











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






省时又准确!创建一个数据科学工具在15分钟内完成关键字替换
2017年11月16日 由 xiaoshan.xiang 发表
855456
0
当开发人员使用文本时,他们通常需要先清理它。有时是通过替换关键字,比如用“Javascript”替换“JavaScript”。有些时候,我们只是想知道文档中是否提到了“JavaScript”。
像这样的数据清理任务是大多数处理文本的数据科学项目的标准。
我从事数据科学家的工作。自然语言处理是我工作的一部分。
当我在我们的文档语料库上训练一个Word2Vec模型时,它开始给出类似的同义词。“Javascripting”与“JavaScript”类似。
为了解决这个问题,我编写了一个正则表达式来替换所有已知的标准化名称的同义词。正则表达式用“JavaScript”取代了“Javascripting”,这解决了一个问题,但又产生了另一个问题。
上面的引用来自于这个stack- exchange问题,这对我来说是正确的。
stack- exchange问题地址:https://softwareengineering.stackexchange.com/questions/223634/what-is-meant-by-now-you-have-two-problems
事实证明,如果要搜索和替换的关键字数量在100内,正则表达式的速度很快。但我的语料库有超过20K的关键字和300万个文档。
当我对正则表达式代码进行基准测试时,我发现完成一次运行需要5天的时间。

自然的解决方案是并行运行。但当我们达到数以百万计的文档和数以万计的关键字时,这并没有什么帮助。必须有更好的办法!
我编写了自己的实现和FlashText。
FlashText地址:https://github.com/vi3k6i5/FlashText
在我们进入FlashText以及了解它如何工作之前,让我们来看看它是如何进行搜索的:
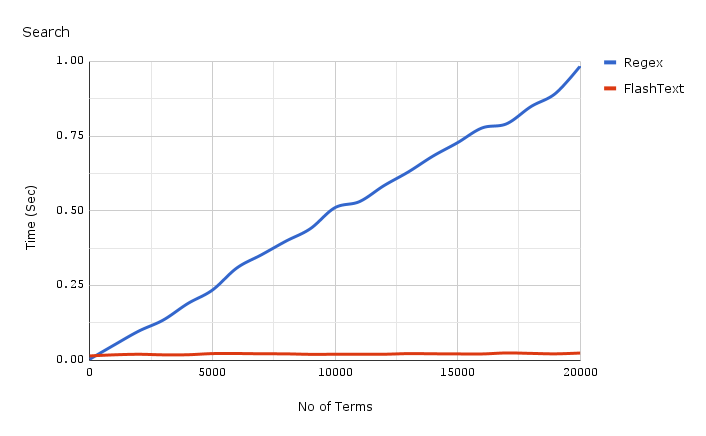
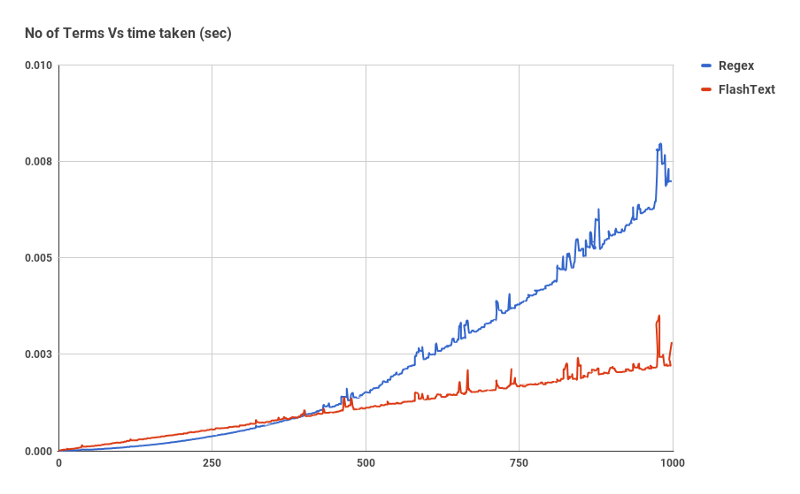
上面所示的图表是1份文档分别进行FlashText与执行正则表达式的结果比较。随着关键字数量的增加,正则表达式的时间几乎线性增长。但用FlashText时间并没有增加很多。

这是FlashText替换所需的时间:
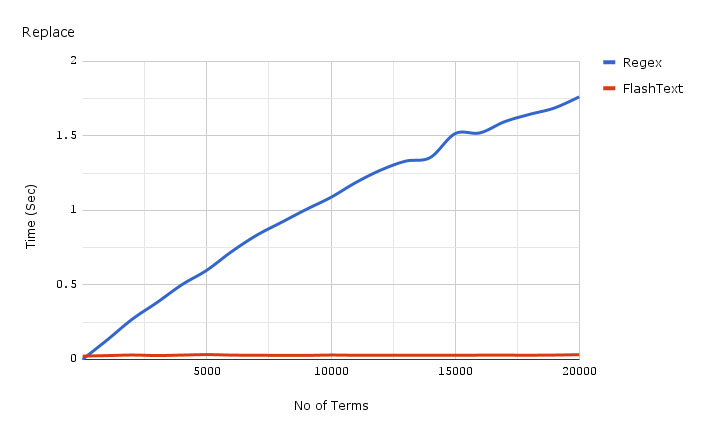
上面所示的基准代码链接地址:https://gist.github.com/vi3k6i5/dc3335ee46ab9f650b19885e8ade6c7a
结果链接地址:https://goo.gl/wWCyyw
FlashText是我在GitHub上开放源代码的一个Python库。它既能有效地提取关键字,又能替代它们。
要使用FlashText,首先必须通过一个关键字列表。这个列表将用于内部构建一个Trie字典。然后传递一个字符串,告诉它是否要执行替换或搜索。
对于替换,它将创建一个替换关键字的新字符串。对于搜索,它将返回在字符串中找到的关键字列表。这将发生在一个传递给输入字符串的过程中。
让我们试着用一个例子来理解这个部分。假设我们有一个句子,它有3个单词,
如果我们从语料中提取每个单词,并检查它是否在句子中,它会尝试4次。
如果语料库有n个单词,它就会有n个循环。每个搜索步骤都是
还有一种方法与第一个方法相反。对于句子中的每个单词,检查它是否存在于语料库中。
如果这个句子有m个单词,它就会有m个循环。在这种情况下,它所花费的时间只取决于句子中单词的数量。这一步,
FlashText算法基于第二种方法。它的灵感来自于aho - corasick算法和Trie数据结构。
它的工作方式是:
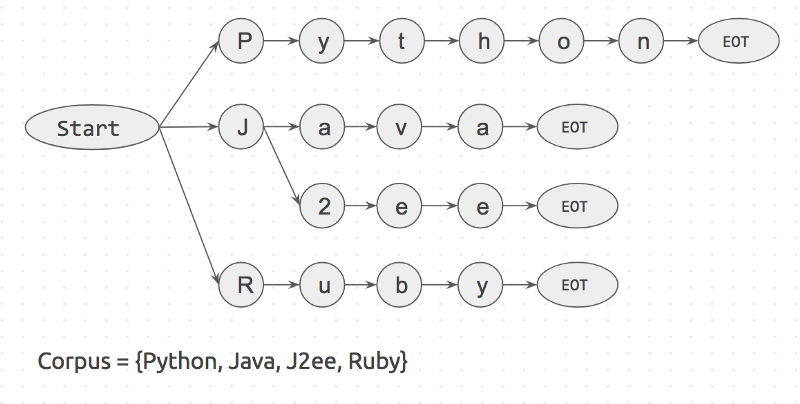
首先使用语料库创建了Trie字典。它看起来有点像下图:
Start和EOT(术语的末尾)表示单词边界,如
接下来,我们将使用一个输入字符串,
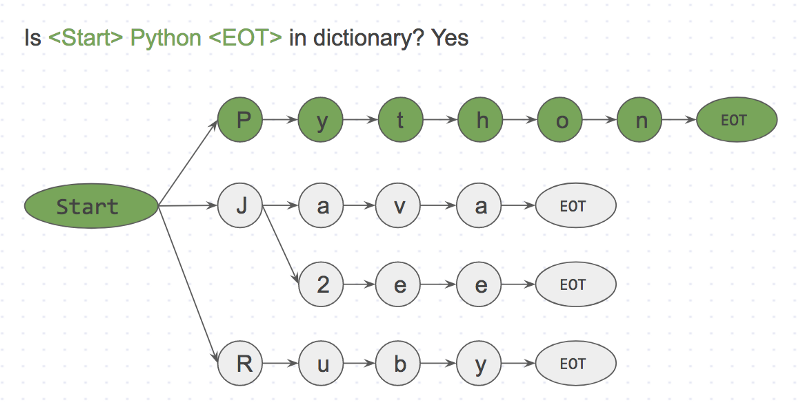
由于这是一个字符匹配的字符,我们可以轻松地跳过
FlashText算法只处理输入字符串“I like Python”的每个单词。这本字典有一百万个关键字,但对运行不产生影响。这就是FlashText算法的真正威力。
什么时候应该使用FlashText呢?
简单回答:当关键字数量大于500的时候
复杂的答案:正则表达式可以搜索基于特殊字符的关键字,如
因此,如果你想匹配
代替提取关键字,你也可以在句子中替换关键字。我们将此作为数据处理过程中的数据清理步骤。
如果你认识一个使用文本数据、实体识别、自然语言处理或Word2vec的人,请考虑与他们分享这篇文章。
像这样的数据清理任务是大多数处理文本的数据科学项目的标准。
数据科学从数据清理开始
我从事数据科学家的工作。自然语言处理是我工作的一部分。
当我在我们的文档语料库上训练一个Word2Vec模型时,它开始给出类似的同义词。“Javascripting”与“JavaScript”类似。
为了解决这个问题,我编写了一个正则表达式来替换所有已知的标准化名称的同义词。正则表达式用“JavaScript”取代了“Javascripting”,这解决了一个问题,但又产生了另一个问题。
有些人,当遇到问题时,会想“我知道,我将使用正则表达式。”现在他们有两个问题。
上面的引用来自于这个stack- exchange问题,这对我来说是正确的。
stack- exchange问题地址:https://softwareengineering.stackexchange.com/questions/223634/what-is-meant-by-now-you-have-two-problems
事实证明,如果要搜索和替换的关键字数量在100内,正则表达式的速度很快。但我的语料库有超过20K的关键字和300万个文档。
当我对正则表达式代码进行基准测试时,我发现完成一次运行需要5天的时间。
自然的解决方案是并行运行。但当我们达到数以百万计的文档和数以万计的关键字时,这并没有什么帮助。必须有更好的办法!
我编写了自己的实现和FlashText。
FlashText地址:https://github.com/vi3k6i5/FlashText
在我们进入FlashText以及了解它如何工作之前,让我们来看看它是如何进行搜索的:
最下面的红线是使用FlashText搜索需要的时间
上面所示的图表是1份文档分别进行FlashText与执行正则表达式的结果比较。随着关键字数量的增加,正则表达式的时间几乎线性增长。但用FlashText时间并没有增加很多。
FlashText将运行时间从5天减少到15分钟!
这是FlashText替换所需的时间:
最下面的红线是使用FlashText替换需要的时间
上面所示的基准代码链接地址:https://gist.github.com/vi3k6i5/dc3335ee46ab9f650b19885e8ade6c7a
结果链接地址:https://goo.gl/wWCyyw
FlashText是什么?
FlashText是我在GitHub上开放源代码的一个Python库。它既能有效地提取关键字,又能替代它们。
要使用FlashText,首先必须通过一个关键字列表。这个列表将用于内部构建一个Trie字典。然后传递一个字符串,告诉它是否要执行替换或搜索。
对于替换,它将创建一个替换关键字的新字符串。对于搜索,它将返回在字符串中找到的关键字列表。这将发生在一个传递给输入字符串的过程中。
为什么FlashText这么快?
让我们试着用一个例子来理解这个部分。假设我们有一个句子,它有3个单词,
I like Python, 和一个语料库,它有4个单词 {Python, Java, J2ee, Ruby}。如果我们从语料中提取每个单词,并检查它是否在句子中,它会尝试4次。
is 'Python' in sentence?
is 'Java' in sentence?
...
如果语料库有n个单词,它就会有n个循环。每个搜索步骤都是
is in sentence? 这是在正则式表达匹配中发生的情况。还有一种方法与第一个方法相反。对于句子中的每个单词,检查它是否存在于语料库中。
is 'I' in corpus?
is 'like' in corpus?
is 'python' in corpus?
如果这个句子有m个单词,它就会有m个循环。在这种情况下,它所花费的时间只取决于句子中单词的数量。这一步,
is in corpus? 可以使用字典查找快速进行。FlashText算法基于第二种方法。它的灵感来自于aho - corasick算法和Trie数据结构。
它的工作方式是:
首先使用语料库创建了Trie字典。它看起来有点像下图:
语料库的线索词典
Start和EOT(术语的末尾)表示单词边界,如
space, period和 new_line. 只有在它的两边有单词边界时,关键字才会匹配。接下来,我们将使用一个输入字符串,
I like Python ,并根据字符进行搜索。Step 1: isI in dictionary? No
Step 2: islike in dictionary? No
Step 3: isPython in dictionary? Yes
由于这是一个字符匹配的字符,我们可以轻松地跳过
l like l 没有连接 start。这使得跳过缺失的单词非常快。FlashText算法只处理输入字符串“I like Python”的每个单词。这本字典有一百万个关键字,但对运行不产生影响。这就是FlashText算法的真正威力。
什么时候应该使用FlashText呢?
简单回答:当关键字数量大于500的时候
在~500个关键词后,搜索FlashText开始优于正则表达式
复杂的答案:正则表达式可以搜索基于特殊字符的关键字,如
^,$,*,\d, FlashText中不支持这些关键字。因此,如果你想匹配
`word\dvec`. 这样的部分词,可能无法完成。但它很好地提取了像 `word2vec`.这样的完整单词。FlashText搜索关键词
# pip install flashtext
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
# ['New York', 'Bay Area']
FlashText的简单抽取示例
FlashText替换关键词
代替提取关键字,你也可以在句子中替换关键字。我们将此作为数据处理过程中的数据清理步骤。
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
# 'I love New York and NCR region.'
FlashText的简单替换示例
如果你认识一个使用文本数据、实体识别、自然语言处理或Word2vec的人,请考虑与他们分享这篇文章。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消