











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






你真的知道什么是随机森林吗?本文是关于随机森林的直观解读
2017年12月07日 由 xiaoshan.xiang 发表
855572
0
对于那些认为随机森林是一种黑箱算法的人来说,这篇文章可以提供不同的观点。我将介绍4种解释方法,这些方法可以帮助我们从随机森林模型中得到一些直观的解释。我还将简要讨论所有这些解释方法背后的伪码。我很快就学会了这个fast.ai。它是USF的MSAN学生的“机器学习的课程”。
在sklearn随机森林中使用model.feature_importances以学习一些重要的特征是很常见的。重要特征意味着这些特征与因变量更紧密相关,并为因变量的变化做出更多贡献。我们通常会给随机森林模型提供尽可能多的特征,并让算法反馈出它发现的最有用的功能列表。但仔细选择合适的特征可以使我们的目标预测更加准确。
计算特征_重要性的思想很简单,但是很好。
1).训练随机森林模型(假设具有正确的超参数)
2).找到模型的预测得分(称为基准分数)
3).发现更多的预测分数p,p是特征的数量,每次随机打乱第i的列特征
4).比较所有的p分数和基准分数。如果随机打乱一些第i列,会影响分数,这意味着我们的模型没有这个特征就很糟糕。
5).删除不影响基准测试分数的特征,并通过减少特征子集重新训练模型。
代码计算特征置信度:
下面的代码将为所有的特征提供一个关于{特征,置信度}的字典。
从零开始的特征置信度的代码:
输出:

在上面的输出中,年制造(YearMade)增加了预测均方差,如果它被关闭,代理将从模型中删除。所以它必须是最重要的特征。
以上结果来源于Kaggle竞赛的数据。
Kaggle竞赛数据链接地址:https://www.kaggle.com/c/bluebook-for-bulldozers
一般来说,当企业想要预测某件事时,他们的最终目标要么是降低成本,要么提高利润。在做出重大的商业决策之前,企业有兴趣评估做出这一决定的风险。但当预测结果是没有置信区间而不是降低风险时,我们可能会不经意地将商业暴露在更大的风险之中。
当我们使用线性模型(通常是基于分布假设的模型)时,比较容易找到我们预测的置信水平。但当涉及到随机森林的置信区间时,它并不是很简单。
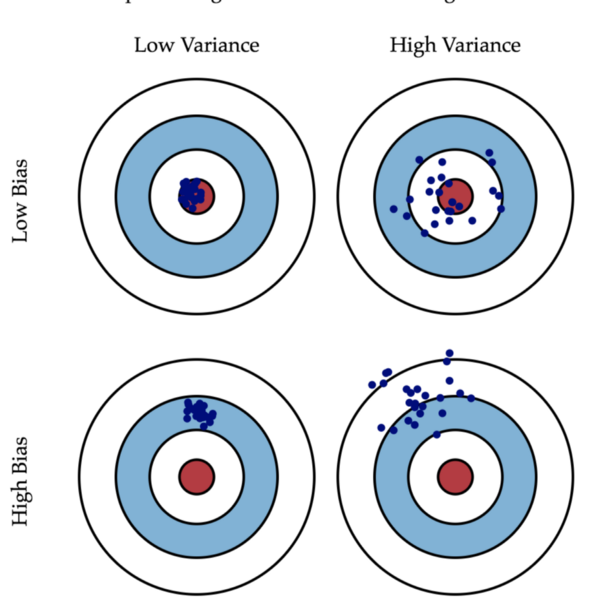
我想,任何使用线性回归类的人都必须看到这个图像(A)。为了找到一个最好的线性模型,我们寻找可以找到最好的偏差权衡[bias-variance tradeoff]的模型。该图像很好地说明了偏差和方差的定义。(这4张图片是4个不同的组合)
如果我们有高偏差和低方差(第三个),我们就会不断地远离中心。相反,如果我们有高方差和低偏差(第二个),结果就是随机的。如果你必须猜测第二个图中下一个点的位置,它可以在中心或者远离它。现在让我们假设在现实生活中发现信用欺诈类似于上面的例子。如果信用公司的预测模型与第二张图的类型相似,那么在大多数情况下,公司都不会发现欺诈行为,尽管平均模型预测是正确的。
结论是,我们不仅要均值预测,还要检查预测的置信度。
怎么做?
随机森林由多个决策树(由n_estimators提供)构成。每棵树分别预测新数据和随机森林通过这些树输出均值预测。预测置信水平的想法只是看新的观察结果对于来自不同决策树的预测有多少变化。然后进一步分析,对于预测变异性最高的观测值,我们可以寻找一些模式(类似于2011年的具有高度变异性的预测)。
基于决策树的预测置信度的源代码:
以上代码的输出如下:

从这个输出中了解到,我们可以说我们对我们对索引14的验证观察的预测是最不自信的。
如果我们想要分析哪些特征对整体随机森林模型很重要,特征置信度(如第1部分)是有用的。但如果我们对某一特定的观察感兴趣,那么树解释器扮演的角色就发挥作用了。
例如,有一种RF模型 - 用来预测将来医院的患者X是否具有很高的再入院概率,为了简单模型,考虑我们仅有的三个特征 - 病人的血压数据,病人的年龄和病人的性别。现在,如果我们的模型说患者A有80%的再次住院概率,那么我们怎么能够知道,我们的模型是通过哪些特殊的情况预测他/她将再次住院。在这种情况下,树解释器会告诉特定患者所遵循的预测路径。类似的,因为患者A是65岁的男性,这就是为什么我们的模型预测他将再次入院。我的模型预测另一个患者B再次入院,可能是因为B有高血压(不是因为年龄或性别)。
基本上,树解释器给出了已知预测的基本分类表(起始节点的数据平均值)和单个节点的贡献。
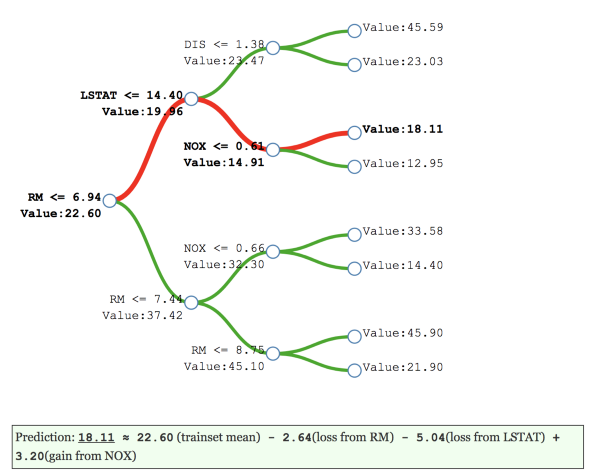
图像(B)的决策树(深度:3)基于波士顿房价数据集。就中间节点的预测值和导致值改变的特征而言,它显示了决策路径的细分。节点的贡献是该节点的值与前一个节点的值的差值。
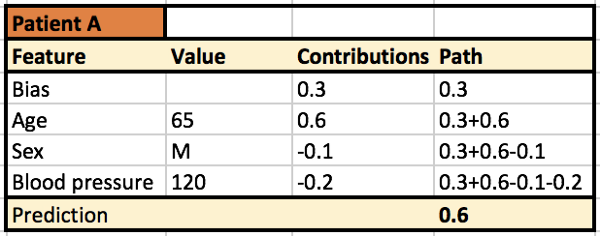
图像(C)给出了对于患者A使用树解释器的示例输出。它说“65岁”是模型预测再入院概率的主要因素。
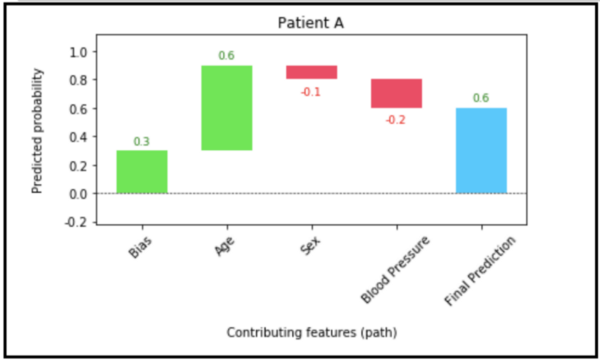
电子表格输出的可视化也可以使用瀑布图(D)来完成。我使用“瀑布图包”中的快速简单的瀑布图来做到这一点。
上面的瀑布图绘制的代码:
术语解释
树解释器包的功能非常简单,可以从每个节点获取贡献,可以在这里探索。
(探索地址:https://pypi.python.org/pypi/treeinterpreter)
在发现了重要特征之后,下一步我们可能会对目标变量与特征之间的直接关系进行研究。线性回归的类比是模型系数。对于线性回归,我们用这样的方式来计算系数,我们可以这样解释:“Y的变化量由X(j)的单位变化量导致,保持所有其他X(i)不变。”
虽然我们有随机森林的特征置信度,但它们只给出了Y相对于X(i)的相对变化。我们不能直接将它们解释为由于X(j)的单位变化量引起的Y的变化量,保持所有其他特征不变。
幸运的是,我们有部分依赖图可以被看作是线性模型系数的图形表示,但也可以扩展到看起来像黑盒模型。这个想法是将预测中所做的改变孤立为一个特定特征。与X和Y的散点图不同,因为散点图不能隔离X对Y的直接关系,并且可能受X和Y所依赖的其他变量间接关系的影响。
制作PDP图的步骤如下:
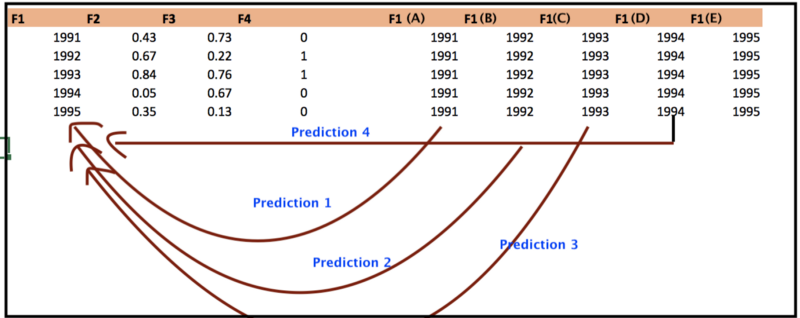
1.训练随机森林模型(比方说F1…F4是我们的特征和Y是目标变量。假设F1是重要特性);
2.我们有兴趣探索Y和F1的直接关系;
3.项目用F1(A)替换列F1,并为所有观察值发现新的预测。采取平均预测。(称之为基值);
4.对F1(B)…F1(E)(即特征F1所有不同的值)重复步骤3;
5.PDP的X轴具有不同的F1值,而Y轴是F1基值的平均预测的变化。
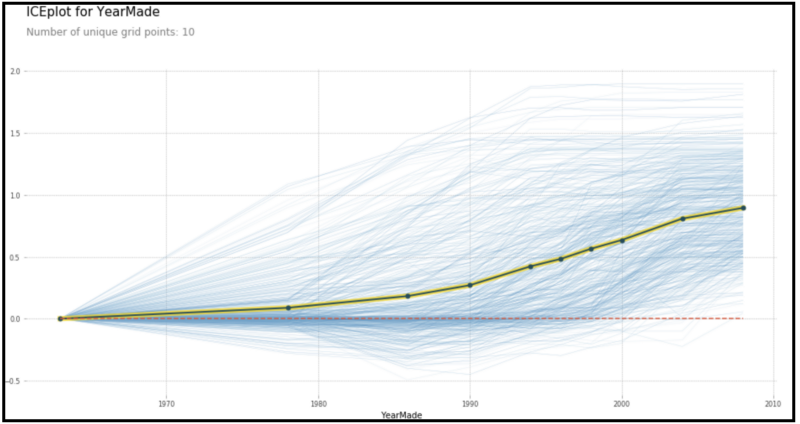
下图(E)是部分依赖图的外观。(在kaggle bulldozer比赛数据上完成)。它显示了年制造(YearMade)和售价的关系。
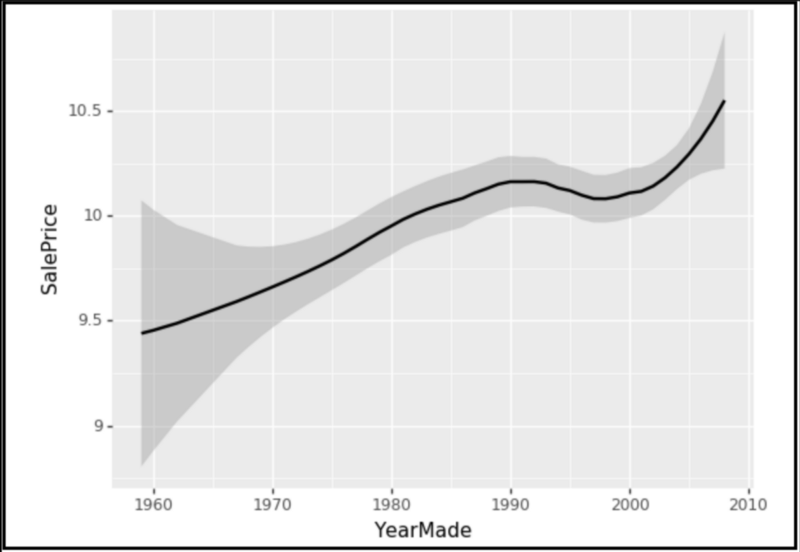
下图(F)是年制造(YearMade)和售价的线绘图。我们可以看到,散点图/线绘图可能无法像PDP那样捕获年制造(YearMade)对售价的直接影响。
rf interpretation notebook地址:https://github.com/fastai/fastai/tree/master/courses/ml1
在大多数情况下,随机森林可以击败线性模型预测。与线性模型相比,随机森林的缺点是于对结果的解释。但我们可以通过讨论来解决错误的反对意见。
1 .我们的特征有多重要?
在sklearn随机森林中使用model.feature_importances以学习一些重要的特征是很常见的。重要特征意味着这些特征与因变量更紧密相关,并为因变量的变化做出更多贡献。我们通常会给随机森林模型提供尽可能多的特征,并让算法反馈出它发现的最有用的功能列表。但仔细选择合适的特征可以使我们的目标预测更加准确。
计算特征_重要性的思想很简单,但是很好。
把思想分解成简单的步骤:
1).训练随机森林模型(假设具有正确的超参数)
2).找到模型的预测得分(称为基准分数)
3).发现更多的预测分数p,p是特征的数量,每次随机打乱第i的列特征
4).比较所有的p分数和基准分数。如果随机打乱一些第i列,会影响分数,这意味着我们的模型没有这个特征就很糟糕。
5).删除不影响基准测试分数的特征,并通过减少特征子集重新训练模型。
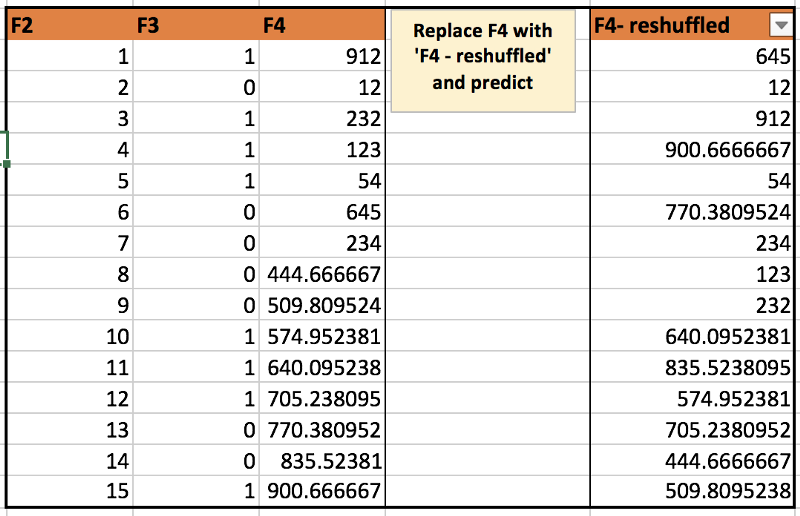 计算特征置信度的电子表格示例。(Shuffle F4,计算预测得分,与基准得分比较。这将赋予F4专栏特征重要性)
计算特征置信度的电子表格示例。(Shuffle F4,计算预测得分,与基准得分比较。这将赋予F4专栏特征重要性)
代码计算特征置信度:
下面的代码将为所有的特征提供一个关于{特征,置信度}的字典。
从零开始的特征置信度的代码:
# defining rmse as scoring criteria (any other criteria can be used in a similar manner)
def score(x1,x2):
return metrics.mean_squared_error(x1,x2)
# defining feature importance function based on above logic
def feat_imp(m, x, y, small_good = True):
"""
m: random forest model
x: matrix of independent variables
y: output variable
small__good: True if smaller prediction score is better
"""
score_list = {}
score_list[‘original’] = score(m.predict(x.values), y)
imp = {}
for i in range(len(x.columns)):
rand_idx = np.random.permutation(len(x)) # randomization
new_coli = x.values[rand_idx, i]
new_x = x.copy()
new_x[x.columns[i]] = new_coli
score_list[x.columns[i]] = score(m.predict(new_x.values), y)
imp[x.columns[i]] = score_list[‘original’] — score_list[x.columns[i]] # comparison with benchmark
if small_good:
return sorted(imp.items(), key=lambda x: x[1])
else: return sorted(imp.items(), key=lambda x: x[1], reverse=True)
输出:
在上面的输出中,年制造(YearMade)增加了预测均方差,如果它被关闭,代理将从模型中删除。所以它必须是最重要的特征。
以上结果来源于Kaggle竞赛的数据。
Kaggle竞赛数据链接地址:https://www.kaggle.com/c/bluebook-for-bulldozers
2.我们对自己的预测有多少自信?
一般来说,当企业想要预测某件事时,他们的最终目标要么是降低成本,要么提高利润。在做出重大的商业决策之前,企业有兴趣评估做出这一决定的风险。但当预测结果是没有置信区间而不是降低风险时,我们可能会不经意地将商业暴露在更大的风险之中。
当我们使用线性模型(通常是基于分布假设的模型)时,比较容易找到我们预测的置信水平。但当涉及到随机森林的置信区间时,它并不是很简单。
A .偏差和方差的图示
我想,任何使用线性回归类的人都必须看到这个图像(A)。为了找到一个最好的线性模型,我们寻找可以找到最好的偏差权衡[bias-variance tradeoff]的模型。该图像很好地说明了偏差和方差的定义。(这4张图片是4个不同的组合)
如果我们有高偏差和低方差(第三个),我们就会不断地远离中心。相反,如果我们有高方差和低偏差(第二个),结果就是随机的。如果你必须猜测第二个图中下一个点的位置,它可以在中心或者远离它。现在让我们假设在现实生活中发现信用欺诈类似于上面的例子。如果信用公司的预测模型与第二张图的类型相似,那么在大多数情况下,公司都不会发现欺诈行为,尽管平均模型预测是正确的。
结论是,我们不仅要均值预测,还要检查预测的置信度。
怎么做?
随机森林由多个决策树(由n_estimators提供)构成。每棵树分别预测新数据和随机森林通过这些树输出均值预测。预测置信水平的想法只是看新的观察结果对于来自不同决策树的预测有多少变化。然后进一步分析,对于预测变异性最高的观测值,我们可以寻找一些模式(类似于2011年的具有高度变异性的预测)。
基于决策树的预测置信度的源代码:
#Pseudo code:
def pred_ci(model, x_val, percentile = 95, n_pnt):
"""
x_val = validation input
percentile = required confidence level
model = random forest model
"""
allTree_preds = np.stack([t.predict(x_val) for t in model.estimators_], axis = 0)
err_down = np.percentile(allTree_preds, (100 - percentile) / 2.0 ,axis=0)
err_up = np.percentile(allTree_preds, 100- (100 - percentile) / 2.0 ,axis=0)
ci = err_up - err_down
yhat = model.predict(x_val)
y = y_val
df = pd.DataFrame()
df['down'] = err_down
df['up'] = err_up
df['y'] = y
df['yhat'] = yhat
df['deviation'] = (df['up'] - df['down'])/df['yhat']
df.reset_index(inplace=True)
df_sorted = df.iloc[np.argsort(df['deviation'])[::-1]]
return df_sorted
以上代码的输出如下:
基于树方差的置信度
从这个输出中了解到,我们可以说我们对我们对索引14的验证观察的预测是最不自信的。
3.预测路径是什么?
如果我们想要分析哪些特征对整体随机森林模型很重要,特征置信度(如第1部分)是有用的。但如果我们对某一特定的观察感兴趣,那么树解释器扮演的角色就发挥作用了。
例如,有一种RF模型 - 用来预测将来医院的患者X是否具有很高的再入院概率,为了简单模型,考虑我们仅有的三个特征 - 病人的血压数据,病人的年龄和病人的性别。现在,如果我们的模型说患者A有80%的再次住院概率,那么我们怎么能够知道,我们的模型是通过哪些特殊的情况预测他/她将再次住院。在这种情况下,树解释器会告诉特定患者所遵循的预测路径。类似的,因为患者A是65岁的男性,这就是为什么我们的模型预测他将再次入院。我的模型预测另一个患者B再次入院,可能是因为B有高血压(不是因为年龄或性别)。
基本上,树解释器给出了已知预测的基本分类表(起始节点的数据平均值)和单个节点的贡献。
B .决策树路径(来源:http://blog.datadive.net/interpreting-random-forests/)
图像(B)的决策树(深度:3)基于波士顿房价数据集。就中间节点的预测值和导致值改变的特征而言,它显示了决策路径的细分。节点的贡献是该节点的值与前一个节点的值的差值。
C .树解释器说明(再次入院的最终概率为0.6)
图像(C)给出了对于患者A使用树解释器的示例输出。它说“65岁”是模型预测再入院概率的主要因素。
D .瀑布图可视化贡献
电子表格输出的可视化也可以使用瀑布图(D)来完成。我使用“瀑布图包”中的快速简单的瀑布图来做到这一点。
上面的瀑布图绘制的代码:
from waterfallcharts import quick_charts as qc
a = [‘Bias’, ‘Age’, ‘Sex’, ‘Blood Pressure’]
b = [0.3, 0.6, -0.1, -0.2]
plot = qc.waterfall(a,b, Title= ‘Patient A’, y_lab= ‘Predicted probability’, x_lab= ‘Contributing features (path)’,
net_label = ‘Final Prediction’)
plot.show()
术语解释
- Value(image B)表示节点预测的目标值。(仅指该节点的目标观测值)。
- 在以前的节点上,贡献值是当前节点的值减去前一个节点值(为路径提供特征贡献)。
- 路径是通过一些观察的特征分割来达到叶节点的组合。
树解释器包的功能非常简单,可以从每个节点获取贡献,可以在这里探索。
(探索地址:https://pypi.python.org/pypi/treeinterpreter)
4.目标变量与重要特征有何关联?(部分依赖情节)
在发现了重要特征之后,下一步我们可能会对目标变量与特征之间的直接关系进行研究。线性回归的类比是模型系数。对于线性回归,我们用这样的方式来计算系数,我们可以这样解释:“Y的变化量由X(j)的单位变化量导致,保持所有其他X(i)不变。”
虽然我们有随机森林的特征置信度,但它们只给出了Y相对于X(i)的相对变化。我们不能直接将它们解释为由于X(j)的单位变化量引起的Y的变化量,保持所有其他特征不变。
幸运的是,我们有部分依赖图可以被看作是线性模型系数的图形表示,但也可以扩展到看起来像黑盒模型。这个想法是将预测中所做的改变孤立为一个特定特征。与X和Y的散点图不同,因为散点图不能隔离X对Y的直接关系,并且可能受X和Y所依赖的其他变量间接关系的影响。
制作PDP图的步骤如下:
1.训练随机森林模型(比方说F1…F4是我们的特征和Y是目标变量。假设F1是重要特性);
2.我们有兴趣探索Y和F1的直接关系;
3.项目用F1(A)替换列F1,并为所有观察值发现新的预测。采取平均预测。(称之为基值);
4.对F1(B)…F1(E)(即特征F1所有不同的值)重复步骤3;
5.PDP的X轴具有不同的F1值,而Y轴是F1基值的平均预测的变化。
PDP逻辑的电子表格说明
下图(E)是部分依赖图的外观。(在kaggle bulldozer比赛数据上完成)。它显示了年制造(YearMade)和售价的关系。
E .部分依赖图(年制造vs.售价的变化)
下图(F)是年制造(YearMade)和售价的线绘图。我们可以看到,散点图/线绘图可能无法像PDP那样捕获年制造(YearMade)对售价的直接影响。
F.以上两个情节的来源是fast.ai的rf interpretation notebook
rf interpretation notebook地址:https://github.com/fastai/fastai/tree/master/courses/ml1
结束注释:
在大多数情况下,随机森林可以击败线性模型预测。与线性模型相比,随机森林的缺点是于对结果的解释。但我们可以通过讨论来解决错误的反对意见。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消