











结论
在使预测变得更准确和减少错误判断的数量上,还有很大的改进空间。接下来的步骤是了解更多关于配置文件中不同参数的信息,并更好地了解它们如何影响模型的训练及其预测。我们希望你现在能够为你自己的数据集训练对象检测器。

请先登录您的atyun账户,方可使用该功能
审核通过后即可使用此功能,请耐心等待~






圣诞老人是否真实存在?训练Tensorflow的对象检测API能够告诉你答案
2017年12月25日 由 yining 发表
801680
0
背景:最近我们看到了一篇文章,关于如何用于你自己的数据集,训练Tensorflow的对象检测API。这篇文章让我们对对象检测产生了关注,正巧圣诞节来临,我们打算用这种方法试着找到圣诞老人。
- 文章地址:https://medium.com/towards-data-science/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9
代码在下面的地址中。从这段代码中生成的模型可以扩展,以发现其他类别的角色是动画还是真实的。
- 地址:https://github.com/turnerlabs/character-finder

正在活动的圣诞老人🎅🏻
收集数据
与任何机器学习模型一样,数据是最重要的方面。因为我们想要找到不同类型的圣诞老人,我们的训练数据必须是多样化的。为了收集数据,我们编写了一个流处理器,它使用VLC(多媒体播放器)从任何在线资源流播放视频,并从中捕获帧。流处理器在视频中捕获帧,而不需要等待视频加载。如果当前播放的视频是2秒,那么流处理器将从4或5秒的标记中捕获帧。作为额外的奖励,你可以在ASCII观看视频,这是观看视频的最酷的方式。
- 流处理器的使用说明:https://github.com/turnerlabs/stream-processor

在ASCII上圣诞老人冲浪的视频
下面是我们收集的不同类型的圣诞老人照片的一小部分。所有这些图片都是从YouTube上收集的。正如你所看到的,有不同类型的动画版和真人版圣诞老人。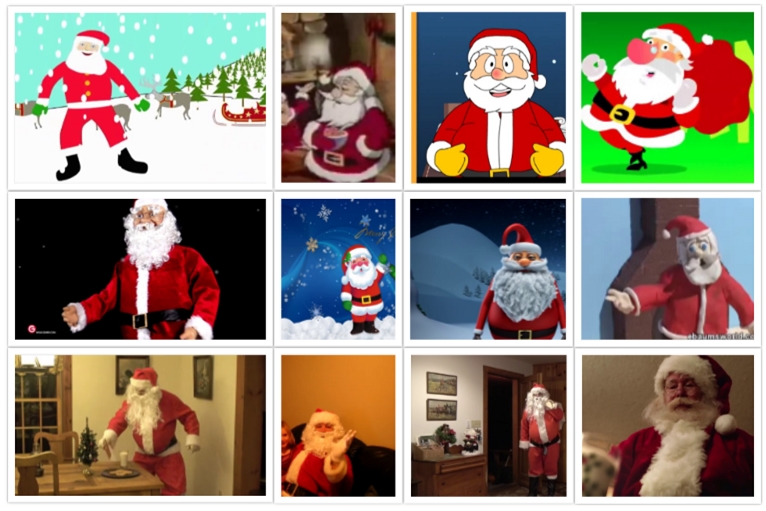
不同种类的圣诞老人
给数据贴标签
下一步是给数据贴上标签,比如在圣诞老人的脸上画一个边界框。图像标记的一个常见选择是使用工具贴标签,但是我们使用了“辛普森一家的角色识别和检测(第2部分)”这篇文章中出现的自定义脚本。
- 文章地址:https://medium.com/alex-attia-blog/the-simpsons-characters-recognition-and-detection-part-2-c44f9d5abf37
要给图像贴上标签,先点击人物面部的左上角,然后再点击右下角。如果图像中没有出现人物角色,双击相同的点并删除图像。
- 脚本的代码:https://github.com/turnerlabs/character-finder/blob/master/detect_labels.py

创建Tensorflow记录文件
一旦边界框信息存储在一个csv文件中,下一步就是将csv文件和图像转换为一个TF记录文件,这是Tensorflow的对象检测API使用的文件格式。将csv文件转换为TF记录的脚本可以在下面地址中找到。
地址:https://github.com/turnerlabs/character-finder/blob/master/object_detection/create_characters_tf_record.py
还需要一个protobuf(可扩展的序列化结构数据格式)文本文件,用于将标签名转换为数字id。对于我们的实例,它只是一个类。
item {
id: 1
Name: santa
}创建配置文件
对于训练,我们使用faster_rcnn_inception_resnet配置文件作为基础。我们将配置文件中的类参数更改为1,因为我们只有一个类——“圣诞老人(santa)”,并将输入路径参数更改指向我们在上一步中创建的TFrecord文件。我们使用了预先训练过的检查点用作faster_rcnn_inception_resnet配置文件。我们使用这个模型是因为模型的准确性比模型训练的速度更重要。还有其他一些提供不同训练速度和准确性的模型,可以在下面这个地址中找到。
- https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
训练
训练代码是在本地计算机上运行的,以检查是否一切都在正常工作。一旦它在正常的工作,它就会被部署到Google云平台的ML引擎上。该模型接受了超过10万步长的训练。
- ML引擎:https://cloud.google.com/ml-engine/

动画版圣诞老人
这个模型对动画和真人的图片都很有效果。
真人版圣诞老人
输出模型
训练结束后,该模型被导出用于在不同图像上进行测试。为了导出模型,我们选择了从训练工作中获得的最新的检查点,并将其输出到一个冻结的推理图中。
- 将检查点转换为冻结推理图的脚本:https://github.com/turnerlabs/character-finder/blob/master/object_detection/export_inference_graph.py
我们还为我们的模型建立了一个网页,网页从google搜索中提取图像,并试图在还原的图像中找到圣诞老人。这个网页的结果被过滤了,只显示了超过60%的置信度。下图是网页的快照。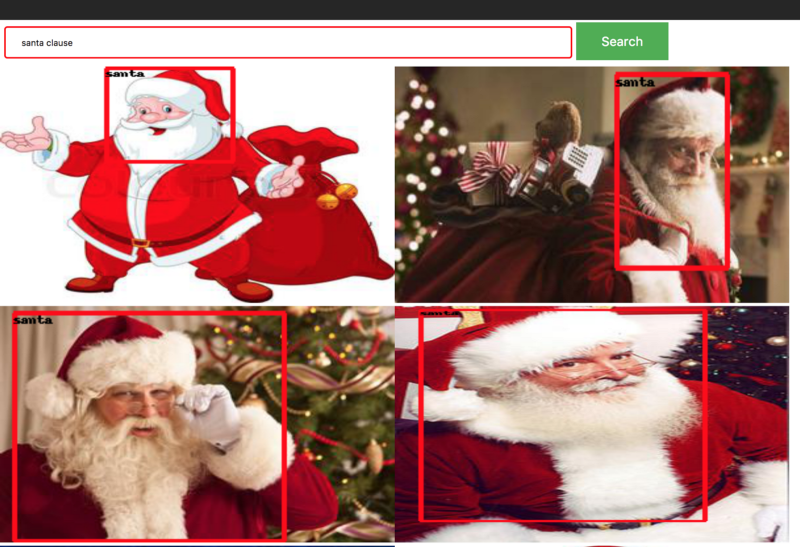
我们发现了圣诞老人! !
下一个步骤
当训练工作开始的时候,我们注意到总损失很快就降到1以下,这就意味着这个模型在寻找圣诞老人方面做得很好。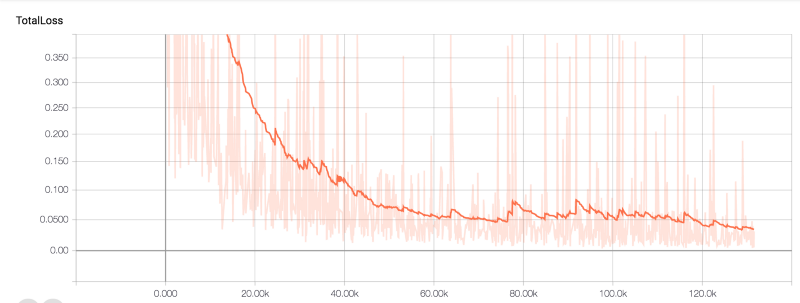
总损失
我们知道我们的模式不可能变得完美。虽然该模型在准确地找到圣诞老人方面做得相当不错,我们也得到了错误的判断。错误的判断对于这种情况来说是指,图像中没有圣诞老人,但模型却预测图像中会有。
错误的判断

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消