











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






神经网络太臃肿?教你如何将神经网络减小四分之一
2017年11月12日 由 yuxiangyu 发表
156678
0
想要让深度神经网络更快,更节能一般有两种方法。一种方法是提出更好的神经网络设计。例如,MobileNet比VGG16小32倍,快10倍,但结果相同。另一种方法是,通过去除神经元之间不影响结果的连接,压缩现有的神经网络。本文将讨论如何实现第二种方法。
我们将让MobileNet-224缩小25%。换句话说,我们要在几乎不损失精度的情况下,将把它的参数从400万个减少到300万个。
由于MobileNet比VGG16小32倍,但具有相同的精度,所以它必须比VGG更有效地捕捉知识。
事实上,VGG为了完成工作,用到的连接比它实际需要用到的连接要多很多。论文(https://arxiv.org/abs/1510.00149)显示,通过修剪不重要的连接,VGG16的大小可以减少49倍,并且不影响结果。
那么,MobileNet是否有它不需要的连接?我们能不能把它变得更小?
当你压缩一个神经网络时,要找到网络大小与准确性的平衡点。一般来说,网络越小,运行速度越快(耗电也少),但预测的结果就越糟糕。MobileNet的分数比SqueezeNet好,但同时也是它的3.4倍。
理想情况下,我们希望找到能准确地表示我们想要学习的东西的尽可能小的神经网络。这是机器学习中的一个悬而未决的问题,除非有一个很好的理论能解决这个问题,否则我们将不得不从一个很大的网络开始,然后慢慢缩小它。
在这个项目中,我使用了带有Keras 2.0.7的预训练版MobileNet,并TensorFlow 1.0.3上运行。在ImageNet ILSVRC 2012验证集上评估模型,得分如下:
这意味着它一次猜出正确答案可能性为68.4%,而正确的答案在前五个最佳猜测中的概率为88.3%。我们希望压缩模型得到与它相当的准确度。
像大多数现代神经网络一样,MobileNet有许多卷积层。压缩卷积层的一种方法是将该层的权重从小到大排序,并丢弃具有最小权重的连接。上面提到的论文中也是使用这个方法,使VGG变小49倍。这听起来很不错,但它会造成稀疏连接。
由于GPU并不擅长处理稀疏矩阵,这种情况下缩小网络可能会让你花费更多时间。在这种情况下,更小并不一定意味着更快。
那么怎样做到小而快呢?我们不再向那样删除连接,而是删除完整的卷积过滤器。这样连接还很密集,GPU也更轻松。
回想一下,卷积层产生具有一定数量输出通道的图像。每个输出通道都包含一个卷积过滤器的结果。这样的过滤器在所有的输入通道上取加权和,并把这个加权和写入一个输出通道。
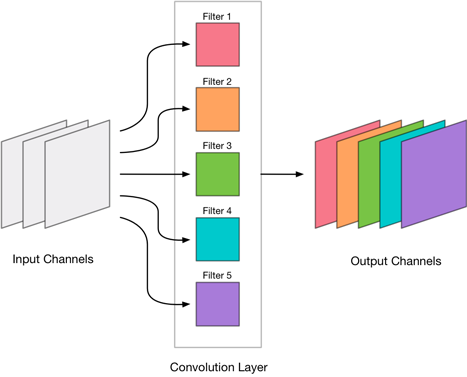
我们将找到最不重要的卷积过滤器,然后从层中移除它们的输出通道:
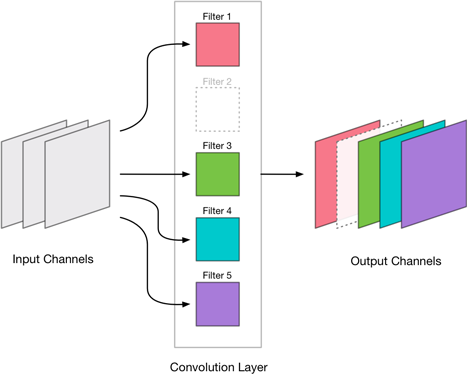
例如,MobileNet中的conv_pw_12 层有1024个输出通道。我们将丢弃其中的256个通道,这样conv_pw_12的压缩版本只有768个输出通道。
注意:为了让Metal流畅运行,我们应该每次都要去除四个输出通道。因为Metal实际上是个制图接口,它使用“texture”来描述图像数据,每个“texture”保存四个连续通道的数据。如果我们只删除一个输出通道,Metal仍然需要为其他三个通道处理“texture”。
那么我们删除了哪些过滤器或输出通道,不会影响最终结果呢。有很多不同的指标可以估量过滤器的相关性,这里我们使用一个非常简单的指标:过滤器权重的L1范数(过滤器权重的绝对值的总和)。
例如,这些是MobileNet第一个卷积层(32个过滤器)的L1范数,从低到高如下:
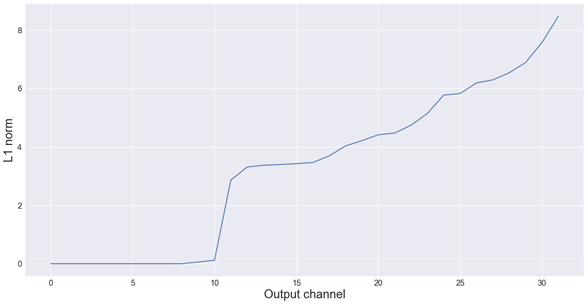
正如你所看到的,这个第一层中大约有10个过滤器的L1范数几乎为零。但因为我们的目标是在Metal上使用这个网络,所以删除10个过滤器是没有意义的。所以我们必须删除8或12个。
我首先尝试删除8个最小的过滤器,精度没有损失。 我决定放弃前12层。稍后你可以看到,精度也还不错。这样我们可以在网络中的第一个卷积层中去除37.5%的过滤器,神经网络没有变差。
这里是MobileNet中所有卷积层的L1范数图。你可以看到,许多层都有对网络没有太多贡献过滤器(很低的L1范数)。
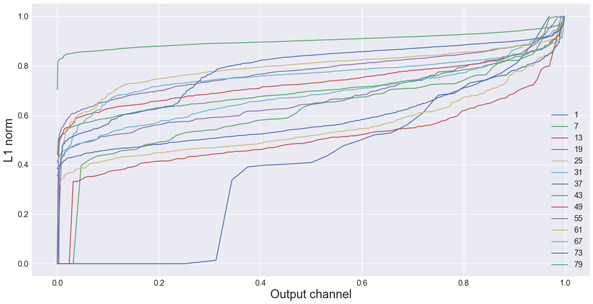
阅读更多关于这种方法内容访问:https://arxiv.org/abs/1608.08710
从层中删除过滤器意味着该层的输出通道数变小。这会对网络中的下一层产生影响,因为该层现在接收的输入通道也会变少。因此,我们也必须从该层删除相应的输入通道。当卷积被批量归一化时,我们也必须从批量归一化的参数中删除这些通道。
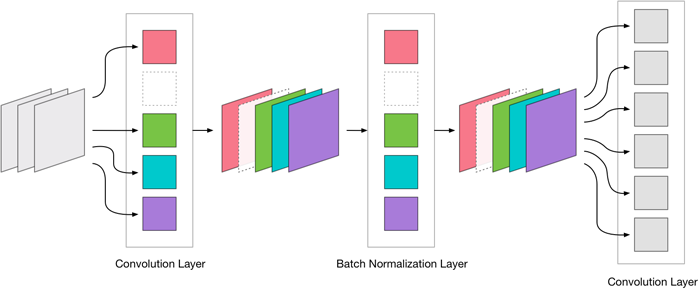
MobileNet实际上有三种卷积层:
我们只能从3×3和1×1的卷积中去除过滤器,而不能从深度卷积中去除。深度卷积必须具有与输入通道相同数量的输出通道。压缩没有太大的收获,而且深度卷积反应非常快(因为它们的工作量少于常规卷积)。所以我们主要关注3×3和1×1卷积层。
因为从层中删除过滤器会使网络的准确性变差。就算他们大都不重要,你也会丢掉神经网络学到的东西,所以你需要重新训练一下网络。它可以学习弥补你删除的部分。
这就意味着还要调用
这个过程是:
正如你所看到的,这个过程是相当繁琐的,因为我们每次只压缩一层,每次改变都需要重新训练网络。搞清楚每层下降多少过滤器准确率没有明显下降。
MobileNet在ILSVRC竞赛数据集上训练,也称为ImageNet。这是一个庞大的数据集,包含超过120万个训练图像。
我最近建立了一个深度学习平台(一个只有一个GTX 1080 Ti GPU的Linux机器)。在这台计算机上,需要2个小时完成一个训练周期。甚至评估网络在5万张图像验证集上的效果也需要3分钟。
这个速度太慢了。所以,我决定使用样本。我没有使用完整的训练集,而是从1000个类别中挑选了5个随机图像(这样样本有一定代表性),总共可以提供5000个训练图像。现在需要大约30秒来完成一个训练周期。这比2小时更容易管理!
为了进行验证,我从完整的验证集中选取了1,000个图像的一个随机子集。在这个子集上对网络进行评估只需要3秒钟。
事实证明,使用样本的实践效果不错。
像上面看到的一样,第一个卷积层有10个过滤器的L1范数小到接近0。我们需要删除4的倍数的过滤器,最后我删除了12最小的L1范数的过滤器。
最初,我没有从神经网络中删除过滤器,只是将它们的连接权重设置为0。理论上,这样做和删除是一样的。这使Top1的精确度从69.4%下降到68.7% 。精确度稍低了一些,但只有一点再训练可以修正。这算是个良好的开端!
接下来,我创建了一个除了在这里我删除过滤器的以外,与原来的层相同的新模型,所以第一个卷积层有24个输出通道,而不是原来的36个。但是现在验证成绩更差只有29.9%。那么,发生了什么?
理论上,将连接的权重设置为0应该与删除连接具有相同的效果。但我搞砸了:我忘记也把下一层的相应输入通道的权重设置为0.并且,由于下一层是深度卷积,所以我还必须设置相应的参数让该层的批量归一化为0。
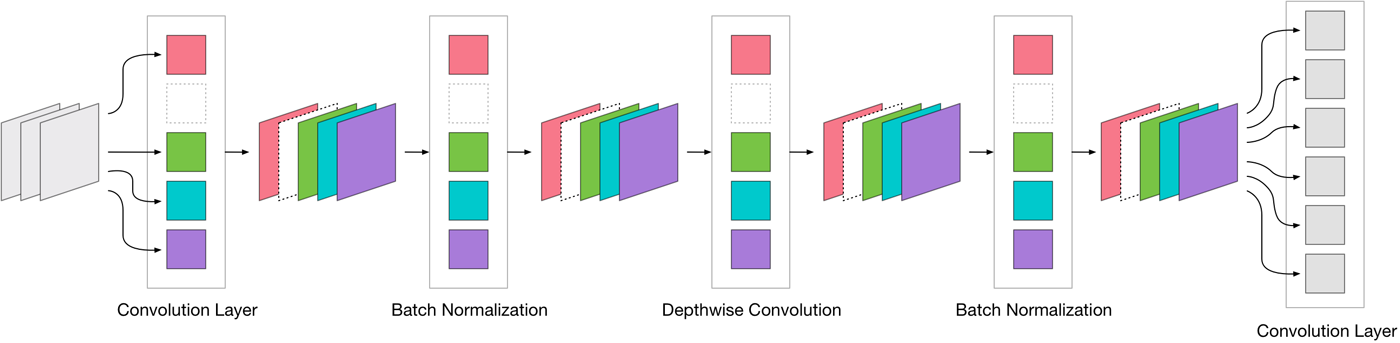
这样我们知道了,从一个层移除过滤器也会对接下来的几个层产生重大影响。而对其他层的更改也会影响验证分数。
那么删除第一个卷积层过滤器的37.5%到底可不可行?通过检查模型,我发现这里所有的“错误”来自在第二个批量归一化层中的12个偏置值,因为除了那些偏置的值之外,其他的值都是零。
而这12个数字让准确度从68.7%下降到29.9%。但是,在具有400万参数的神经网络中,这12个数字根本不重要。这样,我相信网络可以通过一些再训练从29.9%中恢复过来。
我在样本数据集(5,000张图像)重新训练了神经网络,10个训练周期,现在验证得分回升到了68.4%。虽然比原来的准确度(69.4%)低些,但现在已经足够接近了。
对于这个项目,如果对一个样本进行再训练使精度回到65%左右,我就很满意了。因为,我们重新训练的样本仅为全套训练集大小的0.4%。我认为,如果这样一小部分训练图像可以使精度几乎回到原来的分数,那么在最后加入完整数据集训练几轮就可以了。
注意:相同的训练样本不要使用太久,会导致过拟合,一般我训练十次就更新训练样本。
现在,从第一个卷积层节省37.5%的权重。听起来很多,但这是一个非常小的层次。它只有3个输入通道和32个输出通道(现在24个)。总节约:3×3×3×12 = 324个参数,相比总数算是九牛一毛。
在压缩第一层之后,我认为在分类层之前尝试压缩最后一个卷积层是会很不错。
(在 MobileNet的Keras版中,分类层也恰好是一个卷积层,但是我们不能从中删除输出通道,因为这个网络是在ImageNet中训练的,该数据集有1000个种类,因此分类层也必须有1000个输出通道。如果我们要删除这些输出通道,模型就不能再对这些类别做出预测了。)
conv_pw_13层有1024个输出通道。我决定删除其中的256个。conv_pw_13有1,048,576个参数。这是网络中最大的一层,所以我们可以在这里压缩效果最好。
这一层的L1规范如下所示:
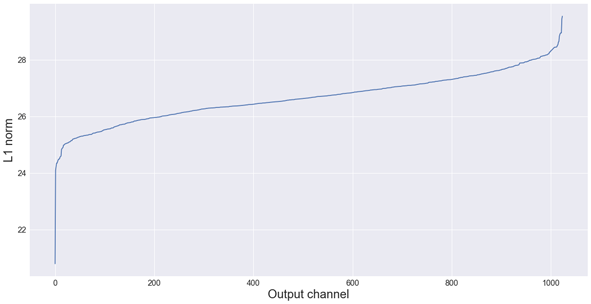
从图中我们可以看到,去掉256个通道有点多似乎有点多,但我们先不管它。
同样,我们从层中删除输出通道并批量归一化他们,然后调整下一层,以使它们也具有更少的输入通道。
删除这256个通道不仅可以在conv_pw_13上节省1024×1×1×256 = 262,144个参数,还可以从分类层中删除256,000个参数。
在压缩conv_pw_13层之后,验证分数下降到60.7%(top1)和82.9%(top5)。经过10次训练后,精度达到了63.6%,在新的训练样本上再训练十次,准确率达到了65.0%(top1)和86.1%(top5)。
这个得分不错,可以继续修剪其它层了。虽然还没有恢复到原来的以前的成绩,但它表明,网络已经成功补偿了被删除的连接。
接下来,我使用相同的方法修剪conv_pw_10(从512个过滤器中删除了32个)和conv_pw_12(从1024个中删除了256个)。
随着每一个新的层中,我注意到,再训练变得越来越难以使精度回到以前的标准。conv_pw_10是64.2%,conv_pw_12只有63.4%。
每次我使用不同的训练样本,只是为了确保结果模型不会过拟合。在逐点层10和12之后,我做了conv_pw_11。在做压缩的图层的选择时,我只是随意地选择的。
在conv_pw_11上,我删除了512个过滤器中的96个。对于其它的层,我大都删除了25%的过滤器,一般根据L1范数删除,主要由于它很好约整数。然而在这里,删除128个过滤器导致精度下降太多,再训练不能达到60%以上。“删除96个过滤器的效果会好点,但再训练后的得分也只有61.5%。
看到这些令人失望的验证分数,我觉得肯定是我删除了太多的过滤器,所以现在神经网络不再有能力学习ImageNet了。
到目前为止,所有的再训练都是用5000个图像的样本完成的,因此修剪后的网络只在整个训练集的一小部分上被重新训练。我决定是时候对网络进行完整的训练。
经过1个训练周期,精度回升至66.4(top1),0.87(top5)。我没有使用数据增强,只用原始的训练图像。在训练第二次后,为67.2(top1),87.7(top5)。
我在完整的训练集又上训练了几次,用到了数据增强,还调小了学习率,可惜没有什么效果。
由于时间关系,到此我停止了实验。我确信如果我继续做还能压缩的更多。
以上是我的结果:网络变小了25%,但准确度差了点(当然绝对不会差到25%)。
我们的流程还有改进空间,在选择移除和压缩的顺序上我做的也不是很科学。但对于这个项目足够了,我只是想知道大致思路。
显然,我没有对这个网络进行最佳修剪。使用L1范数也可能不是确定过滤器重要性的最好方法,也许一次只移除一些过滤器比一次删除层的输出通道的四分之一要好。
关于这件事是否值得我想说:如果神经网络小25% - 假设这意味着它也会快25% ,如果在手机上运行这可能非常关键,所以这是值得的。
我们将让MobileNet-224缩小25%。换句话说,我们要在几乎不损失精度的情况下,将把它的参数从400万个减少到300万个。
如何能做到这点
由于MobileNet比VGG16小32倍,但具有相同的精度,所以它必须比VGG更有效地捕捉知识。
事实上,VGG为了完成工作,用到的连接比它实际需要用到的连接要多很多。论文(https://arxiv.org/abs/1510.00149)显示,通过修剪不重要的连接,VGG16的大小可以减少49倍,并且不影响结果。
那么,MobileNet是否有它不需要的连接?我们能不能把它变得更小?
当你压缩一个神经网络时,要找到网络大小与准确性的平衡点。一般来说,网络越小,运行速度越快(耗电也少),但预测的结果就越糟糕。MobileNet的分数比SqueezeNet好,但同时也是它的3.4倍。
理想情况下,我们希望找到能准确地表示我们想要学习的东西的尽可能小的神经网络。这是机器学习中的一个悬而未决的问题,除非有一个很好的理论能解决这个问题,否则我们将不得不从一个很大的网络开始,然后慢慢缩小它。
在这个项目中,我使用了带有Keras 2.0.7的预训练版MobileNet,并TensorFlow 1.0.3上运行。在ImageNet ILSVRC 2012验证集上评估模型,得分如下:
Top-1 accuracy over 50000 images = 68.4%
Top-5 accuracy over 50000 images = 88.3%
这意味着它一次猜出正确答案可能性为68.4%,而正确的答案在前五个最佳猜测中的概率为88.3%。我们希望压缩模型得到与它相当的准确度。
如何压缩卷积神经网络
像大多数现代神经网络一样,MobileNet有许多卷积层。压缩卷积层的一种方法是将该层的权重从小到大排序,并丢弃具有最小权重的连接。上面提到的论文中也是使用这个方法,使VGG变小49倍。这听起来很不错,但它会造成稀疏连接。
由于GPU并不擅长处理稀疏矩阵,这种情况下缩小网络可能会让你花费更多时间。在这种情况下,更小并不一定意味着更快。
那么怎样做到小而快呢?我们不再向那样删除连接,而是删除完整的卷积过滤器。这样连接还很密集,GPU也更轻松。
回想一下,卷积层产生具有一定数量输出通道的图像。每个输出通道都包含一个卷积过滤器的结果。这样的过滤器在所有的输入通道上取加权和,并把这个加权和写入一个输出通道。
我们将找到最不重要的卷积过滤器,然后从层中移除它们的输出通道:
例如,MobileNet中的conv_pw_12 层有1024个输出通道。我们将丢弃其中的256个通道,这样conv_pw_12的压缩版本只有768个输出通道。
注意:为了让Metal流畅运行,我们应该每次都要去除四个输出通道。因为Metal实际上是个制图接口,它使用“texture”来描述图像数据,每个“texture”保存四个连续通道的数据。如果我们只删除一个输出通道,Metal仍然需要为其他三个通道处理“texture”。
那么我们删除了哪些过滤器或输出通道,不会影响最终结果呢。有很多不同的指标可以估量过滤器的相关性,这里我们使用一个非常简单的指标:过滤器权重的L1范数(过滤器权重的绝对值的总和)。
例如,这些是MobileNet第一个卷积层(32个过滤器)的L1范数,从低到高如下:
正如你所看到的,这个第一层中大约有10个过滤器的L1范数几乎为零。但因为我们的目标是在Metal上使用这个网络,所以删除10个过滤器是没有意义的。所以我们必须删除8或12个。
我首先尝试删除8个最小的过滤器,精度没有损失。 我决定放弃前12层。稍后你可以看到,精度也还不错。这样我们可以在网络中的第一个卷积层中去除37.5%的过滤器,神经网络没有变差。
这里是MobileNet中所有卷积层的L1范数图。你可以看到,许多层都有对网络没有太多贡献过滤器(很低的L1范数)。
阅读更多关于这种方法内容访问:https://arxiv.org/abs/1608.08710
从层中删除过滤器意味着该层的输出通道数变小。这会对网络中的下一层产生影响,因为该层现在接收的输入通道也会变少。因此,我们也必须从该层删除相应的输入通道。当卷积被批量归一化时,我们也必须从批量归一化的参数中删除这些通道。
MobileNet实际上有三种卷积层:
- 3×3卷积(第一层)
- 深度卷积
- 1×1的卷积(也称为逐点卷积)
我们只能从3×3和1×1的卷积中去除过滤器,而不能从深度卷积中去除。深度卷积必须具有与输入通道相同数量的输出通道。压缩没有太大的收获,而且深度卷积反应非常快(因为它们的工作量少于常规卷积)。所以我们主要关注3×3和1×1卷积层。
再训练
因为从层中删除过滤器会使网络的准确性变差。就算他们大都不重要,你也会丢掉神经网络学到的东西,所以你需要重新训练一下网络。它可以学习弥补你删除的部分。
这就意味着还要调用
model.fit()。一点点的试错让我的学习率达到了0.00001,这个数相当小,但是更大的变化会让训练失去了控制。学习率必须这么低的原因是,网络大部分已经被训练好了,我们只想做一些微小的改变来调整结果。这个过程是:
- 从层中以4的倍数删除过滤器(即输出通道)
- 重新训练网络几次
- 在验证集上评估网络是否恢复了以前的准确性
- 移到下一层并重复这些步骤
正如你所看到的,这个过程是相当繁琐的,因为我们每次只压缩一层,每次改变都需要重新训练网络。搞清楚每层下降多少过滤器准确率没有明显下降。
使用样本数据集
MobileNet在ILSVRC竞赛数据集上训练,也称为ImageNet。这是一个庞大的数据集,包含超过120万个训练图像。
我最近建立了一个深度学习平台(一个只有一个GTX 1080 Ti GPU的Linux机器)。在这台计算机上,需要2个小时完成一个训练周期。甚至评估网络在5万张图像验证集上的效果也需要3分钟。
这个速度太慢了。所以,我决定使用样本。我没有使用完整的训练集,而是从1000个类别中挑选了5个随机图像(这样样本有一定代表性),总共可以提供5000个训练图像。现在需要大约30秒来完成一个训练周期。这比2小时更容易管理!
为了进行验证,我从完整的验证集中选取了1,000个图像的一个随机子集。在这个子集上对网络进行评估只需要3秒钟。
事实证明,使用样本的实践效果不错。
压缩第一个卷积层
像上面看到的一样,第一个卷积层有10个过滤器的L1范数小到接近0。我们需要删除4的倍数的过滤器,最后我删除了12最小的L1范数的过滤器。
最初,我没有从神经网络中删除过滤器,只是将它们的连接权重设置为0。理论上,这样做和删除是一样的。这使Top1的精确度从69.4%下降到68.7% 。精确度稍低了一些,但只有一点再训练可以修正。这算是个良好的开端!
接下来,我创建了一个除了在这里我删除过滤器的以外,与原来的层相同的新模型,所以第一个卷积层有24个输出通道,而不是原来的36个。但是现在验证成绩更差只有29.9%。那么,发生了什么?
理论上,将连接的权重设置为0应该与删除连接具有相同的效果。但我搞砸了:我忘记也把下一层的相应输入通道的权重设置为0.并且,由于下一层是深度卷积,所以我还必须设置相应的参数让该层的批量归一化为0。
这样我们知道了,从一个层移除过滤器也会对接下来的几个层产生重大影响。而对其他层的更改也会影响验证分数。
那么删除第一个卷积层过滤器的37.5%到底可不可行?通过检查模型,我发现这里所有的“错误”来自在第二个批量归一化层中的12个偏置值,因为除了那些偏置的值之外,其他的值都是零。
而这12个数字让准确度从68.7%下降到29.9%。但是,在具有400万参数的神经网络中,这12个数字根本不重要。这样,我相信网络可以通过一些再训练从29.9%中恢复过来。
我在样本数据集(5,000张图像)重新训练了神经网络,10个训练周期,现在验证得分回升到了68.4%。虽然比原来的准确度(69.4%)低些,但现在已经足够接近了。
对于这个项目,如果对一个样本进行再训练使精度回到65%左右,我就很满意了。因为,我们重新训练的样本仅为全套训练集大小的0.4%。我认为,如果这样一小部分训练图像可以使精度几乎回到原来的分数,那么在最后加入完整数据集训练几轮就可以了。
注意:相同的训练样本不要使用太久,会导致过拟合,一般我训练十次就更新训练样本。
现在,从第一个卷积层节省37.5%的权重。听起来很多,但这是一个非常小的层次。它只有3个输入通道和32个输出通道(现在24个)。总节约:3×3×3×12 = 324个参数,相比总数算是九牛一毛。
压缩最后的卷积层
在压缩第一层之后,我认为在分类层之前尝试压缩最后一个卷积层是会很不错。
(在 MobileNet的Keras版中,分类层也恰好是一个卷积层,但是我们不能从中删除输出通道,因为这个网络是在ImageNet中训练的,该数据集有1000个种类,因此分类层也必须有1000个输出通道。如果我们要删除这些输出通道,模型就不能再对这些类别做出预测了。)
conv_pw_13层有1024个输出通道。我决定删除其中的256个。conv_pw_13有1,048,576个参数。这是网络中最大的一层,所以我们可以在这里压缩效果最好。
这一层的L1规范如下所示:
从图中我们可以看到,去掉256个通道有点多似乎有点多,但我们先不管它。
同样,我们从层中删除输出通道并批量归一化他们,然后调整下一层,以使它们也具有更少的输入通道。
删除这256个通道不仅可以在conv_pw_13上节省1024×1×1×256 = 262,144个参数,还可以从分类层中删除256,000个参数。
在压缩conv_pw_13层之后,验证分数下降到60.7%(top1)和82.9%(top5)。经过10次训练后,精度达到了63.6%,在新的训练样本上再训练十次,准确率达到了65.0%(top1)和86.1%(top5)。
这个得分不错,可以继续修剪其它层了。虽然还没有恢复到原来的以前的成绩,但它表明,网络已经成功补偿了被删除的连接。
压缩更多的层和再训练
接下来,我使用相同的方法修剪conv_pw_10(从512个过滤器中删除了32个)和conv_pw_12(从1024个中删除了256个)。
随着每一个新的层中,我注意到,再训练变得越来越难以使精度回到以前的标准。conv_pw_10是64.2%,conv_pw_12只有63.4%。
每次我使用不同的训练样本,只是为了确保结果模型不会过拟合。在逐点层10和12之后,我做了conv_pw_11。在做压缩的图层的选择时,我只是随意地选择的。
在conv_pw_11上,我删除了512个过滤器中的96个。对于其它的层,我大都删除了25%的过滤器,一般根据L1范数删除,主要由于它很好约整数。然而在这里,删除128个过滤器导致精度下降太多,再训练不能达到60%以上。“删除96个过滤器的效果会好点,但再训练后的得分也只有61.5%。
看到这些令人失望的验证分数,我觉得肯定是我删除了太多的过滤器,所以现在神经网络不再有能力学习ImageNet了。
到目前为止,所有的再训练都是用5000个图像的样本完成的,因此修剪后的网络只在整个训练集的一小部分上被重新训练。我决定是时候对网络进行完整的训练。
经过1个训练周期,精度回升至66.4(top1),0.87(top5)。我没有使用数据增强,只用原始的训练图像。在训练第二次后,为67.2(top1),87.7(top5)。
我在完整的训练集又上训练了几次,用到了数据增强,还调小了学习率,可惜没有什么效果。
由于时间关系,到此我停止了实验。我确信如果我继续做还能压缩的更多。
结论
Original network size: 4,253,864 parameters
Compressed network size: 3,210,232 parameters
Compressed to: 75.5% of original size
Top-1 accuracy over 50000 images = 67.2%
Top-5 accuracy over 50000 images = 87.7%
以上是我的结果:网络变小了25%,但准确度差了点(当然绝对不会差到25%)。
我们的流程还有改进空间,在选择移除和压缩的顺序上我做的也不是很科学。但对于这个项目足够了,我只是想知道大致思路。
显然,我没有对这个网络进行最佳修剪。使用L1范数也可能不是确定过滤器重要性的最好方法,也许一次只移除一些过滤器比一次删除层的输出通道的四分之一要好。
关于这件事是否值得我想说:如果神经网络小25% - 假设这意味着它也会快25% ,如果在手机上运行这可能非常关键,所以这是值得的。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消