











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






每个机器学习项目必须经过的五个阶段
2017年12月03日 由 yuxiangyu 发表
838030
0
机器学习和预测分析在我们今天的生活中非常普遍。它几乎可以影响我们所做的一切,包括零售和批发定价,消费者习惯和行为,市场营销,娱乐,医药,物流,游戏,AI语音识别,AI图像识别,自驾车和机器人。
然而,无论你是在创造一辆自动驾驶汽车,预测客户流失,还是创建一个产品推荐系统,所有的机器学习项目都遵循相同的流程和五个基本的阶段。
数据是新的石油,它正在迅速成为世界上最有价值的商品,因为它促进了机器学习项目。没有数据,就没有机器学习,也没有预测分析。就像石油的拥有等级一样,数据一样拥有等级。最好的数据就像机器学习模型的火箭燃料,买家必须付出高价。而就像石油提炼前需要先从地下开采一样,数据也要从存储设备中开采,然后数据科学家才能处理数据,数据分析师才可以执行收集数据的任务。
数据收集过程可能很容易也可能很难。当数据存储在一个位置(比如关系数据库)时,提取数据的过程非常简单,可以在几个小时内完成,但现实往往没这么简单。通常,数据分布在许多系统和存储设备上。例如,数据分析师可能要从分散在几个员工笔记本电脑上的电子表格中,从远程数据库的数据库表中收集数据,甚至要从几个第三方集成系统中收集数据。餐厅可能会把员工信息存入电子表格,库存和定价存入数据库,把客户订单存入第三方的订购系统。数据分析要将来自不同系统的所有数据收集到一个位置。
开采后的石油还必须进行提炼。有些原油提炼过程相对容易。而有一些原油提炼比较难。数据也是一样的。一般来说,提取数据的来源越多,准备数据所需的时间就越长。
第二阶段是清理数据为机器学习模型做准备的过程,同时对数据进行一些基本的探索。这个阶段通常被称为EDA(探索性数据分析)。那么,“干净”的数据意味着什么?在完美的世界里,你的数据也将是完美的。但遗憾的是我们不是生活在一个完美的世界,我们很少有“干净”的数据。我们所处理的数据通常充满了漏洞、缺失值和错误值。
我们来看看这个8个人观看电影3天的数据。我们的目标是创建一个根据他们以前看过的电影,以及他们的性别和年龄,为每个人推荐电影的电影推荐系统。请注意,在这里我们的数据完全干净。有2名电影观众缺失性别信息,1名电影观众缺失年龄信息。此外,在不同日子电影观众观看的电影名的还有空白。
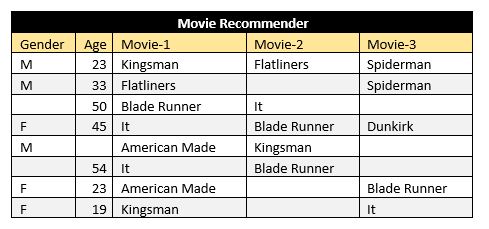
在清理数据时,数据分析师将与该领域的专家密切合作。他可能会问这样的问题:“为什么观看电影名的位置会缺少值?是因为他们当天没有看电影,还是看电影但没有统计?“她还需要决定是否应该从数据集中丢弃包含缺失性别和年龄的行。
有时数据不能由人逐个清洗。一些数据集包含数十至数千个特征(维度)。例如通过临床药物研究收集的数据和通过网站交互收集的数据通常具有数百至数千个特征。亚马逊最近研究消费者评论的数据集有10,001个维度;临床药物研究的许多数据集可以具有50000 - 100000个特征。然而,这些特征大部分是无关紧要的,不会为增加机器学习模型的价值。“降维”过程可以将数据集中的特征数量减少90%。降维是一中机器学习算法,它探索数据集的特征,并尝试在识别主要特征的同时消除无关特征。降维的算法,包括主成分分析(PCA),在大特征集上实际运行回归或分类模型以识别无关和主要特征。降维是一项数据分析师或数据科学家和领域专家共同完成的工作。
由于需要清洗的数据可能需要评估和更新许多细节,因此这个阶段通常是机器学习项目中最长的阶段。
在清理完数据之后,数据分析师将会对数据进行一些基本的分析,并创建汇总数据的图表。这些图表将直观地描绘数据的性质,包括统计分析。然后将图表连同清洁的数据提供给数据科学家开始机器学习。
现在数据已经被收集和清理完毕,数据科学家可以开始对机器学习模型的数据进行训练。机器学习模型有三种基本类型:
回归是一类机器学习,用来确定一个真值,就像一个数字。最流行的回归算法是Leaner Regressor。下面是一个2-dimnails线性回归的例子。基于车辆的马力(HP)和车辆的燃料效率(MPG,英里/加仑),模型被绘制在平面图上。然后通过绘制的点绘制趋势线(通过算法)。在线性回归模型中,用于绘制趋势线的算法是从基本代数导出的y = mx + b。一旦绘制趋势线被绘制出来,我们可以做出预测。例如,如果我的新车有400马力,我可以预测它的燃油效率将是大约14英里/加仑。
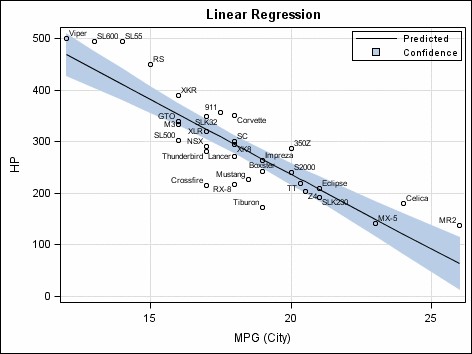
请注意,上面的示例使用了两个维度,即数据科学中所称的特征。人类可以同时处理和理解两个维度。非常聪明的人可以处理和理解三个维度的线性回归图。计算机可以处理和理解多维图表。当零售商使用机器学习来创建定价模型,或者当对冲基金使用机器学习预测股票价格时,机器学习模型通常使用上百个特征。很遗憾,我无法给你画一个125-dimednional线性回归图。
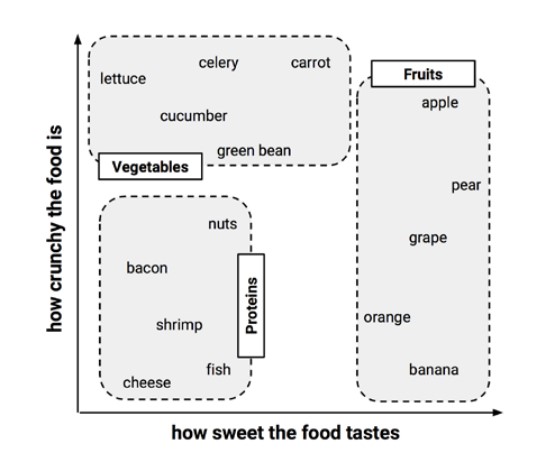
分类模型通常用于对人物,事件或事物进行分类。在大多数情况下,分类模型对人类来说通常更容易理解。例如,流行的KNN算法可以在两个维度上被可视化。在下面的图表中,我们根据食物的松脆程度和食物的甜度来绘制食物。食物越脆,在y轴上的食物名称就越高。食物越甜,X轴上食物名越靠右。
一旦食物被绘制出来,我们就可以根据食物彼此的接近程度将食物聚类。(邻近度测定是算法调整的机器学习模型中的一个参数)。在我们的例子中,我们将绘制的食物分成3类:蔬菜,蛋白质类和水果。
现在我们已经绘制了食物的两个特点,脆脆和甜美,并将每个聚类分类,我们可以开始做出预测。在下面的图表中,我们添加一个中等甜度和中等松脆的番茄。我们现在需要预测西红柿属于在哪一类,番茄显然不属于任何预定义的类别。我们注意到与番茄临近的有4个:1个蛋白质,1个蔬菜和2个水果。最邻近是蛋白质类。番茄是蛋白质,蔬菜还是水果的最终决定取决于如何配置KNN模型。首先,用来测定西红柿与其他物体之间距离的测量算法。有几种常用的算法,包括欧氏和曼哈顿的测量方法。其次,当我们做出最终决定时,我们应该考虑与目标临近的食物数量。
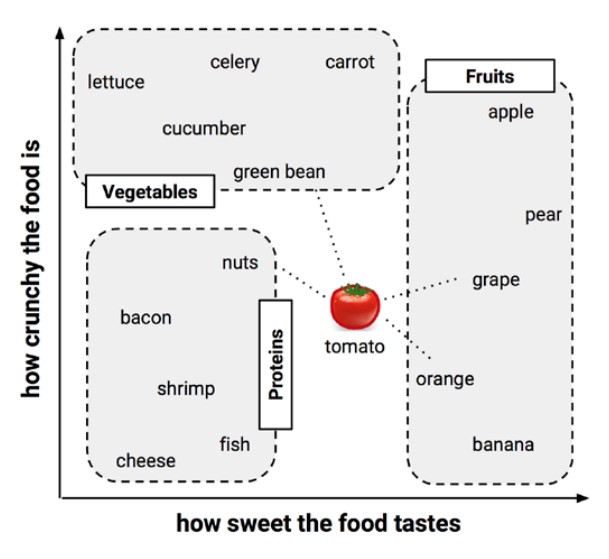
那么番茄是蛋白质,蔬菜还是水果?我希望你自己运行一个KNN模型,并作出自己的决定。
上面的例子探讨了一个具有两个维度(特征)的KNN。就像回归模型一样,KNN可以有效地处理数百个维度。常用的情况有,Netflix的电影推荐和亚马逊的产品推荐。
另一种非常受欢迎的用于分类的机器学习模型是决策树。决策树因为高效而受欢迎,即使有多个维度,人类也可以很好地理解它们。决策树对于人类来说是如此容易理解的地方不是它们的计算原理(这实际上相当复杂)。决策树容易理解是因为输出预测树。在下面的例子中,一个决策树模型收集了一家领先银行证明贷款的数十万客户的数据。基于一些关键特征和贷款违约历史,这个算法能够创建一个容易让任何人理解和遵循的预测树。
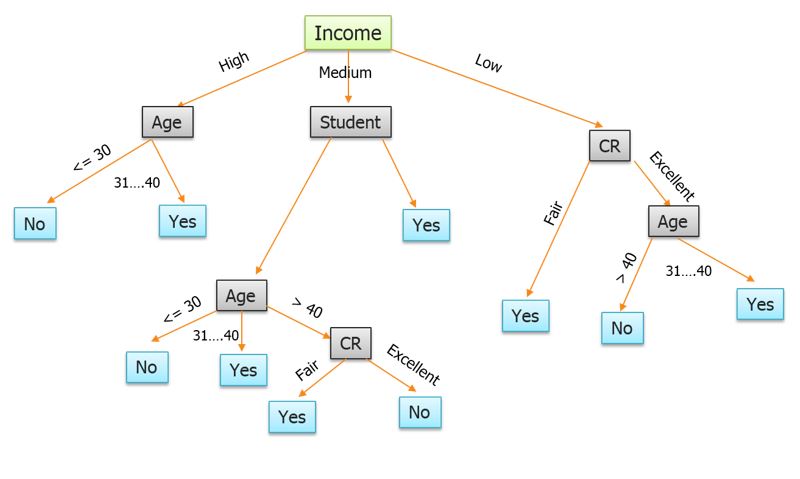
30岁以下的高收入人群似乎有很高的信用风险。另外,中等收入的学生是否值得信贷?为什么?我把这些问题留给你去思考。
在我们之前的例子中,我们有清晰的定义数据。但是数据并不总是可以被清晰的定义。聚类是一种特殊的机器学习算法,用于数据结构定义不清晰的情况。在上面的例子中,我们使用有监督的机器学习模型。在聚类中,模型运行是无监督的,它可以自行创建群集。我们可以定义要创建的群集的数量,或者让模型独立运行,并查看它有什么发现。
可以在阶段2中使用群集来帮助数据分析人员从非结构化数据创建结构。最流行的聚类模型是K-Means聚类模型。K-Means中的K代表要求模型创建的群集数量。如果你选择允许模型尝试不同的群集数量,也可以不定义此值。
在下面的例子中,我们对一组包含三个特征(维度)的数据运行聚类算法:年龄,教育程度和收入。注意:在这个例子中,我们并没有根据已有标签对目标进行预测。我们并不试图预测信誉度,电影偏好等等。我们在这个阶段所做的就是要求这个模型把人口分成几组。在这个例子中,K均值聚类算法将总体分成5个群集。
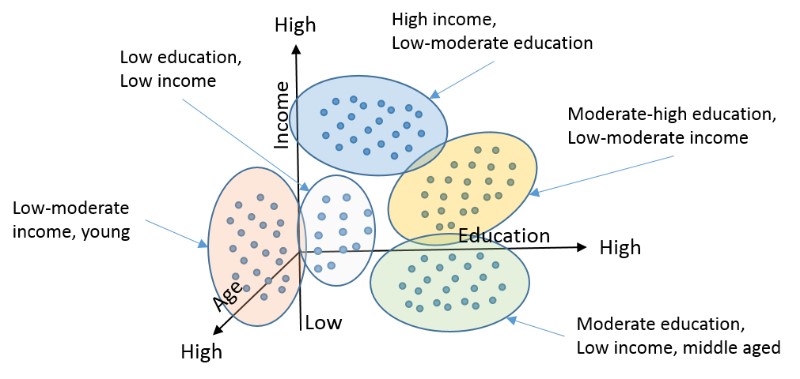
如前所述,聚类是一个无监督的学习模型,可以在阶段2或阶段3中应用。它通常应用于阶段2,当我们想要将数据分割成群集,以便在阶段3中运行群集上的不同模型以便对已识别的标签进行预测。当我们的目标是聚类时,我们可以在阶段3运行聚类算法。例如,广告公司可能希望识别集群以创建有针对性的广告。在这种情况下,广告客户不会像预测现有群集那样预测未来事件。
深度学习有很大的潜力。我们迄今为止所讨论的许多算法的来源可追溯到数百年的应用统计,而深度学习相对时间较短。深度学习模仿人脑,特别是模仿神经元相互作用。
深度学习使自然语言处理,语音识别和图像识别等技术产生重大突破。同时它也是自动驾驶和机器人技术的核心,其潜力已经得到证明。许多专家认为,如果深度学习以预期的速度走向成熟,世界有机会在50年内看到有意识的有知觉的人造智能体。
在上一阶段,我们对数据进行了训练。数据科学家训练一个模型时不会使用全部数据。虽然用于训练的数据越多,模型的训练效果越好,预测的准确性也越高。但我们必须保留大约30%的的数据隐藏在模型中。我们希望在大约70%的数据中训练模型,隐藏的30%作为测试。
我们通过模型在训练阶段隐藏的30%的数据进行测试,以此评估模型的性能。这就确保了模型的预测不会因为受到可见的数据影响而产生偏见。有时,甚至会保留一部分数据不发送给数据科学家,以确保不会出现偏见。
当评估模型时,会显示30%的数据修剪我们试图预测的标签。例如,在评估信用评估决策树时,我们会为决策树提供消费者的数据不包括表明他们是否拖欠贷款的数据。而是要求模型预测提供数据中每个消费者的贷款违约情况。模型预测后,我们就会将预测值与实际值进行比较:无论消费者是否违约。
在评估模型的性能时,必须对几个因素进行评估。我们不能简单地对模型做出正确预测的次数进行评分。这种类型的评估被称为准确性,只是一种度量方式。例如,如果有95%的消费者没有违约,那么一个预测所有人都不会违约的模型的准确率也能达到了95%,这显然没有什么意义。所以,我们需要几种评估模型的方法。
首先,让我们来看看下面预测信用违约模型的结果。我们可以看到,该模型预测有1,370名消费者会违约。那些实际上违约的人被称为“真阳性”(TP)。那些预测违约但实际没违约被称为“假阳性”(FP)。该模型还预测,8509名消费者不会违约。实际上没有违约的那些被称为“真阴性”(TN),被预测为没违约但实际违约的消费者被称为“假阴性”(FN)。

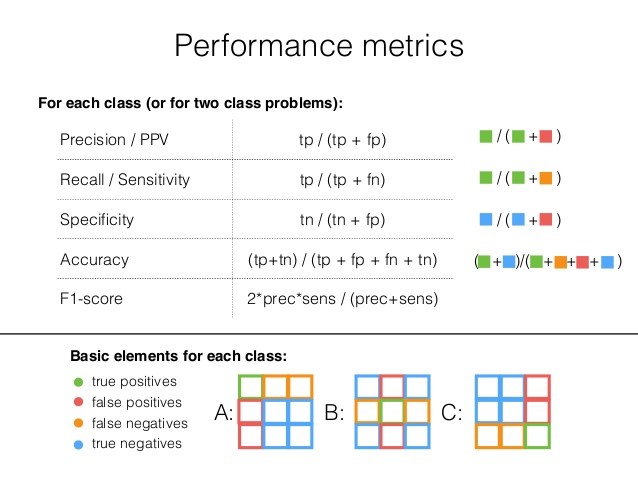
下图详细列出了分类模型最常用的性能指标。他们是:
准确性:总数中正确预测比例(常见于非专业人士)。
精度:正确识别的真阳性的比例。
灵敏度或召回率:正确识别的真阳性的比例。
特异性:正确识别的真阴性的比例。
虽然准确性是外行最常见的评估指标,但其他评估指标才是数据科学家,领域专家和业务专业人士关心的问题。例如,假设一个模型需要预测一种罕见的疾病,这种疾病在0.01%的人群中存在。如果这个模型预测没有任何人患病,那么模型的准确率为99.9%,但真正患有这种疾病的人无法被识别出来。
F1分数是一种综合评分,它兼顾了召回率和精度,这是评估分类模型性能时最常用的两个指标。F1是衡量整体模型性能的一个很好的标准,但不应该单独考虑。它主要用来检查性能指标的范围,以真正理解模型的表现如何。
回归模型预测实际数字,如价格,数量或测量值。这些不是类别,因此无法用分类性能指标(如准确性和召回率)进行评估。我们必须对回归模型使用统计分析工具。
最流行的回归评估指标是均方根误差(RMSE,也称为标准误差)。我们假设一个回归模型预测亚马逊股票的价格在接下来的5天里将是936.89,939.16,949.88,960.34,962.36,实际的价格是939.79,938.60,950.87,956.40,961.35。第一个预测值和第一个实际值的差值是2.9。第二个预测值与第二个实际值的差值为0.56。将每个差值结果进行平方,保证负数不会对度量产生负的影响。差值被称为“误差”; 当它被平方时,它被称为平方误差。这是衡量预测与实际价值有多接近的指标。
然后,将所有的平方误差相加除以预测总数再开根。RMSE是回归模型表现的一个非常好的指标。

如果我们对模特的表现感到满意可以跳过这一步。但通常情况下,总会有改善的空间。就像当我们学习生活中的新技能一样,比如拳击或弹钢琴一样,我们的表现总是有改进的空间。
如果我们模型的性能很差,我们会回到第二阶段,甚至第一阶段。可怕的表现可能是模型的错误,但是当我们真的表现糟糕的时候,更多的时候是错误存在于数据中。也许数据本身质量不好,没有一个模型可以说话。或者也许数据没有正确清理,因为我们需要回到原始数据并重新审视我们如何清理数据。在这个例子中,数据分析师最好咨询数据领域的专家。
如果我们的模型的表现没有猜测好,我们可能会考虑一个全新的模型。这种事情也经常发生。发生这种情况时,我们重复第3阶段,并在部分数据上训练新模型,然后在第4阶段评估我们的新模型的性能。然后,我们又回到了这里。
如果数据的表现比预计要好,最好的方法可能是坚持使用当前的模型,并调优模型的超参数。模型的超参数是在数据训练模型之前设置的。大多数模型会包含多个超参数,每个超参数可以通过多种方式进行调整。事实上,对于任何给定的模型,通常有数百到数千个超参数组合。对于某些模型来说,调整超参数会对模型的性能产生极大的影响。
机器学习已经成为我们日常生活的一部分,它改变了商业智能。预测分析应用程序可以进行客户分类,风险评估,客户流失预防,销售预测,市场分析和财务建模等等。由于机器学习模型的预测能力和准确性,数据科学家可以向业务分析师提供一些被称为“不公平的竞争优势”的业务分析师。
然而,即使是再强大,准确和复杂的机器学习模型,也同样要经过这五个阶段。
然而,无论你是在创造一辆自动驾驶汽车,预测客户流失,还是创建一个产品推荐系统,所有的机器学习项目都遵循相同的流程和五个基本的阶段。
阶段1:数据收集
数据是新的石油,它正在迅速成为世界上最有价值的商品,因为它促进了机器学习项目。没有数据,就没有机器学习,也没有预测分析。就像石油的拥有等级一样,数据一样拥有等级。最好的数据就像机器学习模型的火箭燃料,买家必须付出高价。而就像石油提炼前需要先从地下开采一样,数据也要从存储设备中开采,然后数据科学家才能处理数据,数据分析师才可以执行收集数据的任务。
数据收集过程可能很容易也可能很难。当数据存储在一个位置(比如关系数据库)时,提取数据的过程非常简单,可以在几个小时内完成,但现实往往没这么简单。通常,数据分布在许多系统和存储设备上。例如,数据分析师可能要从分散在几个员工笔记本电脑上的电子表格中,从远程数据库的数据库表中收集数据,甚至要从几个第三方集成系统中收集数据。餐厅可能会把员工信息存入电子表格,库存和定价存入数据库,把客户订单存入第三方的订购系统。数据分析要将来自不同系统的所有数据收集到一个位置。
第二阶段:探索和准备数据(探索性数据分析)
开采后的石油还必须进行提炼。有些原油提炼过程相对容易。而有一些原油提炼比较难。数据也是一样的。一般来说,提取数据的来源越多,准备数据所需的时间就越长。
第二阶段是清理数据为机器学习模型做准备的过程,同时对数据进行一些基本的探索。这个阶段通常被称为EDA(探索性数据分析)。那么,“干净”的数据意味着什么?在完美的世界里,你的数据也将是完美的。但遗憾的是我们不是生活在一个完美的世界,我们很少有“干净”的数据。我们所处理的数据通常充满了漏洞、缺失值和错误值。
我们来看看这个8个人观看电影3天的数据。我们的目标是创建一个根据他们以前看过的电影,以及他们的性别和年龄,为每个人推荐电影的电影推荐系统。请注意,在这里我们的数据完全干净。有2名电影观众缺失性别信息,1名电影观众缺失年龄信息。此外,在不同日子电影观众观看的电影名的还有空白。
在清理数据时,数据分析师将与该领域的专家密切合作。他可能会问这样的问题:“为什么观看电影名的位置会缺少值?是因为他们当天没有看电影,还是看电影但没有统计?“她还需要决定是否应该从数据集中丢弃包含缺失性别和年龄的行。
有时数据不能由人逐个清洗。一些数据集包含数十至数千个特征(维度)。例如通过临床药物研究收集的数据和通过网站交互收集的数据通常具有数百至数千个特征。亚马逊最近研究消费者评论的数据集有10,001个维度;临床药物研究的许多数据集可以具有50000 - 100000个特征。然而,这些特征大部分是无关紧要的,不会为增加机器学习模型的价值。“降维”过程可以将数据集中的特征数量减少90%。降维是一中机器学习算法,它探索数据集的特征,并尝试在识别主要特征的同时消除无关特征。降维的算法,包括主成分分析(PCA),在大特征集上实际运行回归或分类模型以识别无关和主要特征。降维是一项数据分析师或数据科学家和领域专家共同完成的工作。
由于需要清洗的数据可能需要评估和更新许多细节,因此这个阶段通常是机器学习项目中最长的阶段。
在清理完数据之后,数据分析师将会对数据进行一些基本的分析,并创建汇总数据的图表。这些图表将直观地描绘数据的性质,包括统计分析。然后将图表连同清洁的数据提供给数据科学家开始机器学习。
阶段3:训练数据模型
现在数据已经被收集和清理完毕,数据科学家可以开始对机器学习模型的数据进行训练。机器学习模型有三种基本类型:
- 回归
- 分类
- 聚类
回归
回归是一类机器学习,用来确定一个真值,就像一个数字。最流行的回归算法是Leaner Regressor。下面是一个2-dimnails线性回归的例子。基于车辆的马力(HP)和车辆的燃料效率(MPG,英里/加仑),模型被绘制在平面图上。然后通过绘制的点绘制趋势线(通过算法)。在线性回归模型中,用于绘制趋势线的算法是从基本代数导出的y = mx + b。一旦绘制趋势线被绘制出来,我们可以做出预测。例如,如果我的新车有400马力,我可以预测它的燃油效率将是大约14英里/加仑。
请注意,上面的示例使用了两个维度,即数据科学中所称的特征。人类可以同时处理和理解两个维度。非常聪明的人可以处理和理解三个维度的线性回归图。计算机可以处理和理解多维图表。当零售商使用机器学习来创建定价模型,或者当对冲基金使用机器学习预测股票价格时,机器学习模型通常使用上百个特征。很遗憾,我无法给你画一个125-dimednional线性回归图。
分类
分类模型通常用于对人物,事件或事物进行分类。在大多数情况下,分类模型对人类来说通常更容易理解。例如,流行的KNN算法可以在两个维度上被可视化。在下面的图表中,我们根据食物的松脆程度和食物的甜度来绘制食物。食物越脆,在y轴上的食物名称就越高。食物越甜,X轴上食物名越靠右。
一旦食物被绘制出来,我们就可以根据食物彼此的接近程度将食物聚类。(邻近度测定是算法调整的机器学习模型中的一个参数)。在我们的例子中,我们将绘制的食物分成3类:蔬菜,蛋白质类和水果。
现在我们已经绘制了食物的两个特点,脆脆和甜美,并将每个聚类分类,我们可以开始做出预测。在下面的图表中,我们添加一个中等甜度和中等松脆的番茄。我们现在需要预测西红柿属于在哪一类,番茄显然不属于任何预定义的类别。我们注意到与番茄临近的有4个:1个蛋白质,1个蔬菜和2个水果。最邻近是蛋白质类。番茄是蛋白质,蔬菜还是水果的最终决定取决于如何配置KNN模型。首先,用来测定西红柿与其他物体之间距离的测量算法。有几种常用的算法,包括欧氏和曼哈顿的测量方法。其次,当我们做出最终决定时,我们应该考虑与目标临近的食物数量。
那么番茄是蛋白质,蔬菜还是水果?我希望你自己运行一个KNN模型,并作出自己的决定。
上面的例子探讨了一个具有两个维度(特征)的KNN。就像回归模型一样,KNN可以有效地处理数百个维度。常用的情况有,Netflix的电影推荐和亚马逊的产品推荐。
另一种非常受欢迎的用于分类的机器学习模型是决策树。决策树因为高效而受欢迎,即使有多个维度,人类也可以很好地理解它们。决策树对于人类来说是如此容易理解的地方不是它们的计算原理(这实际上相当复杂)。决策树容易理解是因为输出预测树。在下面的例子中,一个决策树模型收集了一家领先银行证明贷款的数十万客户的数据。基于一些关键特征和贷款违约历史,这个算法能够创建一个容易让任何人理解和遵循的预测树。
30岁以下的高收入人群似乎有很高的信用风险。另外,中等收入的学生是否值得信贷?为什么?我把这些问题留给你去思考。
聚类
在我们之前的例子中,我们有清晰的定义数据。但是数据并不总是可以被清晰的定义。聚类是一种特殊的机器学习算法,用于数据结构定义不清晰的情况。在上面的例子中,我们使用有监督的机器学习模型。在聚类中,模型运行是无监督的,它可以自行创建群集。我们可以定义要创建的群集的数量,或者让模型独立运行,并查看它有什么发现。
可以在阶段2中使用群集来帮助数据分析人员从非结构化数据创建结构。最流行的聚类模型是K-Means聚类模型。K-Means中的K代表要求模型创建的群集数量。如果你选择允许模型尝试不同的群集数量,也可以不定义此值。
在下面的例子中,我们对一组包含三个特征(维度)的数据运行聚类算法:年龄,教育程度和收入。注意:在这个例子中,我们并没有根据已有标签对目标进行预测。我们并不试图预测信誉度,电影偏好等等。我们在这个阶段所做的就是要求这个模型把人口分成几组。在这个例子中,K均值聚类算法将总体分成5个群集。
如前所述,聚类是一个无监督的学习模型,可以在阶段2或阶段3中应用。它通常应用于阶段2,当我们想要将数据分割成群集,以便在阶段3中运行群集上的不同模型以便对已识别的标签进行预测。当我们的目标是聚类时,我们可以在阶段3运行聚类算法。例如,广告公司可能希望识别集群以创建有针对性的广告。在这种情况下,广告客户不会像预测现有群集那样预测未来事件。
深度学习
深度学习有很大的潜力。我们迄今为止所讨论的许多算法的来源可追溯到数百年的应用统计,而深度学习相对时间较短。深度学习模仿人脑,特别是模仿神经元相互作用。
深度学习使自然语言处理,语音识别和图像识别等技术产生重大突破。同时它也是自动驾驶和机器人技术的核心,其潜力已经得到证明。许多专家认为,如果深度学习以预期的速度走向成熟,世界有机会在50年内看到有意识的有知觉的人造智能体。
阶段4:评估模型性能
在上一阶段,我们对数据进行了训练。数据科学家训练一个模型时不会使用全部数据。虽然用于训练的数据越多,模型的训练效果越好,预测的准确性也越高。但我们必须保留大约30%的的数据隐藏在模型中。我们希望在大约70%的数据中训练模型,隐藏的30%作为测试。
我们通过模型在训练阶段隐藏的30%的数据进行测试,以此评估模型的性能。这就确保了模型的预测不会因为受到可见的数据影响而产生偏见。有时,甚至会保留一部分数据不发送给数据科学家,以确保不会出现偏见。
当评估模型时,会显示30%的数据修剪我们试图预测的标签。例如,在评估信用评估决策树时,我们会为决策树提供消费者的数据不包括表明他们是否拖欠贷款的数据。而是要求模型预测提供数据中每个消费者的贷款违约情况。模型预测后,我们就会将预测值与实际值进行比较:无论消费者是否违约。
在评估模型的性能时,必须对几个因素进行评估。我们不能简单地对模型做出正确预测的次数进行评分。这种类型的评估被称为准确性,只是一种度量方式。例如,如果有95%的消费者没有违约,那么一个预测所有人都不会违约的模型的准确率也能达到了95%,这显然没有什么意义。所以,我们需要几种评估模型的方法。
首先,让我们来看看下面预测信用违约模型的结果。我们可以看到,该模型预测有1,370名消费者会违约。那些实际上违约的人被称为“真阳性”(TP)。那些预测违约但实际没违约被称为“假阳性”(FP)。该模型还预测,8509名消费者不会违约。实际上没有违约的那些被称为“真阴性”(TN),被预测为没违约但实际违约的消费者被称为“假阴性”(FN)。
下图详细列出了分类模型最常用的性能指标。他们是:
准确性:总数中正确预测比例(常见于非专业人士)。
精度:正确识别的真阳性的比例。
灵敏度或召回率:正确识别的真阳性的比例。
特异性:正确识别的真阴性的比例。
虽然准确性是外行最常见的评估指标,但其他评估指标才是数据科学家,领域专家和业务专业人士关心的问题。例如,假设一个模型需要预测一种罕见的疾病,这种疾病在0.01%的人群中存在。如果这个模型预测没有任何人患病,那么模型的准确率为99.9%,但真正患有这种疾病的人无法被识别出来。
F1分数是一种综合评分,它兼顾了召回率和精度,这是评估分类模型性能时最常用的两个指标。F1是衡量整体模型性能的一个很好的标准,但不应该单独考虑。它主要用来检查性能指标的范围,以真正理解模型的表现如何。
回归模型预测实际数字,如价格,数量或测量值。这些不是类别,因此无法用分类性能指标(如准确性和召回率)进行评估。我们必须对回归模型使用统计分析工具。
最流行的回归评估指标是均方根误差(RMSE,也称为标准误差)。我们假设一个回归模型预测亚马逊股票的价格在接下来的5天里将是936.89,939.16,949.88,960.34,962.36,实际的价格是939.79,938.60,950.87,956.40,961.35。第一个预测值和第一个实际值的差值是2.9。第二个预测值与第二个实际值的差值为0.56。将每个差值结果进行平方,保证负数不会对度量产生负的影响。差值被称为“误差”; 当它被平方时,它被称为平方误差。这是衡量预测与实际价值有多接近的指标。
然后,将所有的平方误差相加除以预测总数再开根。RMSE是回归模型表现的一个非常好的指标。
阶段5:提高模型性能
如果我们对模特的表现感到满意可以跳过这一步。但通常情况下,总会有改善的空间。就像当我们学习生活中的新技能一样,比如拳击或弹钢琴一样,我们的表现总是有改进的空间。
如果我们模型的性能很差,我们会回到第二阶段,甚至第一阶段。可怕的表现可能是模型的错误,但是当我们真的表现糟糕的时候,更多的时候是错误存在于数据中。也许数据本身质量不好,没有一个模型可以说话。或者也许数据没有正确清理,因为我们需要回到原始数据并重新审视我们如何清理数据。在这个例子中,数据分析师最好咨询数据领域的专家。
如果我们的模型的表现没有猜测好,我们可能会考虑一个全新的模型。这种事情也经常发生。发生这种情况时,我们重复第3阶段,并在部分数据上训练新模型,然后在第4阶段评估我们的新模型的性能。然后,我们又回到了这里。
如果数据的表现比预计要好,最好的方法可能是坚持使用当前的模型,并调优模型的超参数。模型的超参数是在数据训练模型之前设置的。大多数模型会包含多个超参数,每个超参数可以通过多种方式进行调整。事实上,对于任何给定的模型,通常有数百到数千个超参数组合。对于某些模型来说,调整超参数会对模型的性能产生极大的影响。
结论
机器学习已经成为我们日常生活的一部分,它改变了商业智能。预测分析应用程序可以进行客户分类,风险评估,客户流失预防,销售预测,市场分析和财务建模等等。由于机器学习模型的预测能力和准确性,数据科学家可以向业务分析师提供一些被称为“不公平的竞争优势”的业务分析师。
然而,即使是再强大,准确和复杂的机器学习模型,也同样要经过这五个阶段。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消