











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






这样也可以?使用神经网络来“生成”视频并检测视频中的车祸
2017年11月24日 由 xiaoshan.xiang 发表
898750
0
介绍
人们认为理所当然的任务对于机器来说往往很难完成。这就是为什么通过CAPTCHA测试证明自己是人时,总是被问到一个简单的问题,比如图像是否包含道路标志,或者选择包含食物的图像子集(参见Moravec悖论)。这些测试在确定用户是否是人类方面是有效的,因为对于机器来说,语境中的图像识别是很困难的。训练计算机以自动,高效的方式准确地回答这些问题是很复杂的。
为了解决这个问题,像Facebook和亚马逊这样的公司花费大量的资金来手动处理图像和视频分类问题。例如,TechRepublic认为手动标记数据可能是“未来的蓝领工作”,我们已经看到像Facebook这样的公司正在策划新闻推送的助手。审查数以百万计的图像和视频,手动识别某些类型的内容是非常繁琐和高成本的。很少有技术能够自动化的分析图像和视频内容。
这篇文章介绍了作为洞察数据科学研究员,如何构建一个分类机器学习算法(Crash Catcher),该算法使用分层递归神经网络来隔离数百万小时视频中的特定相关内容。对我而言,该算法检查仪表板摄像头素材,以确定是否发生车祸。对于可能需要筛选数百万小时视频的企业(例如汽车保险公司),我创建的工具对于自动提取重要和相关的内容非常有用。
构建数据集:仪表板视频
在理想的情况下,对于这个特殊问题的完美数据集将是一个庞大的视频存储库,有成千上万的例子,包括车祸和非车祸。每一段视频还将包含清晰的元数据,并在视频(例如,汽车的摄像头位置、视频质量和持续时间)和内容(例如,汽车碰撞的类型,无论是“正面”还是“t - bone”)上保持一致。
然而,事实是,这种类型的数据在数据集中不存在,或是几乎不可能出现。相反,它遍布在网络上,由世界各地的广泛的提供。虽然数据收集和预处理并不是数据科学工作中最具魅力的方面,但它无疑是一个不可忽视的重要组成部分。

一个非事故驾驶的“负面”示例
我从VSLab研究公司(一个试图预测车祸的学术研究机构)获得了一组私人视频。他们的视频很短,大约有600个撞车事故视频和大约1000个没有撞车事故的视频(只是普通的,无聊的驾驶场景)的四秒长的片段。然而,这些数据有两个主要的问题:撞车事故的类型有太多的变化,数据集在撞车事故(正面)和非撞车事故(负面)视频之间是不平衡的。
撞车事故的种类太多
在观看视频的时候,我发现了太多的撞车事故,我发现了撞车事故的多样性,包括汽车、摩托车、摩托车、自行车和行人的各种组合。我从数据中删除了重复的驾驶场景,剩下439个负面视频和600个正面视频。在我第一次尝试用这个数据来训练一个模型时,我的算法几乎不会随机猜测一个视频是否包含事故。当你的模型能够准确地捕捉到数据时,数据的变化是巨大的。但是,当没有足够的数据来充分地模拟复杂的变化时,就会出现低度拟合,这是我们在最初的模型尝试中看到的。
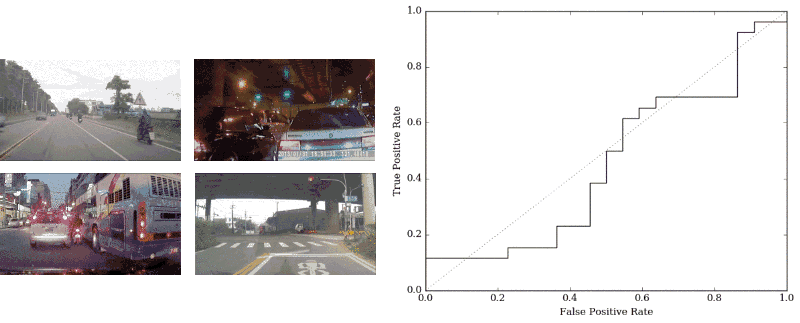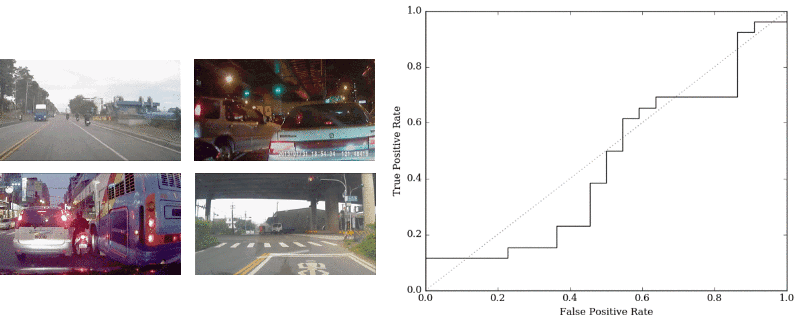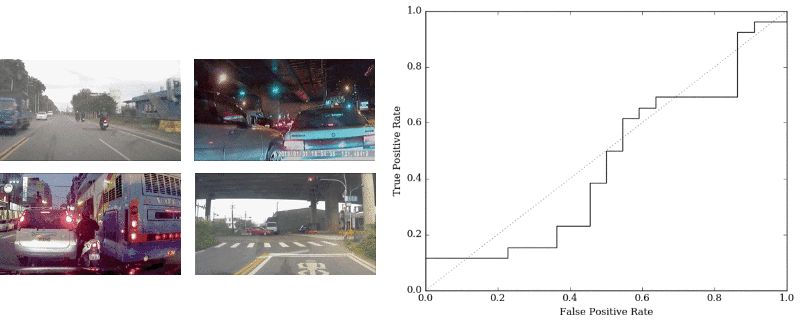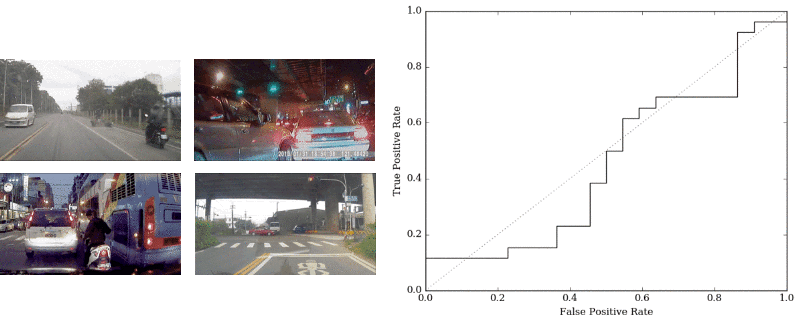
左边:视频显示了VSLab数据集中的一些变化。右:初始模型尝试的ROC曲线
能够准确地预测如此多种类的撞车事故需要的数据远远超过我所能获得的。我决定将这个项目的范围缩小到一个合理的小问题 - 如果我只专注于汽车碰撞,我是否能够预测一个视频是否包含车祸。
我手动修剪了视频数据集,只剩下36个车祸视频,然后只专注于汽车碰撞。这相当于7.5%的数据是正面的例子,这就产生了一个新的不平衡数据集的问题。
处理不平衡的数据
不平衡数据的问题可能会非常棘手。如果我要对数据集中的439个反例和36个正例进行算法训练,那么所得到的模型可以很容易地预测没有撞车事故的准确度为92.5%。然而,这92.5%的准确率并没有反映出当撞车事故发生时模型无法识别的事实。
为了用模型捕捉正面的例子,我需要更多的例子来创建一个平衡的数据集 - 所以我转向了YouTube,我从各种YouTube上传的视频中截取了带有仪表盘镜头的撞车事故。这增加了93个新的正面例子,使总数达到129。通过随机选择相同数量的负面例子,我创建了包含258个视频的平衡数据集。
预处理视频和图像
处理视频最大的挑战之一是数据量。258个视频看起来可能不是很多,但是当每个视频分解成单个帧时,就有超过25,000个单独的图像!

左上方:视频的原始帧。中间:原始帧的灰度版本。右下角:灰色帧的降低采样版本。
每个图像可以被认为是像素的二维阵列(原始尺寸为1280x720),其中每个像素具有关于产生了3D形状的红色,绿色和蓝色(RGB)颜色级别的信息。这个初始的数据结构对于分析是不必要的,所以我将每个三维RGB颜色数组简化为一维灰度数组。我也将每个图像的采样值下调了5个,以将每个图像中像素的数量减少到256x144数组。所有这些都减少了数据的大小,而不会丢失任何来自图像的真正重要的信息。
细节:分级递归神经网络
视频数据集由于其结构而具有挑战性 - 使用标准图像识别模型可以理解视频中的每一帧,因此理解整体语境更加困难。每个视频都是我想分类为有/没有撞车事故的数据点。然而,每个视频都是以时间序列的顺序为一组单独的图像。对数据既有层次结构也有时间序列 - 我选择的模型必须同时处理这些特征。
为了解决这些依赖性问题,我最初使用了预先训练的卷积神经网络(Google Inception模型)将每个视频中的每个图像矢量化为一组特征。但是因为帧之间并没有剧烈的变化,所以我没有选择有用的信息,模型的表现不如随机(还是!)。在收集了来自广大的的校友网络的建议之后,我决定训练自己的分级递归神经网络(HRNN)。这种方法使我能够训练一个模型,以便了解单个视频中的功能和对象的流量,并将其转化为模式,该模式将不同视频中的撞车事故分开来。
Google Inception模型地址:https://research.googleblog.com/2016/03/train-your-own-image-classifier-with.html
分级递归神经网络(HRNN)地址:http://ieeexplore.ieee.org/document/7298714/?reload=true
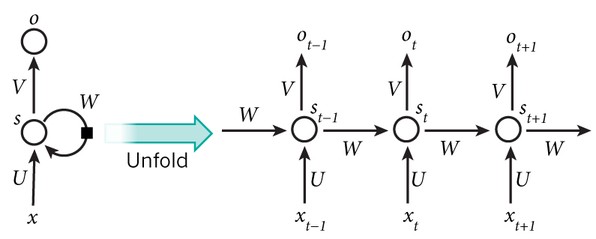
在左边,是一个递归神经网络的一个部分。循环回路指示递归神经网络的递归性质。如果我们“展开”神经元,我们就可以看到它在每次迭代中如何发生变化。输入(x(t - 1)x(t)x(t + 1)…)透过神经元,然后输出由“门”控制的(o(t - 1),o(t)o(t + 1))。这些门决定在内存中保留多少信息用于下一次迭代,以及输出中传递的信息。
HRNN本质上是一个递归神经网络,它包裹在另一个递归神经网络中(特别是,长短时记忆)。第一个神经网络分析了每个视频中图像的时间序列,跟踪对象或特征在整个剪辑中的移动或改变(例如,汽车前灯或汽车保险杠)。第二种递归神经网络采用第一个神经网络编码的模式和特征,并学习模式来辨别哪些视频含有撞车事故,哪些没有。
这些视频都是4秒的片段,所以我调整了代码,让算法能够解释任何长度的视频。这种设置对于公司来说更有用,他们想要分析更长的视频。这段代码可以将长视频分割成独立的短段,同时由我的HRNN进行筛选,以检测视频中是否包含了事故。这意味着对每个段的分析需要并行处理多个GPU/节点,以减少处理视频所需的总时间。
这个模型做得怎么样?
我使用了60%的数据集进行训练,20%来验证我的HRNN模型。我调整了模型的超参数(例如,神经元层的数量,在一段时间内加载到内存中的视频数量,损失函数,epochs的数量)用于优化以提高准确性,在这里,训练和验证集通过这些超参数的不同选项进行迭代。
你可能想知道我没有提到的其他20%的数据——这52个视频是我的对抗测试集,用来分析模型的最终性能。测试数据集上的ROC(接收机操作特征)曲线的精度超过81%,远远高于随机的概率。考虑到任务的复杂性,达到如此高的精确度令人惊讶。
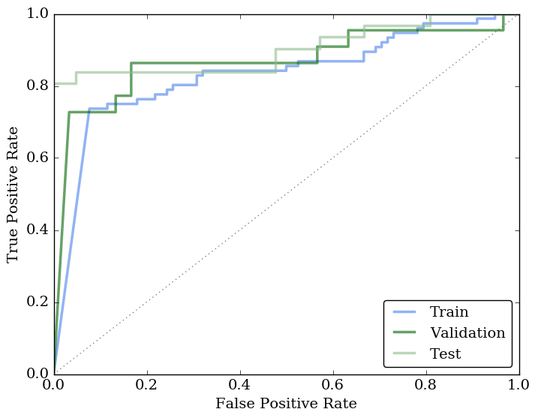
ROC曲线为最终调谐的HRNN模型的训练、验证和测试集。训练、验证和测试集的总体精度超过80%。虚线表示我们随机猜测视频是否包含车祸的预期性能。
HRNN的整体性能和准确性表明,它对以前从未见过的视频进行了相当好的概括。我准确地确定了测试集中的绝大多数正面例子都是撞车事故。
减少错误负例(撞车事故被错误地识别为正常的驾驶场景)是关键,因为这些案例对于公司筛选大量的视频来说是最重要的,即使偶尔没有撞车事故的视频被预测为有撞车事故(错误正例)。
结论
随着任务变得越来越复杂或者数据变得更加多样化,需要更多的数据来训练精确的神经网络。一般来说,更多的数据+多样性=更通用的模型。为了准确预测更广泛的情况(例如,将正面碰撞,追尾碰撞和汽车卡车碰撞进行分类),需要更多的数据。
获得更多数据的途径是找到更多的例子——但从个人经验来看,我知道这是一项繁琐、耗时的任务。通过稍微改变我们已经拥有的数据生成“新的”数据是一个更可行的选择。应用旋转,水平翻转,改变图像质量,或每个视频的其他变化将为HRNN创造新的内容。虽然人类可以很容易地将更改后的视频识别为原始内容的转换,但对于机器来说,它看起来就像新的和不同的数据。这些改变产生了一个“更大的”数据集,并且可以提高预测的泛化能力。
这个项目最困难的部分是将适当的数据集与适当的深度学习方法配对,以了解视频语境。这段经历非常具有挑战性,但也很有意义——在构建最终数据产品的过程中,关于数据处理和深度学习技术方面,我学到了很多。把所有的碎片拼在一起,不仅为我自己,也为那些试图理解视频内容的公司和组织做出了重要的贡献。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
人工智能,重在应用








广告


写评论取消
回复取消