











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌大脑团队新尝试 用奇异向量典型相关分析解释深度神经网络
2017年11月29日 由 yining 发表
71814
0
深度神经网络(DNNs)在视觉、语言理解和语音识别等领域取得了前所未有的进展。但这些成功也带来了新的挑战。与许多以前的机器学习方法不同的是,深度神经网络可以很容易地在分类中产生敌对的例子,在强化学习中出现灾难性遗忘(catastrophic forgetting)这样的大型状态空间,以及在生成模型中的模式崩溃。为了构建更好、更健壮的基于深度神经网络的系统,对这些模型进行解释是至关重要的。谷歌大脑团队想要一个关于深度神经网络的表现相似性的概念:我们能不能有效地确定两个神经网络所学习到的表现是相同的?
奇异向量典型相关分析(SVCCA),是一个奇异值(SV)分解和典型相关分析(CCA)的合并。谷歌大脑团队曾发表过一篇名为“奇异向量典型相关分析:关于深度学习动力学和解释能力的奇异向量典型相关分析”的论文,文章中引入了一个简单并且可以扩展的方法来解决这些问题。研究的两个具体的应用程序是比较不同网络所学习的表示,并解释了由在深度神经网络隐藏层学习的表示。此外,谷歌大脑团队正在开放源代码,以便研究社区能够对这种方法进行试验。
我们的设置的关键是将深度神经网络中的每个神经元都解释为一个激活向量(activation vector)。如下图所示,神经元的激活向量是它在输入数据上产生的标量输出。例如,对于50个输入图像,一个深度神经网络中的神经元将输出50个标量值,编码它对每个输入的响应。这50个标量值构成了神经元的激活向量。(当然,在实际操作中,我们使用了超过50个输入。)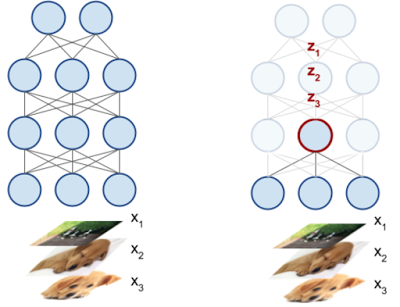
这里有一个深度神经网络,有三个输入,x1,x2,x3。看一下深度神经网络内的神经元(右侧红色的圆圈),这个神经元会产生一个标量输出zi,对应于每个输入xi。这些值构成了神经元的激活向量。
通过这个基本的观察和进一步的阐述,我们引入了奇异向量典型相关分析,这是一种用于两组神经元的技术,并且输出了它们所学习的一致的特征图。关键的是,这种技术可以解释一些表面上的差异,比如神经元排列的置换(permutation),这对于比较不同的网络来说是至关重要的,并且可以检测到相似性,这种相似性比起其它更容易直接失败。
作为一个例子,考虑在CIFAR-10上训练两个卷积神经网络(net1和net2,见下图),这是一个中等规模的图像分类任务。为了使我们的方法的结果可视化,我们将神经元的激活向量与由奇异向量典型相关分析输出的对齐的特征进行比较。回想一下,神经元的激活向量是输入图像上的原始标量输出。图中的x轴是由类排序的图像(灰色的虚线表示类边界),y轴表示神经元的输出值。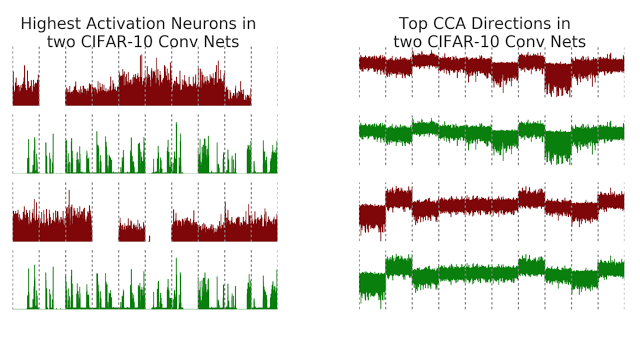
然而,在应用了奇异向量典型相关分析(右图)之后,我们发现两个网络所学习的潜在表示确实有一些非常相似的特性。注意,表示对齐的特征图的前两行几乎是相同的,也就是第二高的对齐的特征图(底部的两行)。此外,右图中的这些对齐的映射也显示了与类边界的清晰的对应关系,例如,我们看到上面的两行对第8类给出了负输出,而下面的两行对第2类和第7类给出了正输出。
虽然你可以跨网络应用奇异向量典型相关分析,但也可以在同一时间内对相同的网络进行相同的处理,以便研究网络中不同层如何聚合到它们的最终表示。下面,我们展示了在net1中,训练(y轴)和训练结束时(x轴)层之间的层表示的图片。例如,在左上角的窗格中(标题为“0% trained”),x轴显示了在100%的训练中增加了深度的层,而y轴显示了在0%的训练中增加了深度的层。每一个(i,j)小方块告诉我们,我在100%的训练中所代表的层的表现是如何与第j层的训练相一致的。输入层位于左下角,并且(如预期的那样)在0%到100%之间是相同的。我们通过训练在几个点进行了比较,分别为0%、35%、75%和100%,用于在CIFAR-10上的卷积网络(上行)和残差网络(下行)。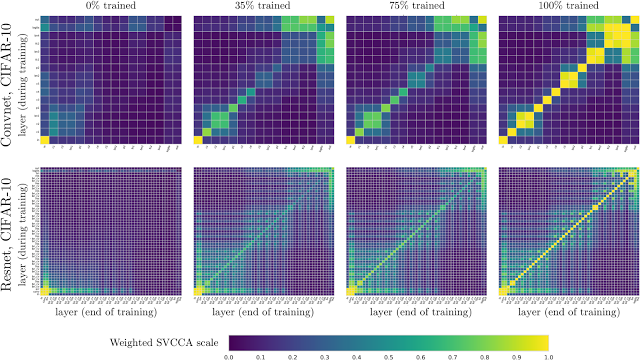
我们发现了自下而上的收敛性的证据,首先,层与输入的聚合更接近,而层越高,收敛的时间就越长。这暗示了一种更快的训练方法——“冻结训练”(Freeze Training)。此外,这种可视化还有助于突出网络的属性。在最上面一行,有两个2x2方块。这些都对应于批处理层,它们与之前的层是相同的。在最后一行,在训练结束的时候,我们可以看到一个类似模式的棋盘图案,这是由于网络的残差连接与以前的层有更大的相似性。
到目前为止,我们已经把奇异向量典型相关分析应用到CIFAR-10上了。但是我们可以将预处理技术应用于离散傅里叶变换(Discrete Fourier transform),这种方法可以扩展到Imagenet大小的模型。我们将此技术应用于Imagenet Resnet,将潜在表示的相似性与对应于不同类的表示相比较:
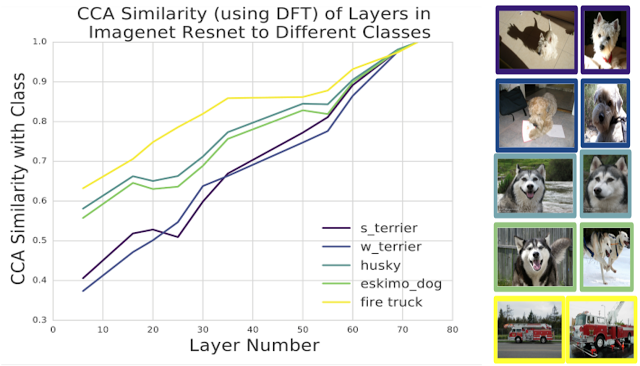
我们在Imagenet Resnet中使用不同的层,其中0表示输入,74表示输出,并比较隐藏层和输出类的表示的相似性。有趣的是,不同的课程以不同的速度学习:消防车类的学习速度比不同的犬种类的学习速度更快。此外,这两种犬类(一对哈士奇和一对西高地梗犬)以相同的速度学习,这反映了它们之间的视觉相似性。
我们上面提到的论文给出了我们迄今为止所探索的结果的更多细节,也涉及到不同的应用,例如通过投影到奇异向量典型相关分析的输出,以及冻结训练。有很多的后续研究,我们都很兴奋地使用奇异向量典型相关分析进行探索——转向不同类型的架构,比较不同的数据集。
我们希望大家打开下面这个代码的链接,它能鼓励很多人将奇异向量典型相关分析应用到他们的网络表达中,以理解他们的网络正在学习什么。
奇异向量典型相关分析(SVCCA),是一个奇异值(SV)分解和典型相关分析(CCA)的合并。谷歌大脑团队曾发表过一篇名为“奇异向量典型相关分析:关于深度学习动力学和解释能力的奇异向量典型相关分析”的论文,文章中引入了一个简单并且可以扩展的方法来解决这些问题。研究的两个具体的应用程序是比较不同网络所学习的表示,并解释了由在深度神经网络隐藏层学习的表示。此外,谷歌大脑团队正在开放源代码,以便研究社区能够对这种方法进行试验。
我们的设置的关键是将深度神经网络中的每个神经元都解释为一个激活向量(activation vector)。如下图所示,神经元的激活向量是它在输入数据上产生的标量输出。例如,对于50个输入图像,一个深度神经网络中的神经元将输出50个标量值,编码它对每个输入的响应。这50个标量值构成了神经元的激活向量。(当然,在实际操作中,我们使用了超过50个输入。)
这里有一个深度神经网络,有三个输入,x1,x2,x3。看一下深度神经网络内的神经元(右侧红色的圆圈),这个神经元会产生一个标量输出zi,对应于每个输入xi。这些值构成了神经元的激活向量。
通过这个基本的观察和进一步的阐述,我们引入了奇异向量典型相关分析,这是一种用于两组神经元的技术,并且输出了它们所学习的一致的特征图。关键的是,这种技术可以解释一些表面上的差异,比如神经元排列的置换(permutation),这对于比较不同的网络来说是至关重要的,并且可以检测到相似性,这种相似性比起其它更容易直接失败。
作为一个例子,考虑在CIFAR-10上训练两个卷积神经网络(net1和net2,见下图),这是一个中等规模的图像分类任务。为了使我们的方法的结果可视化,我们将神经元的激活向量与由奇异向量典型相关分析输出的对齐的特征进行比较。回想一下,神经元的激活向量是输入图像上的原始标量输出。图中的x轴是由类排序的图像(灰色的虚线表示类边界),y轴表示神经元的输出值。
我们在左图展示了net1和net2中两个最高的激活(最大的欧氏规范)神经元。检查最高的激活神经元是在计算机视觉中解释深度神经网络的一种流行方法,但是在这种情况下,net1和net2中最高的激活神经元没有明确的对应关系,尽管它们都接受过相同的任务。
然而,在应用了奇异向量典型相关分析(右图)之后,我们发现两个网络所学习的潜在表示确实有一些非常相似的特性。注意,表示对齐的特征图的前两行几乎是相同的,也就是第二高的对齐的特征图(底部的两行)。此外,右图中的这些对齐的映射也显示了与类边界的清晰的对应关系,例如,我们看到上面的两行对第8类给出了负输出,而下面的两行对第2类和第7类给出了正输出。
虽然你可以跨网络应用奇异向量典型相关分析,但也可以在同一时间内对相同的网络进行相同的处理,以便研究网络中不同层如何聚合到它们的最终表示。下面,我们展示了在net1中,训练(y轴)和训练结束时(x轴)层之间的层表示的图片。例如,在左上角的窗格中(标题为“0% trained”),x轴显示了在100%的训练中增加了深度的层,而y轴显示了在0%的训练中增加了深度的层。每一个(i,j)小方块告诉我们,我在100%的训练中所代表的层的表现是如何与第j层的训练相一致的。输入层位于左下角,并且(如预期的那样)在0%到100%之间是相同的。我们通过训练在几个点进行了比较,分别为0%、35%、75%和100%,用于在CIFAR-10上的卷积网络(上行)和残差网络(下行)。
图中显示了在CIFAR-10上的卷积网络和剩差网络的学习动态。注意,额外的结构也是可见的:由于批量规范层而在顶部行中的2x2方块,以及由于残差连接而在底部行中的棋盘图案。
我们发现了自下而上的收敛性的证据,首先,层与输入的聚合更接近,而层越高,收敛的时间就越长。这暗示了一种更快的训练方法——“冻结训练”(Freeze Training)。此外,这种可视化还有助于突出网络的属性。在最上面一行,有两个2x2方块。这些都对应于批处理层,它们与之前的层是相同的。在最后一行,在训练结束的时候,我们可以看到一个类似模式的棋盘图案,这是由于网络的残差连接与以前的层有更大的相似性。
到目前为止,我们已经把奇异向量典型相关分析应用到CIFAR-10上了。但是我们可以将预处理技术应用于离散傅里叶变换(Discrete Fourier transform),这种方法可以扩展到Imagenet大小的模型。我们将此技术应用于Imagenet Resnet,将潜在表示的相似性与对应于不同类的表示相比较:
- Imagenet Resnet:https://arxiv.org/abs/1512.03385
奇异向量典型相关分析与不同类的潜在表示的相似之处
我们在Imagenet Resnet中使用不同的层,其中0表示输入,74表示输出,并比较隐藏层和输出类的表示的相似性。有趣的是,不同的课程以不同的速度学习:消防车类的学习速度比不同的犬种类的学习速度更快。此外,这两种犬类(一对哈士奇和一对西高地梗犬)以相同的速度学习,这反映了它们之间的视觉相似性。
我们上面提到的论文给出了我们迄今为止所探索的结果的更多细节,也涉及到不同的应用,例如通过投影到奇异向量典型相关分析的输出,以及冻结训练。有很多的后续研究,我们都很兴奋地使用奇异向量典型相关分析进行探索——转向不同类型的架构,比较不同的数据集。
我们希望大家打开下面这个代码的链接,它能鼓励很多人将奇异向量典型相关分析应用到他们的网络表达中,以理解他们的网络正在学习什么。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
嵌入式深度学习:从云端到设备








广告


写评论取消
回复取消