











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






了解生成式对抗网络:如何伪造名人的脸
2017年11月13日 由 yuxiangyu 发表
910969
0
生成式对抗网络(GAN)的概念由Ian Goodfellow提出。Goodfellow使用了艺术评论家和艺术家的比喻来描述这两个模型比喻发生器和鉴别,它们组成了生成式对抗网络GAN。一个艺术评论家(鉴别器)试图判断图像是不是伪造的。一个想愚弄艺术评论家的艺术家(生成器)试图创造一个看起来尽可能真实的伪造的形象。他们“相互斗争”;鉴别器使用生成器的输出作为训练数据,而生成器则从鉴别器中得到反馈。在这个过程中,每个模型都变得更加强大。通过这种方式,生成式对抗网络GAN能够根据一些已知的输入数据生成新的复杂数据,我们今天讨论的就是图像。
实现生成式对抗网络GAN并不像听起来那么难。在本教程中,我们将使用TensorFlow来构建一个能够生成人脸图像的生成式对抗网络GAN。
在本教程中,我们并不是试图模拟简单的数值数据,我们试图模拟一个甚至可以愚弄人类的图像。生成器将随机生成的噪声矢量作为输入数据,然后使用一种名为反卷积的技术将数据转换为图像。
鉴别器是一种经典的卷积神经网络,它将真实的和假的图像进行分类。
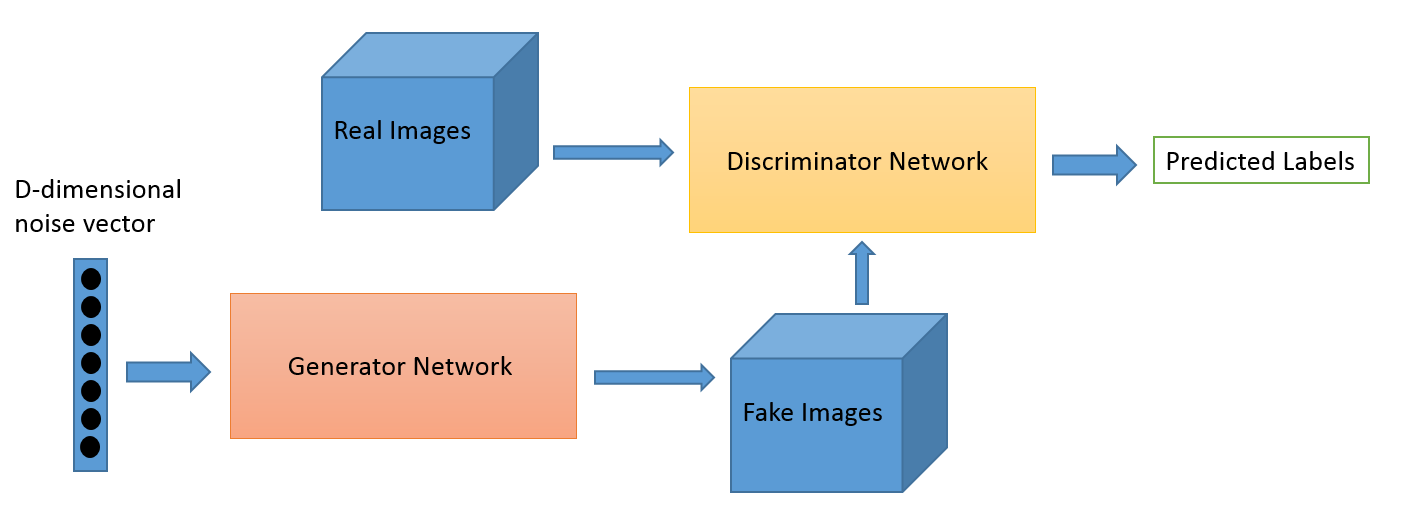
我们将使用论文“无监督表征学习的深卷积生成对抗网络”中原始的DCGAN架构,它由四个卷积层作为鉴别器,四个反卷积层作为发生器。
请访问https://github.com/dmonn/dcgan-oreilly。README文件中完整的说明。helper函数会自动下载CelebA数据集,让你快速启动和运行。请确保安装了matplotlib。如果不想自己安装,那么在存储库中就有一个Docker镜像。
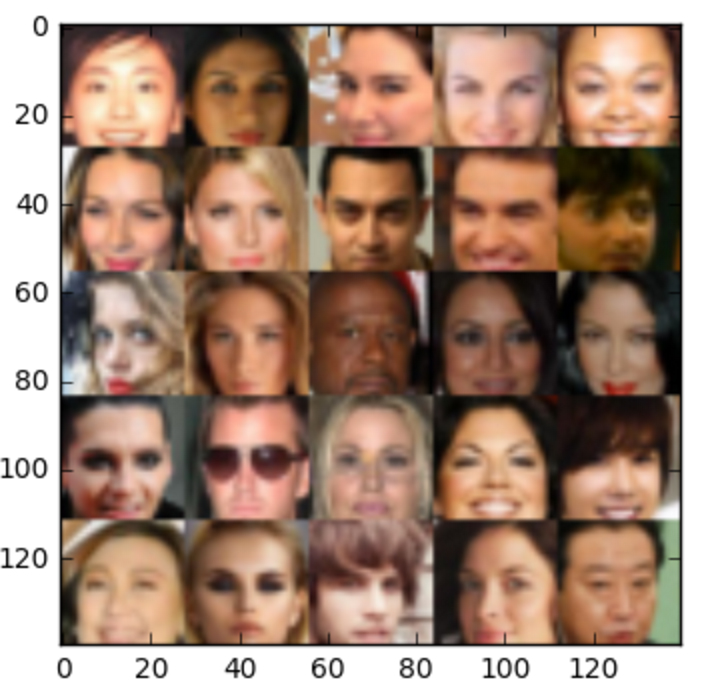
名人的属性数据集包含超过20万张名人图片,每一张都有40个属性注释。因为我们只想生成随机的人脸图像,所以忽略注释即可。数据集包含了10,000多个不同的身份,这对我们很有帮助。
在这一点上,我们还将定义一个用于批处理的函数。这个函数将加载我们的图像,并根据我们稍后设置的批处理大小给我们提供一系列图像。为了得到更好的结果,我们将会对图像进行裁剪,只有脸部才会显示。我们还将使图像归一化,让它们的像素值范围在-0.5到+0.5之间。最后,我们将把图像缩小到28x28。这样虽然我们损失了一些图像质量,但却大大减少了训练时间。
在我们开始定义我们的两个网络之前,我们先定义我们的输入。这样做是确保不让训练功能不会变得更乱。在这里,我们只是简单地为我们的真实和虚假输入定义TensorFlow占位符,以及学习率。
TensorFlow为占位符分配变量特别简便。完成这一操作之后,我们可以通过稍后指定一个馈送词典(feed dictionary)来使用我们网络中的占位符。
鉴别器相当于“艺术评论家”,试图区分真实和虚假的图像。简单地说,这是一个用于图像分类的卷积神经网络。如果你已经有了一些深度学习的经验,那么你有可能建立过与之相似网络。
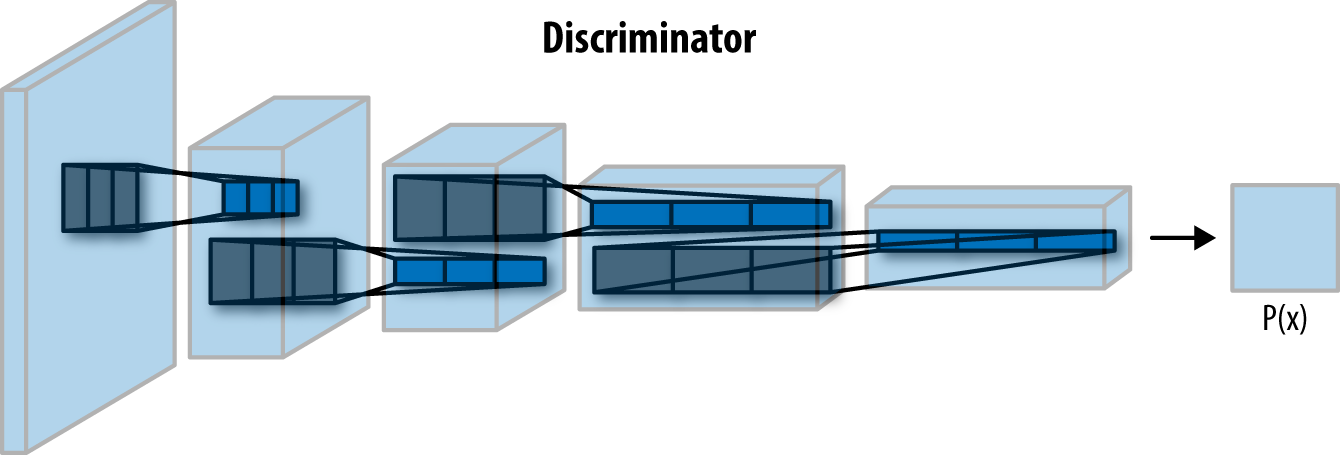
鉴别器网络由三个卷积层组成,与原始架构中的四个卷积层不同。我们删除最后一层来简化模型。这样训练进行得非常快,也不会损失太多的质量。网络的每一层,我们都要进行卷积,然后我们要进行批量归一化,使网络更快,更准确,最后我们要执行Leaky ReLu来进一步加速训练。最后,我们将最后一层的输出变平,并使用sigmoid激活函数来获得分类。不管图像真实与否,我们现在得到了一个预测结果。
发生器:试图欺骗鉴别者的是艺术家(造假画的人)。发生器利用反卷积层。它们与卷积图层完全相反:除了将图像转换为简单的数值数据(如分类)之外,我们执行反卷积以将数值数据转换为图像,而不是执行卷积。这不是像简单的卷积层那样的概念,它被用于更高级的地方。正如我们在鉴别器网络中所做的那样,我们也将其包含在一个可变范围内。
我们在这里做的和鉴别者一样,只是方向相反。首先,我们接受我们的输入(称为Z)并将其输入到第一个反卷积层。每个反卷积层执行反卷积,然后执行批量归一化和Leaky ReLu。然后,我们返回tanh激活函数。
在我们真正开始训练过程之前,我们还有要做的事情。首先,我们需要定义所有帮助我们计算损失的变量。其次,我们需要定义我们的优化函数。最后,我们将建立一个小的函数来输出生成的图像,接着训练网络。
我们需要定义三个损失函数:发生器的损失函数,使用真实图像时鉴别器的损失函数,以及使用假图像时鉴别器的损失函数。假图像和真实图像的损失总和应是整个鉴别器损失。
首先,我们定义我们对真实图像的损失函数。为此,我们在处理真实图像时要传递鉴别器的输出,并将其与所有1的标签进行比较(1代表真实)。我们在这里使用一种名为“label smoothing”的技术,它通过将0.9和1s相乘,来帮助我们的网络更加准确。
然后,我们为我们的假图像定义损失函数。这次我们在处理假的图像时将鉴别器的输出传递给我们的标签,这些标签都是0(这表示他们都是假的)。
最后,对于发生器的损失函数,我们的做法就像在最后一步一样,但是我们没有把输出与所有的0相比,而是用1s来比较,因为我们想要欺骗鉴别器。
在优化步骤中,我们正在寻找所有可以通过使用tf.trainable_variables函数进行训练的变量。既然我们之前使用了变量作用域,我们可以非常舒适地检索这些变量。然后我们使用Adam优化器为我们减少损失。
在我们准备的最后一步,我们正在编写一个小的函数,使用matplotlib库在笔记本电脑上显示生成的图像。
我们正在最后一步!现在,我们只获取我们之前定义的输入,损失和优化,调用一个TensorFlow会话并分批运行批处理。每400一批,我们通过显示生成的图像和生成器以及鉴别器的损失来输出当前的进度。现在身体向后靠,你会看到脸出现。根据你的设置,进度可能需要一个小时或更长的时间。
如果你顺利读完,那么恭喜你,你已经了解了生成式对抗网络GAN的用途,甚至知道如何使用它们生成人脸图像。你可能会问:“我将永远用不到生成随机面部的图像。”虽然这可能是真的,但是生成式对抗网络GAN还有很多其他的应用。
密歇根大学和德国马克斯普朗克研究所的研究人员使用生成式对抗网络GAN从文本生成图像。根据论文描述,他们能够产生非常逼真的花鸟。它还可以扩展到非常有用的其他领域,如模拟画像或平面设计。
伯克利的研究人员也设法创建了一个生成式对抗网络生成式对抗网络GAN,增强了模糊图像的清晰度,甚至重建了已损坏的图像数据。
生成式对抗网络GAN是非常强大的,谁知道 - 也许你会发明他们的下一个开创性的应用程序。
实现生成式对抗网络GAN并不像听起来那么难。在本教程中,我们将使用TensorFlow来构建一个能够生成人脸图像的生成式对抗网络GAN。
DCGAN架构
在本教程中,我们并不是试图模拟简单的数值数据,我们试图模拟一个甚至可以愚弄人类的图像。生成器将随机生成的噪声矢量作为输入数据,然后使用一种名为反卷积的技术将数据转换为图像。
鉴别器是一种经典的卷积神经网络,它将真实的和假的图像进行分类。
GAN结构的简单可视化
我们将使用论文“无监督表征学习的深卷积生成对抗网络”中原始的DCGAN架构,它由四个卷积层作为鉴别器,四个反卷积层作为发生器。
安装
请访问https://github.com/dmonn/dcgan-oreilly。README文件中完整的说明。helper函数会自动下载CelebA数据集,让你快速启动和运行。请确保安装了matplotlib。如果不想自己安装,那么在存储库中就有一个Docker镜像。
CelebA数据集
名人的属性数据集包含超过20万张名人图片,每一张都有40个属性注释。因为我们只想生成随机的人脸图像,所以忽略注释即可。数据集包含了10,000多个不同的身份,这对我们很有帮助。
数据集中部分名人的图像
在这一点上,我们还将定义一个用于批处理的函数。这个函数将加载我们的图像,并根据我们稍后设置的批处理大小给我们提供一系列图像。为了得到更好的结果,我们将会对图像进行裁剪,只有脸部才会显示。我们还将使图像归一化,让它们的像素值范围在-0.5到+0.5之间。最后,我们将把图像缩小到28x28。这样虽然我们损失了一些图像质量,但却大大减少了训练时间。
定义网络输入
在我们开始定义我们的两个网络之前,我们先定义我们的输入。这样做是确保不让训练功能不会变得更乱。在这里,我们只是简单地为我们的真实和虚假输入定义TensorFlow占位符,以及学习率。
def discriminator(images, reuse=False):
"""
Create the discriminator network
"""
with tf.variable_scope('discriminator', reuse=reuse):
# … the model
TensorFlow为占位符分配变量特别简便。完成这一操作之后,我们可以通过稍后指定一个馈送词典(feed dictionary)来使用我们网络中的占位符。
鉴别器网络
鉴别器相当于“艺术评论家”,试图区分真实和虚假的图像。简单地说,这是一个用于图像分类的卷积神经网络。如果你已经有了一些深度学习的经验,那么你有可能建立过与之相似网络。
鉴别器执行多重卷积。
定义这个网络时,我们要使用一个TensorFlow变量作用域。这有助于我们稍后的训练过程,所以我们可以重复使用我们鉴别器和发生器的变量名。
def discriminator(images, reuse=False):
"""
Create the discriminator network
"""
with tf.variable_scope('discriminator', reuse=reuse):
# … the model
鉴别器网络由三个卷积层组成,与原始架构中的四个卷积层不同。我们删除最后一层来简化模型。这样训练进行得非常快,也不会损失太多的质量。网络的每一层,我们都要进行卷积,然后我们要进行批量归一化,使网络更快,更准确,最后我们要执行Leaky ReLu来进一步加速训练。最后,我们将最后一层的输出变平,并使用sigmoid激活函数来获得分类。不管图像真实与否,我们现在得到了一个预测结果。
发生器网络
发生器:试图欺骗鉴别者的是艺术家(造假画的人)。发生器利用反卷积层。它们与卷积图层完全相反:除了将图像转换为简单的数值数据(如分类)之外,我们执行反卷积以将数值数据转换为图像,而不是执行卷积。这不是像简单的卷积层那样的概念,它被用于更高级的地方。正如我们在鉴别器网络中所做的那样,我们也将其包含在一个可变范围内。
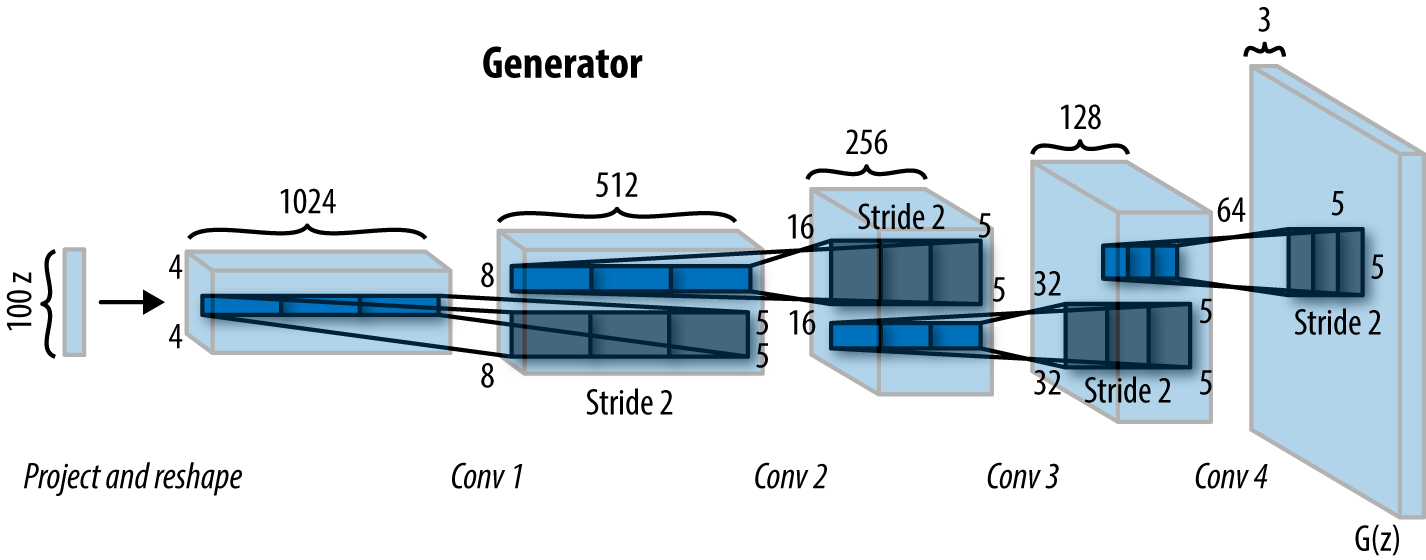
发生器执行多重反卷积
我们在这里做的和鉴别者一样,只是方向相反。首先,我们接受我们的输入(称为Z)并将其输入到第一个反卷积层。每个反卷积层执行反卷积,然后执行批量归一化和Leaky ReLu。然后,我们返回tanh激活函数。
开始训练
在我们真正开始训练过程之前,我们还有要做的事情。首先,我们需要定义所有帮助我们计算损失的变量。其次,我们需要定义我们的优化函数。最后,我们将建立一个小的函数来输出生成的图像,接着训练网络。
损失函数
我们需要定义三个损失函数:发生器的损失函数,使用真实图像时鉴别器的损失函数,以及使用假图像时鉴别器的损失函数。假图像和真实图像的损失总和应是整个鉴别器损失。
首先,我们定义我们对真实图像的损失函数。为此,我们在处理真实图像时要传递鉴别器的输出,并将其与所有1的标签进行比较(1代表真实)。我们在这里使用一种名为“label smoothing”的技术,它通过将0.9和1s相乘,来帮助我们的网络更加准确。
然后,我们为我们的假图像定义损失函数。这次我们在处理假的图像时将鉴别器的输出传递给我们的标签,这些标签都是0(这表示他们都是假的)。
最后,对于发生器的损失函数,我们的做法就像在最后一步一样,但是我们没有把输出与所有的0相比,而是用1s来比较,因为我们想要欺骗鉴别器。
优化和可视化
在优化步骤中,我们正在寻找所有可以通过使用tf.trainable_variables函数进行训练的变量。既然我们之前使用了变量作用域,我们可以非常舒适地检索这些变量。然后我们使用Adam优化器为我们减少损失。
def model_opt(d_loss, g_loss, learning_rate, beta1):
"""
Get optimization operations
"""
t_vars = tf.trainable_variables()
d_vars = [var for var in t_vars if var.name.startswith('discriminator')]
g_vars = [var for var in t_vars if var.name.startswith('generator')]
在我们准备的最后一步,我们正在编写一个小的函数,使用matplotlib库在笔记本电脑上显示生成的图像。
训练
我们正在最后一步!现在,我们只获取我们之前定义的输入,损失和优化,调用一个TensorFlow会话并分批运行批处理。每400一批,我们通过显示生成的图像和生成器以及鉴别器的损失来输出当前的进度。现在身体向后靠,你会看到脸出现。根据你的设置,进度可能需要一个小时或更长的时间。

生成的脸
结论
如果你顺利读完,那么恭喜你,你已经了解了生成式对抗网络GAN的用途,甚至知道如何使用它们生成人脸图像。你可能会问:“我将永远用不到生成随机面部的图像。”虽然这可能是真的,但是生成式对抗网络GAN还有很多其他的应用。
密歇根大学和德国马克斯普朗克研究所的研究人员使用生成式对抗网络GAN从文本生成图像。根据论文描述,他们能够产生非常逼真的花鸟。它还可以扩展到非常有用的其他领域,如模拟画像或平面设计。
伯克利的研究人员也设法创建了一个生成式对抗网络生成式对抗网络GAN,增强了模糊图像的清晰度,甚至重建了已损坏的图像数据。
生成式对抗网络GAN是非常强大的,谁知道 - 也许你会发明他们的下一个开创性的应用程序。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消