检测API提供了几种不同速度和精度的模型,这些模型都是基于COCO数据集的。
- COCO数据集地址:http://cocodataset.org/#home
为了方便起见,我整理了一份可被COCO模型检测到的对象清单:
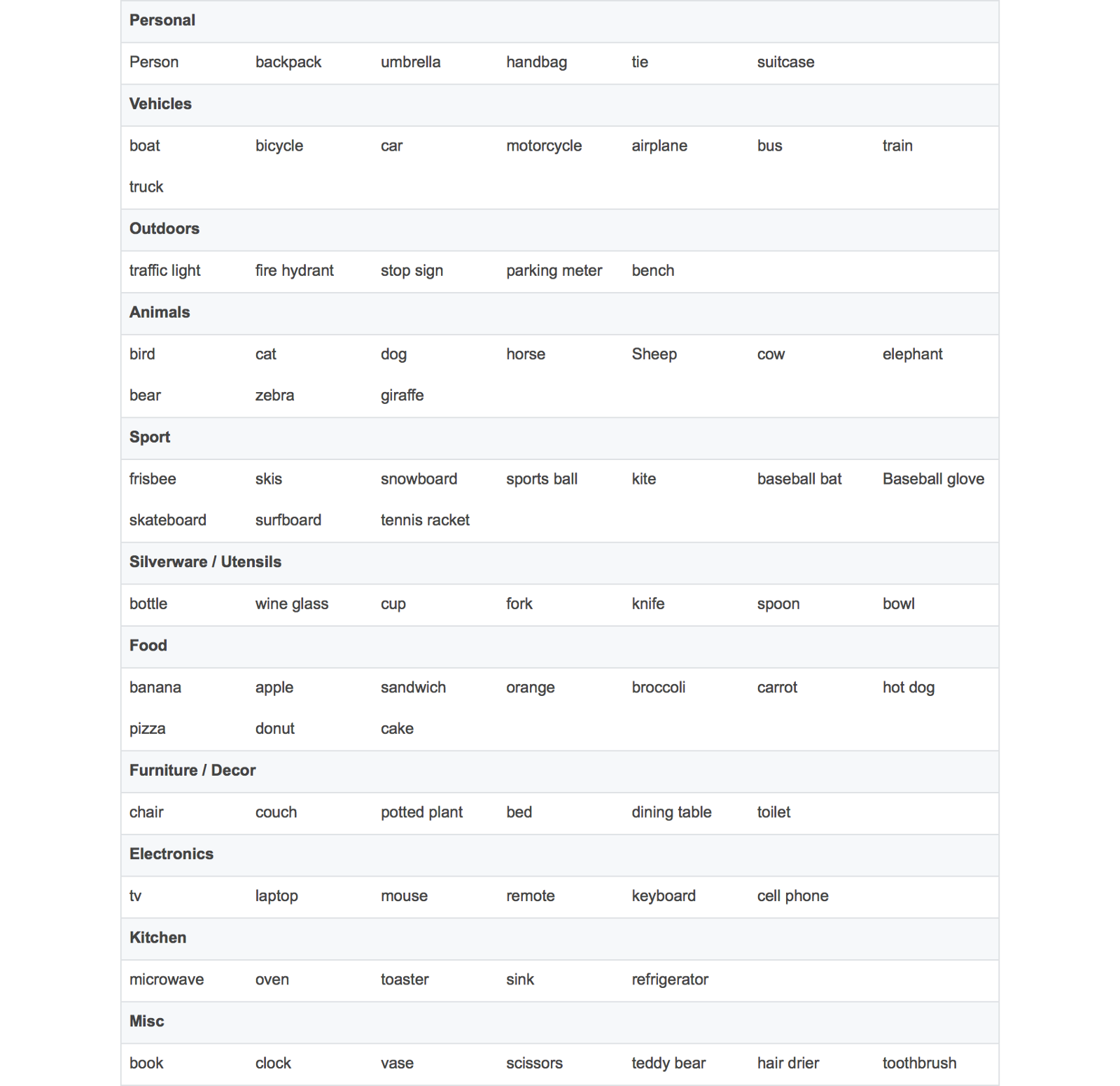
如果你想检测的对象不在这份名单上,那么你就必须构建你自己的自定义对象探测器。我希望能够检测到电影“星球大战”中的千年隼号宇宙飞船和一些TIE战斗机。这篇文章将会实现我的这一想法。
给图片注释
你需要收集很多图片和注释。注释包括指定对象的坐标和对应的标签。对于一张有两个TIE战斗机的图像,注释可能看起来像这样:
images
image1.jpg
1000
563
0
对于我的“星球大战”的模型,我收集了308张图片,每张图片包括两个或三个对象。我建议每个对象找200 - 300个例子。你可能会想,“哇,只通过几百张图片,我就能为每张图片写一堆XML(可扩展标记语言)吗?”
当然不是!现在的注释工具有很多,如labelImg和RectLabel。我用的是RectLabel,但它只适用于macOS系统。我花了大约3、4个小时的时间不间断地将我整个数据集做了注释。
当创建注释时,如果你不想写自己的转换脚本,那么确保它们以PASCAL VOC格式(这是我和许多其他人都在使用的格式)导出。
在运行脚本为TensorFlow准备数据之前,我们需要做一些设置。
本项目Repo地址:
目录结构:
modelsannotations
|--label_map.pbtxt
| |--|trainval.txt
|--| `1.xml
-- xmls
| |--|2.xml
|--|.xml
|-- 3...
| `--|--images| |--1.jpg| |--2.jpg| |-- 3.jpg| `--...|--object_detection| `--......
`--
我已经包含了我的训练数据,因此你需要立即运行它。但是如果你想用你自己的数据创建一个模型,你需要将你的训练图像添加到images中,添加你的XML注释到annotations/xmls中,更新trainval.txt和label_map.pbtxt。
trainval.txt是一个文件名的列表,它允许我们找到并且关联JPG和XML文件。下面的trainval.txt列表让我们可以找到
abc.jpg,abc.xml, 123.jpg, 123.xml, xyz.jpg 和 xyz.xml:abc
123
xyz
注意:确保你的JPG和XML文件名匹配,去掉后缀名。
label_map.pbtxt是我们我们要检测的对象列表,它看起来应该是这样的:
item {
id: 1
name: 'Millennium Falcon'
}item {
id: 2
name: 'Tie Fighter'
}运行脚本
首先,安装Python和pip,安装脚本要求:
pip install -r requirements.txt
将
models 和 models/slim 添加到你的PYTHONPATH:export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
- 重要提示:每次运行你必须打开终端,或添加到你的~/.bashrc文件中。
运行脚本:
python object_detection/create_tf_record.py
脚本运行完成后,你将以一个train.record和val.record文件告终,这两个文件将训练我们的模型。
下载一个基本模型
从头开始训练对象探测器需要耗费几天的时间,即使你使用了多个GPU。为了加快训练速度,我们将一个对象检测器训练在一个不同的数据集,并且重新使用它的一些参数来初始化我们的新模型。
你可以从model zoo下载一个模型。每个模型有不同精度和速度。我使用了faster_rcnn_resnet101_coco。
model zoo地址:https://github.com/bourdakos1/Custom-Object-Detection/blob/master/object_detection/g3doc/detection_model_zoo.md
提取并将所有model.ckpt文件移到我的Repo中的根目录。
你应该会看到一个名为faster_rcnn_resnet101.config的文件。它与faster_rcnn_resnet101_coco模型一起工作。如果你使用另一个模型,你可以在github里找到一个相应的配置文件。
Github地址:https://github.com/bourdakos1/Custom-Object-Detection/tree/master/object_detection/samples/configs
准备训练
运行以下脚本,它就可以开始训练了!
python object_detection/train.py \
--logtostderr \
--train_dir=train \
--pipeline_config_path=faster_rcnn_resnet101.config
注意:pipeline_config_path换成你的配置文件的位置。
global step 1:
global step 2:
global step 3:
global step 4:
...
很好,它开始工作了!
10分钟后...
global step 41:
global step 42:
global step 43:
global step 44:
...
再过一会儿
global step 71:
global step 72:
global step 73:
global step 74:
...
这个东西应该运行多长时间? 我使用MacBook Pro。如果你也在类似的计算机上运行的话,我假设你一个步长需要花费15秒左右的时间。按照这个速度需要大约三到四天的不间断运行才能得到一个合适的模型。
因此我们需要PowerAI的救援!
PowerAI地址:https://www.ibm.com/bs-en/marketplace/deep-learning-platform
PowerAI
PowerAI让我们在IBM Power Systems上使用P100 GPU快速地训练我们的模型!10000个步长只花了大约一个小时的训练时间。然而,这还只是用了一个GPU。在PowerAI的帮助下,IBM创造了一个新的图像识别的记录,花费7小时达到33.8%的准确率。它超过了以前的行业纪录-微软在10天内创造的29.9%的准确率。
创建一个Nimbix帐户
Nimbix为开发人员提供了一个试用帐户,他们在PowerAI平台上有十个小时的免费处理时间。
注册地址:https://www.nimbix.net/cognitive-journey/
注意:这个申请过程不是自动的,所以可能需要24个小时的审核时间。一旦批准,你应该会收到一封电子邮件和创建你的帐户的说明。
登录地址:https://mc.jarvice.com/
部署PowerAI Notebooks应用
首先搜索PowerAI Notebooks。
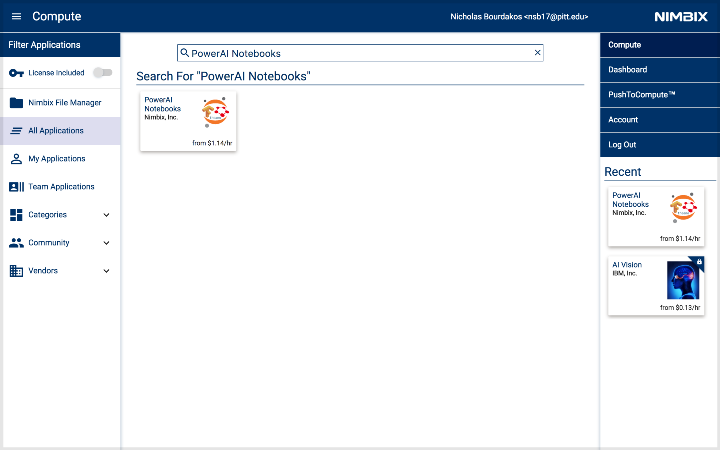
点击它,然后选择TensorFlow。
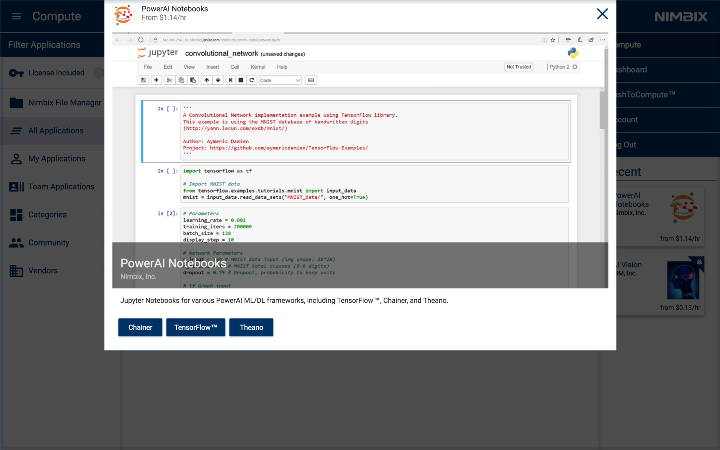
选择机器类型:32 thread POWER8, 128GB RAM, 1x P100 GPU w/NVLink (np8g1)。
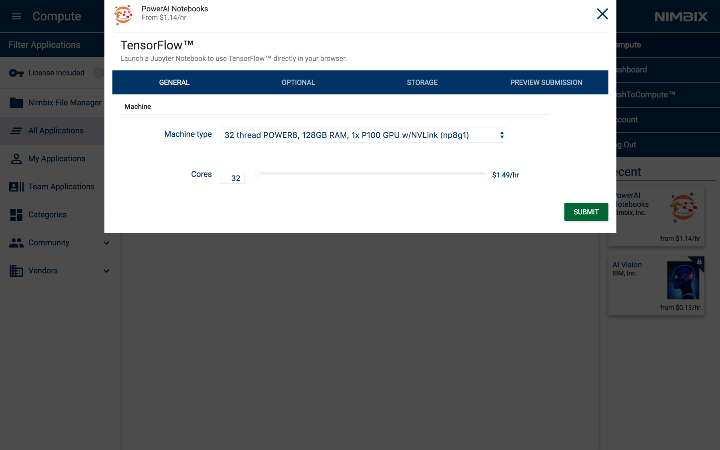
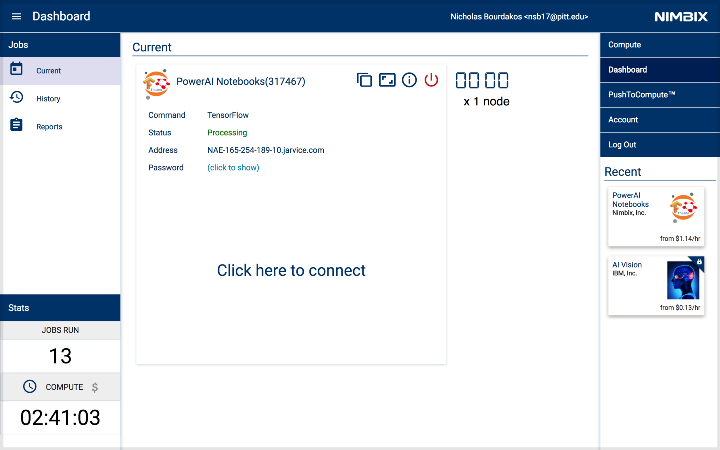
一旦启动,以下仪表盘面板将显示出来。当服务器状态转向处理(processing),服务器就可以访问。
通过点击(click to show)获取密码。
然后,点击Click here to connect连接启动Notebook。
 使用用户名nimbix和之前提供的密码登录。
使用用户名nimbix和之前提供的密码登录。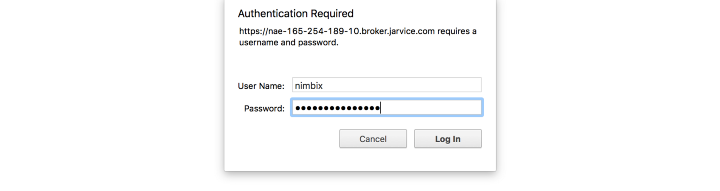
开始训练
通过点击New下拉并选择Terminal得到一个新的终端窗口。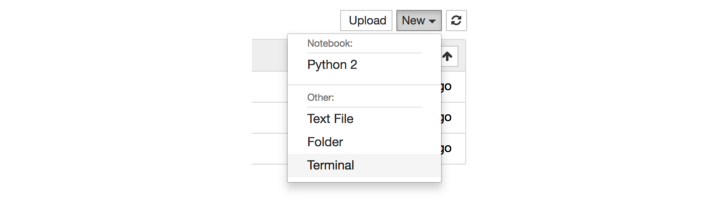
你会看到一个熟悉的内容:
注意:终端可能不能在Safari上工作。
当我们本地运行时,这个训练的步骤是一样的。如果你使用我的训练数据,那么你可以在通过复制下面这个repo运行:
git clone https://github.com/bourdakos1/Custom-Object-Detection.git
然后转换到根目录:
cd Custom-Object-Detection
运行这个snippet,下载我们之前下载过的预训练的faster_rcnn_resnet101_coco模型。
wget http://storage.googleapis.com/download.tensorflow.org/models/object_detection/faster_rcnn_resnet101_coco_11_06_2017.tar.gz
tar -xvf faster_rcnn_resnet101_coco_11_06_2017.tar.gz
mv faster_rcnn_resnet101_coco_11_06_2017/model.ckpt.* .
然后我们需要再次更新我们的PYTHONPATH,因为它在一个新的终端:
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
然后我们终于可以再次运行训练命令:
python object_detection/train.py \
--logtostderr \
--train_dir=train \
--pipeline_config_path=faster_rcnn_resnet101.config
下载你的模型
模型什么时候可以开始工作取决于你的训练数据。数据越多,你就需要更多的步长。我的模型需要近4500个步长。上限大约为20000个步长。
我建议每经过5000个步长就下载你的模型或者对它进行评估,以确保它能够正确地运行。
单击左上角的Jupyter标志。然后,找到文件树(file tree)Custom-Object-Detection/train。
下载所有带有最高的数字的model.ckpt文件。
model.ckpt-STEP_NUMBER.data-00000-of-00001model.ckpt-STEP_NUMBER.indexmodel.ckpt-STEP_NUMBER.meta
注意:你只能下载一次。
注意:完成时,一定要在你的机器上点击红色电源按钮。否则,计时将继续下去。
输出推理图(inference graph)
在我们的代码中使用模型时,我们需要将检查点文件(model.ckpt-STEP_NUMBER。*)转换成一个推理图。
推理图地址:http://deepdive.stanford.edu/inference
将刚才下载的检查点文件移动到你一直使用的repo里的根文件夹中。然后运行这个命令:
python object_detection/export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path faster_rcnn_resnet101.config \
--trained_checkpoint_prefix model.ckpt-STEP_NUMBER \
--output_directory output_inference_graph
记住export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
你应该看到了一个新的output_inference_graph目录和一个frozen_inference_graph.pb文件。这正是我们需要的文件。
测试模型
现在,运行以下命令:
python object_detection/object_detection_runner.py
在test_images目录并在output/test_images目录输出结果的所有图像中,它将在output_inference_graph/frozen_inference_graph.pb运行你的目标检测模型。
结果
观看视频:https://youtu.be/xW2hpkoaIiM

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消