











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






自动机器学习的数据准备要素——分析行业重点
2017年11月30日 由 yining 发表
845804
0
数据准备对于任何分析、商业智能或机器学习工作都是至关重要的。尽管自动机器学习提供了防止常见错误的保护措施,并且足够健壮地来处理不完美的数据,但是你仍然需要适当地准备数据以获得最佳的结果。与其他分析技术不同的是,机器学习算法依赖于精心策划的数据源。你需要在一个广泛的输入变量和结果度量的范围内组织你的数据,这些数据将描述整个事件的整个生命周期。
在这篇文章中,我将描述如何以一种机器学习的格式合并数据,这种格式准确地反映了业务流程和结果。我将分享基本的指导方针和实用的技巧,从而帮你掌握自动机器学习模型数据准备的方法。
与众不同的想法
机器学习的数据准备需要业务领域的专业知识、偏见意识和实验思维过程。在准备数据之前,首先要定义一个业务问题。在这个练习中,你将选择一个结果度量,并对潜在的输入变量进行集体讨论,这些变量会从许多不同的角度影响它。从那里开始,你将开始识别、收集、清洗、整理和取样数据,以运行自动化的机器学习模型过程。
请注意,在现有的事务处理过程之外,相关的机器学习输入数据也不是不常见的。如果是这样的话,你仍然可以使用现有的数据创建第一代机器学习模型,并随着时间的推移继续构建新的模型版本。
机器学习输入数据源
机器学习算法摄取单表、视图或逗号分隔值(.csv)平面文件。如果你的数据存储在多维数据仓库或在事务处理性的、标准化的数据库格式中,你将需要从多个表中联接字段,以创建一个统一的、扁平的机器学习“视图”。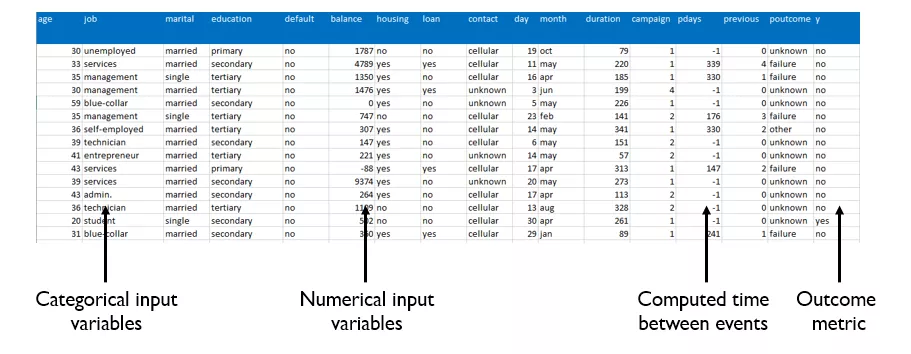 机器学习“视图”包含结果度量,以及输入预测变量,这些变量应该在分析粒度级别上收集,这样你就可以做出可操作的决策。注意不要过度聚集,或是过于复杂的变量设计。选择分析细节的一个既可以理解,也可以用于对模型进行操作的层次。
机器学习“视图”包含结果度量,以及输入预测变量,这些变量应该在分析粒度级别上收集,这样你就可以做出可操作的决策。注意不要过度聚集,或是过于复杂的变量设计。选择分析细节的一个既可以理解,也可以用于对模型进行操作的层次。
10种顶尖的数据准备技巧
即使将来数据清洗和功能工程任务自动化变得更普遍,业务主题的专业知识和数据准备的创造性仍将是关键的模型性能差异。由于自动化机器学习模型的质量取决于输入的质量,所以在这里我将介绍10种数据准备技巧,可以帮助你构建更好的模型。
1.通过预测输出的可执行决策选择粒度的度量级别。
2.预测算法假定每个记录都是独立且不相关的。如果在记录之间存在关系,则创建一个称为特性的新派生变量来捕获数据关系。
3.在选择预测变量时,请记住,从最少数量的变量中收集最大数量的信息,以避免不适应或不匹配的维度。
4.决定如何处理异常值。一些算法,例如回归算法对它们在统计意义计算中的标准偏差非常敏感。确认数据是否相关,是否真实。可以考虑使用转换来减少异常影响。
5.对于缺失值,你可以删除它,或者将它归因于一个可能的或期望的值。如果你把它归因于平均值,你可能会减少你的标准差,因此基于分布的估算方法更可靠。当你处理缺失值时,不要丢失初始上下文(initial context)。常见的一种方法是在行中添加一个列来标记数据丢失。
6.机器学习算法假定输入的信息是正确的。如果只有少数几个值,就把不正确的值当作缺失值。如果有很多不准确的值,试着确定修复它们的过程中会发生什么。
7.在可能的情况下,通过一个变换函数来减少变量的偏差,变换函数对分布的尾部有不成比例的影响。
8.避免使用包含大量不同值的高基数域。
9.不要使用重复的、冗余的或其他高度相关的变量,这些变量携带相同的信息或存在于相同的层次结构中,以避免共线性问题。
10.由于信息增益与这些交互相关,从多个组合变量和比率中创建特性比任何单变量的转换都提供了更多的改进和模型精确度。
在这篇文章中,我将描述如何以一种机器学习的格式合并数据,这种格式准确地反映了业务流程和结果。我将分享基本的指导方针和实用的技巧,从而帮你掌握自动机器学习模型数据准备的方法。
与众不同的想法
机器学习的数据准备需要业务领域的专业知识、偏见意识和实验思维过程。在准备数据之前,首先要定义一个业务问题。在这个练习中,你将选择一个结果度量,并对潜在的输入变量进行集体讨论,这些变量会从许多不同的角度影响它。从那里开始,你将开始识别、收集、清洗、整理和取样数据,以运行自动化的机器学习模型过程。
请注意,在现有的事务处理过程之外,相关的机器学习输入数据也不是不常见的。如果是这样的话,你仍然可以使用现有的数据创建第一代机器学习模型,并随着时间的推移继续构建新的模型版本。
机器学习输入数据源
机器学习算法摄取单表、视图或逗号分隔值(.csv)平面文件。如果你的数据存储在多维数据仓库或在事务处理性的、标准化的数据库格式中,你将需要从多个表中联接字段,以创建一个统一的、扁平的机器学习“视图”。
机器学习“视图”包含结果度量,以及输入预测变量,这些变量应该在分析粒度级别上收集,这样你就可以做出可操作的决策。注意不要过度聚集,或是过于复杂的变量设计。选择分析细节的一个既可以理解,也可以用于对模型进行操作的层次。10种顶尖的数据准备技巧
即使将来数据清洗和功能工程任务自动化变得更普遍,业务主题的专业知识和数据准备的创造性仍将是关键的模型性能差异。由于自动化机器学习模型的质量取决于输入的质量,所以在这里我将介绍10种数据准备技巧,可以帮助你构建更好的模型。
1.通过预测输出的可执行决策选择粒度的度量级别。
2.预测算法假定每个记录都是独立且不相关的。如果在记录之间存在关系,则创建一个称为特性的新派生变量来捕获数据关系。
3.在选择预测变量时,请记住,从最少数量的变量中收集最大数量的信息,以避免不适应或不匹配的维度。
4.决定如何处理异常值。一些算法,例如回归算法对它们在统计意义计算中的标准偏差非常敏感。确认数据是否相关,是否真实。可以考虑使用转换来减少异常影响。
5.对于缺失值,你可以删除它,或者将它归因于一个可能的或期望的值。如果你把它归因于平均值,你可能会减少你的标准差,因此基于分布的估算方法更可靠。当你处理缺失值时,不要丢失初始上下文(initial context)。常见的一种方法是在行中添加一个列来标记数据丢失。
6.机器学习算法假定输入的信息是正确的。如果只有少数几个值,就把不正确的值当作缺失值。如果有很多不准确的值,试着确定修复它们的过程中会发生什么。
7.在可能的情况下,通过一个变换函数来减少变量的偏差,变换函数对分布的尾部有不成比例的影响。
8.避免使用包含大量不同值的高基数域。
9.不要使用重复的、冗余的或其他高度相关的变量,这些变量携带相同的信息或存在于相同的层次结构中,以避免共线性问题。
10.由于信息增益与这些交互相关,从多个组合变量和比率中创建特性比任何单变量的转换都提供了更多的改进和模型精确度。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消