











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






将吴恩达的第一个深度神经网络应用于泰坦尼克生存数据集
2017年11月23日 由 xiaoshan.xiang 发表
340106
0
这篇文章包括了神经网络在kaggle泰坦尼克生存数据集上的应用程序。它帮助读者加深他们对神经网络的理解,而不是简单地执行吴恩达代码。泰坦尼克生存数据集就是可以随意使用的一个例子。
代码在Github repo地址:https://github.com/jaza10/AppliedNeuralNetworkTitanicSurvival
课程地址:https://www.coursera.org/learn/neural-networks-deep-learning
泰坦尼克生存数据集地址:https://www.kaggle.com/c/titanic/data
课程地址:https://www.udemy.com/python-for-data-science-and-machine-learning-bootcamp/learn/v4/overview
文章地址:https://www.kaggle.com/manuelatadvice/feature-engineering-titles
scikit-学习文档地址:http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
预先处理数据看起来是这样的:
6.应用神经网络.
得到变量X和y,然后转置以适应神经网络结构。
根据特性的数量选择第一层的维度。在这种情况下,第一个维度是11。然后选择尽可能多的隐藏层。
预先处理测试数据。通过X的正向传播和训练神经网络的参数生成预测。
将生成的预测保存为csv文件,然后将文件提交给kaggle。这一预测将使你跻身于参与者的前30%。
你已经将神经网络应用于你自己的数据集了。
现在我鼓励你使用网络中的迭代次数和层数。
在泰坦尼克号生存数据库上应用的神经网络大概有些矫枉过正。
代码在Github repo地址:https://github.com/jaza10/AppliedNeuralNetworkTitanicSurvival
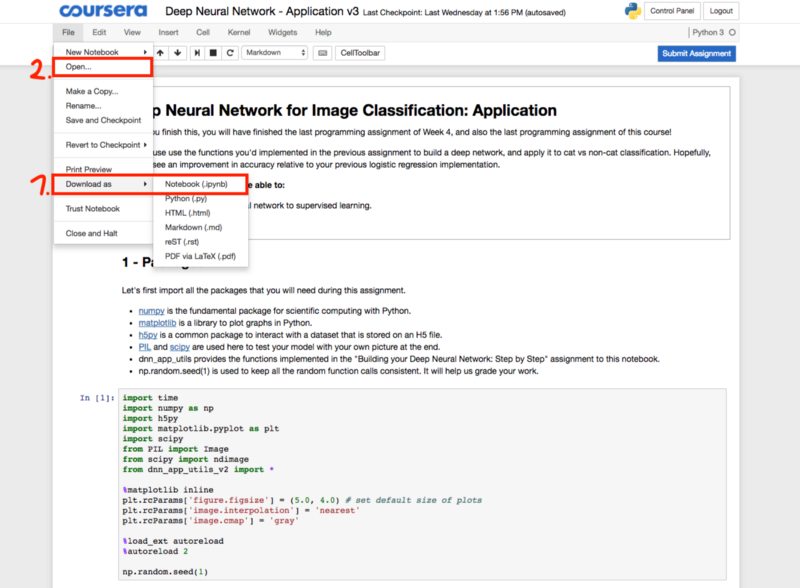
1.下载“深度神经网络应用程序”和来自Coursera中心的“dnn_utils_v2.py”文件,并将其保存在本地
- Github repo不包含deeplearning.ai提供的代码。请从Coursera深度学习专业化课程中学习。所需的材料在第4周的编程作业中。
课程地址:https://www.coursera.org/learn/neural-networks-deep-learning
下载Coursera中心的“深度神经网络应用程序v3”并点击“打开”
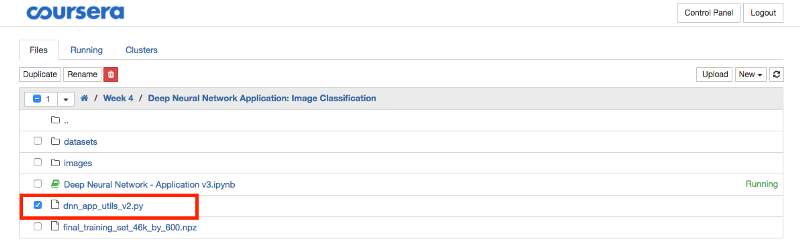
下载dnn_app_utils_v2.py文件
2. 下载kaggle泰坦尼克生存数据集,并将其保存在与“数据集”文件夹相同的位置。
泰坦尼克生存数据集地址:https://www.kaggle.com/c/titanic/data
- 为方便起见,我已经在Github repo中包含了数据集。
3.打开“深度神经网络应用程序”笔记本。
- 你可以安全地删除所有其他单元格,除了输入和L-Layer_model单元格;
- 运行两个单元格。
4.加载泰坦尼克生存数据集。
5.预先处理数据集。
- 以等级为基础来计算乘客年龄--该想法来自Jose Portilla极力推荐的Udemy课程“数据科学与机器学习训练营的Python”,它属于逻辑回归的一个分支;
课程地址:https://www.udemy.com/python-for-data-science-and-machine-learning-bootcamp/learn/v4/overview
- 从名字中提取乘客头衔 - 我遵循曼努埃尔(Manuel)伟大而简单的文章--从名字中提取头衔;
文章地址:https://www.kaggle.com/manuelatadvice/feature-engineering-titles
- 列出乘客序号、客舱和名字;
- 伪编码分类变量的性别,登船卡和头衔;
- 衡量年龄和票价--特征扩展帮助梯度下降算法收敛更快,参阅scikit-learn文档或Github repo。
scikit-学习文档地址:http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
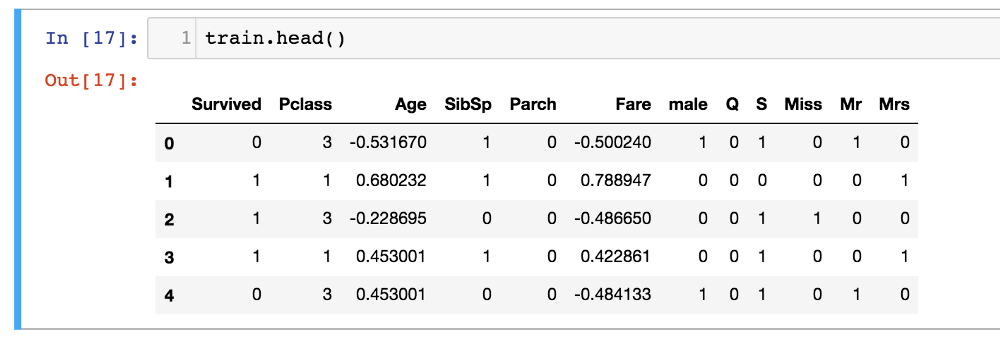
预先处理数据看起来是这样的:
训练集包含11个特征,为神经网络的评估做好准备
6.应用神经网络.
得到变量X和y,然后转置以适应神经网络结构。
from sklearn.model_selection import train_test_split
X = train.drop('Survived', axis=1)
y = train['Survived']
X_tr, X_te, y_tr, y_te = train_test_split(X, y, test_size=0.2)
# Transpose your data
X_tr_T = X_tr.T
X_te_T = X_te.T
y_tr_T = y_tr.T.values.reshape(1,y_tr.shape[0])
y_te_T = y_te.T.values.reshape(1,y_te.shape[0])
根据特性的数量选择第一层的维度。在这种情况下,第一个维度是11。然后选择尽可能多的隐藏层。
### CONSTANTS ###
layers_dims = [11, 25, 25, 25, 25, 25, 10, 1] # 7-layer model
parameters = L_layer_model(X_tr_T, y_tr_T, layers_dims, num_iterations = 2500, print_cost = True)
# Calculate accuracy on the training set
pred_train = predict(X_tr_T, y_tr_T, parameters)
# Calculate accuracy on the test set
pred_test = predict(X_te_T, y_te_T, parameters)
第一次尝试获得85%的训练和82%的测试精度
预先处理测试数据。通过X的正向传播和训练神经网络的参数生成预测。
# Load test data
test = pd.read_csv('datasets/titanic_test.csv')
# Preprocess test data
# Prepare X to generate predictions
X = test.drop(['PassengerId','Master'], axis=1)
# Transpose X to fit neural network architecture
X_tr_T = X.T
# Calculate predictions through forward propagation with the parameters
# obtained through fitting the neural net to the training data
probas, caches = L_model_forward(X_tr_T, parameters)
# Get classes from predictions
p = np.zeros((1,X_tr_T.shape[1]))
for i in range(0, probas.shape[1]):
if probas[0,i] > 0.5:
p[0,i] = 1
else:
p[0,i] = 0
# Generate the predictions file
pIds = pd.DataFrame(data=test['PassengerId'].astype(int), columns=['PassengerId'], dtype=int)
preds = pd.DataFrame(data=p.T,columns=['Survived'], dtype=int)
final_prediction = pd.concat([pIds, preds], axis=1)
final_prediction.to_csv('titanic_survival_predictions.csv', index=False)
最后一步:生成测试数据的预测
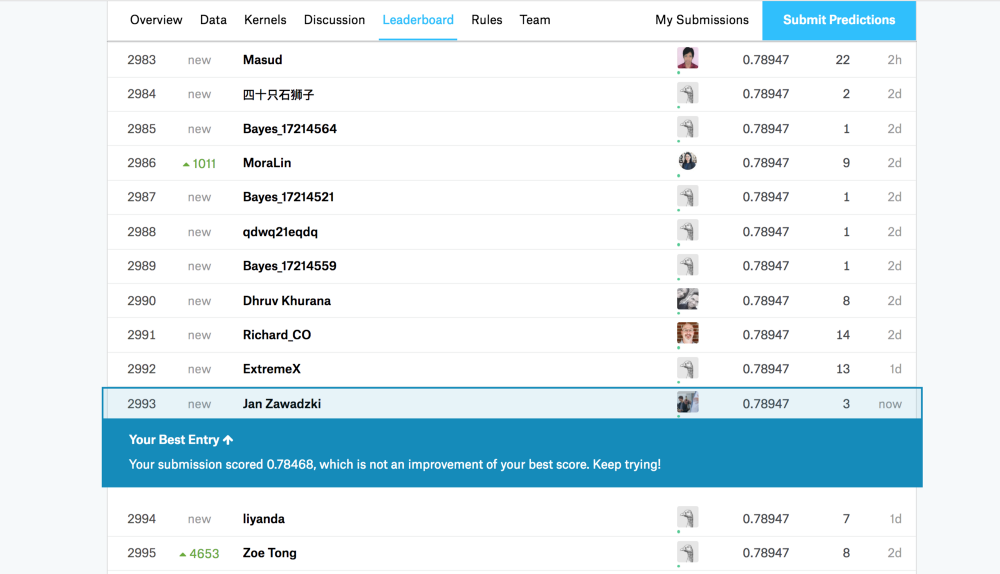
将生成的预测保存为csv文件,然后将文件提交给kaggle。这一预测将使你跻身于参与者的前30%。
提交预测文件会使你进入前三名,并帮助你适应kaggle竞赛
你已经将神经网络应用于你自己的数据集了。
现在我鼓励你使用网络中的迭代次数和层数。
在泰坦尼克号生存数据库上应用的神经网络大概有些矫枉过正。
关键要点:
- 从Coursera中心下载“应用深度学习”和“dnn_utils_v2”jupyter notebook,并在局部环境中运行;
- 相应地预先处理数据;
- 调换X和Y变量,以便拥有一个“示例特征”的训练矩阵;
- 调整第一个图层的维度以匹配特征的数量;
- 训练神经网络并保存生成的参数;
- 通过测试数据的正向传播和之前保存的神经网络参数,生成对测试集的预测。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消