











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






不怕学不会 使用TensorFlow从零开始构建卷积神经网络
2017年12月12日 由 yuxiangyu 发表
435262
0
人们可以使用TensorFlow的所有高级工具如tf.contrib.learn和Keras,能够用少量代码轻易的建立一个卷积神经网络。但是通常在这种高级应用中,你不能访问代码中的部分内容,对深层次的原理缺乏理解。
在本教程中,我将介绍如何从零开始使用底层的TensorFlow构建卷积神经网络,并使用TensorBoard可视化我们的函数图像和网络性能。本教程需要你了解神经网络的一些基础知识。在整篇文章中,我还将把卷积神经网络的每一步都分解为绝对的基础知识,以便你可以充分理解图中每一步发生的情况。通过从头开始构建这个模型,你可以轻松将图形的不同方面可视化,这样你就可以看到每个卷积层并使用它们进行自己的推论。我只会着重讲代码的重要的部分,想获取要详细代码和注释,请访问下方链接。
https://github.com/wagonhelm/Visualizing-Convnets/blob/master/visualizingConvnets.ipynb
首先,我必须决定使用哪个图像数据集。我决定使用牛津大学Visual Geometry Group的宠物数据集。我选择这个数据集有几个原因:这个数据集比较简单,并且标记得很好,它有适当数量的训练数据,如果我接下来想训练一个检测模型,它也有可用包围盒。或者你也可以使用我在Kaggle上找到的Simpsons数据集,它包含大量可用来训练的简单数据。
接下来,我要选择卷积神经网络模型。比较流行的模型是GoogLeNet或VGG16,它们都具有多重卷积,可用于用于检测ImageNet中1000种数据集的图像。我决定建立一个简单的四层卷积网络:

让我们详细讲解这个模型的构成,根据前三个通道被卷积到32个特征映射。我们接下来卷积这组32个特征映射组成另外32个特征。然后将其池化为一个112x112x32的图像,然后我们卷积64特征映射两次之后,最终池化为56x56x64。这个最后的池化层的每个单元然后被全连接到512个神经元,然后根据类的数量接通softmax层。
首先,让我们开始加载我们的依赖项,其中包括用于处理图像数据的函数imFunctions。
使用imFunctions下载和提取图片。
然后,我们可以将图像分类到单独的文件夹中,包括训练和测试文件夹。sortImages函数中的数字表示你想从训练数据中分离出测试数据的百分比。
然后,我们可以将数据集构建为一个numpy数组,其中对应的独热向量表示我们的类。当构建convnet时,这也将减少所有的训练和测试图像中的图像均值。这个函数会问你想要包含哪些类,由于我的GPU内存有限(3GB),我选择了一个非常小的数据集,试图区分两种狗:柴犬和萨摩耶。
现在我们有了一套数据集,让我们稍微回顾一下,看看卷积的工作原理。在学习彩色卷积滤波器之前,让我们看一下灰度图。我们来做一个7x7的滤波器,应用四个不同的特征映射。TensorFlow的conv2d功能相当简单,并有四个变量:input,filter,strides和padding。在TensorFlow网站上,他们描述的conv2d功能如下:
由于我们正在处理的是灰度图,因此in_channels是1,因为我们应用了四个滤波器,所以out_channels是4.我们将以下四个滤波器/内核应用于我们的一个图像(或者说batch为1):

让我们看看滤波器如何影响我们的灰度图像输入。
这将返回一个(1,224,224,4)的4维张量,我们可以用它来可视化四个滤波器:

很明显看到滤波器内核的卷积非常强大。为了将其分解,我们的7x7内核每次每步跨越图像49个像素,然后将每个像素的值乘以每个内核值,然后将所有49个值加在一起以构成一个像素。(如果你仍然不理解图像滤波的核心,访问链接http://setosa.io/ev/image-kernels/)
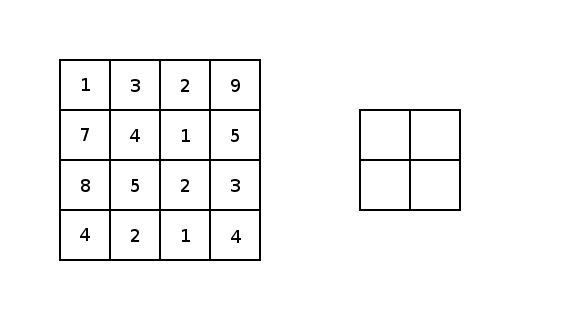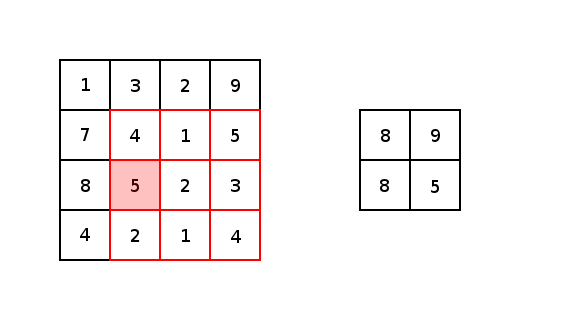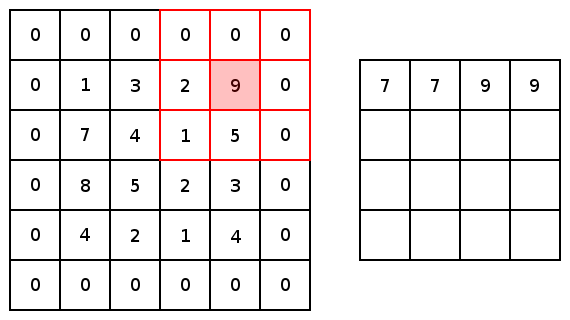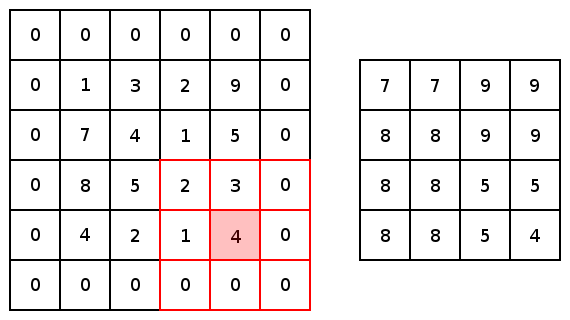
本质上,大多数卷积神经网络都是由卷积和池化构成的。被用于卷积最常见的是3x3内核滤波器。特别是,带有2×2的步幅和2×2的池化核大小的最大池化是一种非常激进的方法,可以根据在内核中的最大像素值缩小图片尺寸。以下为它的示例。
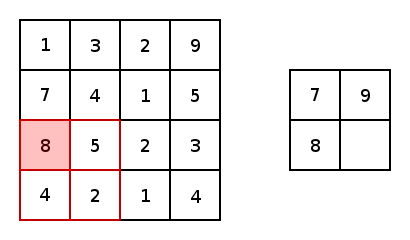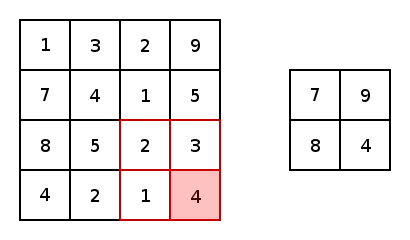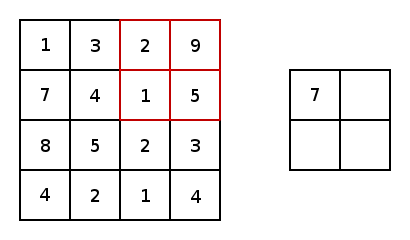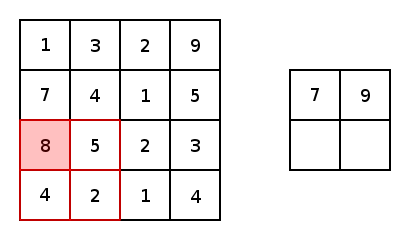
现在,对于两个conv2d和最大池化,有两个选项可以选择填充:“VALID”,这将缩小输入和“SAME”,通过在输入边缘周围添加零来保持输入大小。这里是一个3x3内核的最大池化的示例,使用1x1的步幅来比较填充选项:
现在我们已经介绍了所有的基础知识,可以开始构建自己的卷积神经网络模型了。我们可以从占位符开始。X将是我们的输入占位符,我们将把我们的图像馈入,Y_是一组图像的真实类别。
我们将在一个范围内为每个过程创建所有部分。Scope对于在TensorBoard中可视化图形是非常有用的,因为它们将所有东西都组合成一个可扩展的对象。我们创建了第一组内核大小为3x3的滤波器,这个滤波器需要三个通道并输出32个滤波器。这意味着对于32个滤波器中的每一个,R,G和B通道将会有3x3的内核权重。我们的滤波器的权重值使用截尾正态分布初始化非常重要,所以我们有多个随机滤波器,使TensorFlow适应我们的模型。
在第一次卷积
然后,我们把图像缩小一半。
最后一部分涉及在池层上使用dropout(我们稍后详细介绍)。然后我们再来两次卷积,这样就有64个特征和另一个池。请注意,第一个卷积必须将先前的32个特征通道转换为64。
接下来,我们创建一个512个神经元的完全连接层,它将为我们的56x56x64的pool2_1层的每个像素建立一个权重连接。这是超过1亿不同的权重值!为了计算我们完全连接网络,我们必须把输入降至一维,然后乘以权重,再加上偏置。
最后,我们得到带有关联权重和偏置的softmax,最后输出Y.
现在,我们可以开始开发我们模型的训练方面。首先,我们必须决定批处理大小;我不能使用超过10个,因为GPU内存不足。然后,我们必须决定训练次数,即算法循环遍历所有训练数据的次数,最后决定我们的学习速率alpha。
然后,我们为交叉熵,准确性检查和反向传播优化创建范围。
然后,我们可以创建我们的会话并初始化所有的变量。
现在,我们也要使用TensorBoard,这样我们可以看到我们的分类器的工作效果。我们将创建两个图:一个用于我们的训练集,一个用于我们的测试集。我们可以通过使用add_graph函数来显示我们的图形网络。我们将使用摘要标量来衡量我们的总体损失和准确性,将我们的摘要合并到一起,这样我们只需要调用write_op记录我们的标量。
然后我们可以编码进行评估和训练。我不希望每步都记录损失和准确性,因为这会大大减慢分类器的速度。所以,我们每五步记录一次。
在训练中,通过在终端中激活TensorBoard来检查TensorBoard结果。
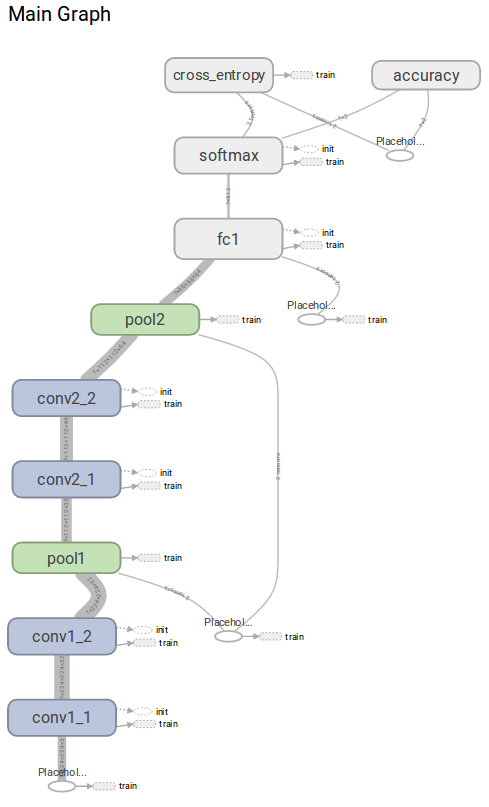
然后,我们可以将我们的Web浏览器指向默认的TensorBoard地址http://0.0.0.0/6006。我们先来看看我们的图表模型。
正如你所看到的,通过使用范围,我们得到了完美的可视化的图形。
让我们来看看准确性和损失的标量历史记录。
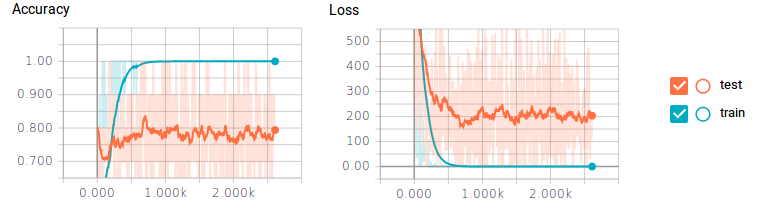
你可能发现,这个图反应了一个很大的问题。我们的训练数据,分类器获得了100%的准确性和0损失,但是我们的测试数据最多只能达到80%的准确性,损失也很大。这是典型的过拟合现象,可能的原因包括没有足够的训练数据或神经元过多。
我们可以通过调整,缩放和旋转我们的训练数据来创建更多的训练数据,但是更简单的方法是添加dropout到池化和完全连接的层的输出中。这将使每个训练步骤完全切割,在层中随机丢弃一部分神经元。这将迫使我们的分类器每次只训练一小组神经元,而非整个集合。这让神经元专注于特定的任务。剔除80%的卷积层和50%完全连接层效果非常好。
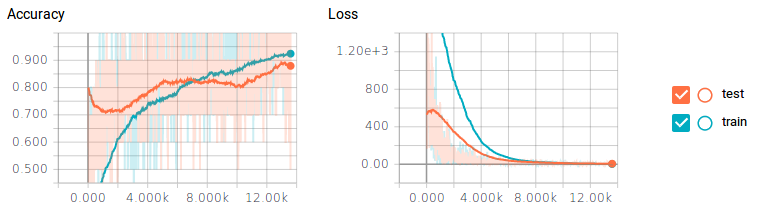
通过减少神经元,我们能够达到90%的测试准确性,几乎是10%的性能增长!但缺点是分类器花了大约6倍的时间来训练。
为了好玩,每50个训练步骤,我通过滤波器传递一个图像,把滤波器的权重进化做成一个gif。它的效果很酷,并我们可以通过它对卷积网络的工作方式有更好的认识。以下是两个滤波器来自conv1_2:
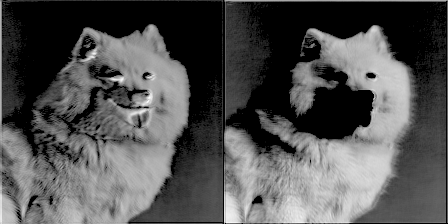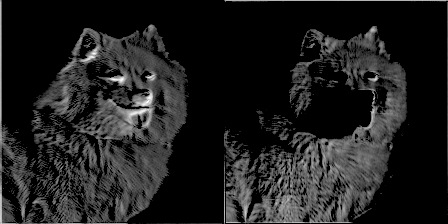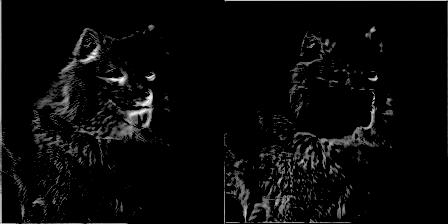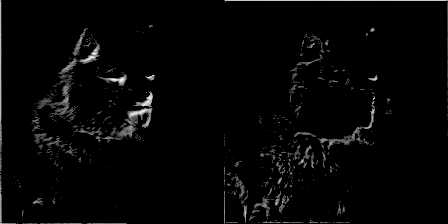
你可以看到最初的权重初始化显示了图像很多细节,但随着时间的推移权重更新,他们变得更加专注于检测某些边缘。令我吃惊的是,我发现第一个卷积核filter1_1几乎没有变化。似乎初始权重初始化本身已经足够好了。我们继续深入,在conv2_2中你可以看到它开始检测更抽象和普遍的特征。

总而言之,使用少于400个训练图像进行训练,训练后准确性几乎可以达到90%,这给我留下了深刻的印象。我相信,如果有更多的训练数据,更多的超参数调整,我可以取得更好的结果。
这篇文章总结了如何使用TensorFlow从零开始创建卷积神经网络,以及如何从TensorBoard获取推论以及如何使我们的滤波器可视化。重点记住,使用少量数据制作分类器时,更容易的方法取一个已经使用多个GPU进行训练的大型数据集的模型和权重(如GoogLeNet或VGG16),并截断最后一层并用他们自己的分类器替换它们。然后,分类器所要做的就是学习最后一层的权重,并使用预先存在的训练过的已有的滤波器权重。
在本教程中,我将介绍如何从零开始使用底层的TensorFlow构建卷积神经网络,并使用TensorBoard可视化我们的函数图像和网络性能。本教程需要你了解神经网络的一些基础知识。在整篇文章中,我还将把卷积神经网络的每一步都分解为绝对的基础知识,以便你可以充分理解图中每一步发生的情况。通过从头开始构建这个模型,你可以轻松将图形的不同方面可视化,这样你就可以看到每个卷积层并使用它们进行自己的推论。我只会着重讲代码的重要的部分,想获取要详细代码和注释,请访问下方链接。
https://github.com/wagonhelm/Visualizing-Convnets/blob/master/visualizingConvnets.ipynb
收集数据集
首先,我必须决定使用哪个图像数据集。我决定使用牛津大学Visual Geometry Group的宠物数据集。我选择这个数据集有几个原因:这个数据集比较简单,并且标记得很好,它有适当数量的训练数据,如果我接下来想训练一个检测模型,它也有可用包围盒。或者你也可以使用我在Kaggle上找到的Simpsons数据集,它包含大量可用来训练的简单数据。
选择一个模型
接下来,我要选择卷积神经网络模型。比较流行的模型是GoogLeNet或VGG16,它们都具有多重卷积,可用于用于检测ImageNet中1000种数据集的图像。我决定建立一个简单的四层卷积网络:
让我们详细讲解这个模型的构成,根据前三个通道被卷积到32个特征映射。我们接下来卷积这组32个特征映射组成另外32个特征。然后将其池化为一个112x112x32的图像,然后我们卷积64特征映射两次之后,最终池化为56x56x64。这个最后的池化层的每个单元然后被全连接到512个神经元,然后根据类的数量接通softmax层。
处理和建立一个数据集
首先,让我们开始加载我们的依赖项,其中包括用于处理图像数据的函数imFunctions。
import imFunctions as imf
import tensorflow as tf
import scipy.ndimage
from scipy.misc import imsave
import matplotlib.pyplot as plt
import numpy as np
使用imFunctions下载和提取图片。
imf.downloadImages('annotations.tar.gz', 19173078)
imf.downloadImages('images.tar.gz', 791918971)
imf.maybeExtract('annotations.tar.gz')
imf.maybeExtract('images.tar.gz')然后,我们可以将图像分类到单独的文件夹中,包括训练和测试文件夹。sortImages函数中的数字表示你想从训练数据中分离出测试数据的百分比。
imf.sortImages(0.15)
然后,我们可以将数据集构建为一个numpy数组,其中对应的独热向量表示我们的类。当构建convnet时,这也将减少所有的训练和测试图像中的图像均值。这个函数会问你想要包含哪些类,由于我的GPU内存有限(3GB),我选择了一个非常小的数据集,试图区分两种狗:柴犬和萨摩耶。
train_x, train_y, test_x, test_y, classes, classLabels = imf.buildDataset()
卷积和汇集如何工作
现在我们有了一套数据集,让我们稍微回顾一下,看看卷积的工作原理。在学习彩色卷积滤波器之前,让我们看一下灰度图。我们来做一个7x7的滤波器,应用四个不同的特征映射。TensorFlow的conv2d功能相当简单,并有四个变量:input,filter,strides和padding。在TensorFlow网站上,他们描述的conv2d功能如下:
计算给定四维输入和滤波张量的二维卷积。
给定形状的输入张量[batch,in_height,in_width,in_channels]和形状为[filter_height,filter_width,in_channels,out_channels]的滤波器/内核张量。
由于我们正在处理的是灰度图,因此in_channels是1,因为我们应用了四个滤波器,所以out_channels是4.我们将以下四个滤波器/内核应用于我们的一个图像(或者说batch为1):
让我们看看滤波器如何影响我们的灰度图像输入。
gray = np.mean(image,-1)
X = tf.placeholder(tf.float32, shape=(None, 224, 224, 1))
conv = tf.nn.conv2d(X, filters, [1,1,1,1], padding="SAME")
test = tf.Session()
test.run(tf.global_variables_initializer())
filteredImage = test.run(conv, feed_dict={X: gray.reshape(1,224,224,1)})
tf.reset_default_graph()
这将返回一个(1,224,224,4)的4维张量,我们可以用它来可视化四个滤波器:
很明显看到滤波器内核的卷积非常强大。为了将其分解,我们的7x7内核每次每步跨越图像49个像素,然后将每个像素的值乘以每个内核值,然后将所有49个值加在一起以构成一个像素。(如果你仍然不理解图像滤波的核心,访问链接http://setosa.io/ev/image-kernels/)
本质上,大多数卷积神经网络都是由卷积和池化构成的。被用于卷积最常见的是3x3内核滤波器。特别是,带有2×2的步幅和2×2的池化核大小的最大池化是一种非常激进的方法,可以根据在内核中的最大像素值缩小图片尺寸。以下为它的示例。
现在,对于两个conv2d和最大池化,有两个选项可以选择填充:“VALID”,这将缩小输入和“SAME”,通过在输入边缘周围添加零来保持输入大小。这里是一个3x3内核的最大池化的示例,使用1x1的步幅来比较填充选项:
创建ConvNet
现在我们已经介绍了所有的基础知识,可以开始构建自己的卷积神经网络模型了。我们可以从占位符开始。X将是我们的输入占位符,我们将把我们的图像馈入,Y_是一组图像的真实类别。
X = tf.placeholder(tf.float32, shape=(None, 224, 224, 3))
Y_ = tf.placeholder(tf.float32, [None, classes])
keepRate1 = tf.placeholder(tf.float32)
keepRate2 = tf.placeholder(tf.float32)
我们将在一个范围内为每个过程创建所有部分。Scope对于在TensorBoard中可视化图形是非常有用的,因为它们将所有东西都组合成一个可扩展的对象。我们创建了第一组内核大小为3x3的滤波器,这个滤波器需要三个通道并输出32个滤波器。这意味着对于32个滤波器中的每一个,R,G和B通道将会有3x3的内核权重。我们的滤波器的权重值使用截尾正态分布初始化非常重要,所以我们有多个随机滤波器,使TensorFlow适应我们的模型。
# CONVOLUTION 1 - 1
with tf.name_scope('conv1_1'):
filter1_1 = tf.Variable(tf.truncated_normal([3, 3, 3, 32], dtype=tf.float32,
stddev=1e-1), name='weights1_1')
stride = [1,1,1,1]
conv = tf.nn.conv2d(X, filter1_1, stride, padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[32], dtype=tf.float32),
trainable=True, name='biases1_1')
out = tf.nn.bias_add(conv, biases)
conv1_1 = tf.nn.relu(out)
在第一次卷积
conv1_1结束时,我们使用relu进行处理,它将每个负数归零。然后,我们将这32个特征卷积到另外的32个特征中。可以看到,conv2d将输入赋值为第一个卷积层的输出。# CONVOLUTION 1 - 2
with tf.name_scope('conv1_2'):
filter1_2 = tf.Variable(tf.truncated_normal([3, 3, 32, 32], dtype=tf.float32,
stddev=1e-1), name='weights1_2')
conv = tf.nn.conv2d(conv1_1, filter1_2, [1,1,1,1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[32], dtype=tf.float32),
trainable=True, name='biases1_2')
out = tf.nn.bias_add(conv, biases)
conv1_2 = tf.nn.relu(out)
然后,我们把图像缩小一半。
# POOL 1
with tf.name_scope('pool1'):
pool1_1 = tf.nn.max_pool(conv1_2,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
name='pool1_1')
pool1_1_drop = tf.nn.dropout(pool1_1, keepRate1)
最后一部分涉及在池层上使用dropout(我们稍后详细介绍)。然后我们再来两次卷积,这样就有64个特征和另一个池。请注意,第一个卷积必须将先前的32个特征通道转换为64。
# CONVOLUTION 2 - 1
with tf.name_scope('conv2_1'):
filter2_1 = tf.Variable(tf.truncated_normal([3, 3, 32, 64], dtype=tf.float32,
stddev=1e-1), name='weights2_1')
conv = tf.nn.conv2d(pool1_1_drop, filter2_1, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases2_1')
out = tf.nn.bias_add(conv, biases)
conv2_1 = tf.nn.relu(out)
# CONVOLUTION 2 - 2
with tf.name_scope('conv2_2'):
filter2_2 = tf.Variable(tf.truncated_normal([3, 3, 64, 64], dtype=tf.float32,
stddev=1e-1), name='weights2_2')
conv = tf.nn.conv2d(conv2_1, filter2_2, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64], dtype=tf.float32),
trainable=True, name='biases2_2')
out = tf.nn.bias_add(conv, biases)
conv2_2 = tf.nn.relu(out)
# POOL 2
with tf.name_scope('pool2'):
pool2_1 = tf.nn.max_pool(conv2_2,
ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1],
padding='SAME',
name='pool2_1')
pool2_1_drop = tf.nn.dropout(pool2_1, keepRate1)
接下来,我们创建一个512个神经元的完全连接层,它将为我们的56x56x64的pool2_1层的每个像素建立一个权重连接。这是超过1亿不同的权重值!为了计算我们完全连接网络,我们必须把输入降至一维,然后乘以权重,再加上偏置。
#FULLY CONNECTED 1
with tf.name_scope('fc1') as scope:
shape = int(np.prod(pool2_1_drop.get_shape()[1:]))
fc1w = tf.Variable(tf.truncated_normal([shape, 512], dtype=tf.float32,
stddev=1e-1), name='weights3_1')
fc1b = tf.Variable(tf.constant(1.0, shape=[512], dtype=tf.float32),
trainable=True, name='biases3_1')
pool2_flat = tf.reshape(pool2_1_drop, [-1, shape])
out = tf.nn.bias_add(tf.matmul(pool2_flat, fc1w), fc1b)
fc1 = tf.nn.relu(out)
fc1_drop = tf.nn.dropout(fc1, keepRate2)
最后,我们得到带有关联权重和偏置的softmax,最后输出Y.
#FULLY CONNECTED 3 & SOFTMAX OUTPUT
with tf.name_scope('softmax') as scope:
fc2w = tf.Variable(tf.truncated_normal([512, classes], dtype=tf.float32,
stddev=1e-1), name='weights3_2')
fc2b = tf.Variable(tf.constant(1.0, shape=[classes], dtype=tf.float32),
trainable=True, name='biases3_2')
Ylogits = tf.nn.bias_add(tf.matmul(fc1_drop, fc2w), fc2b)
Y = tf.nn.softmax(Ylogits)
创建损失和优化
现在,我们可以开始开发我们模型的训练方面。首先,我们必须决定批处理大小;我不能使用超过10个,因为GPU内存不足。然后,我们必须决定训练次数,即算法循环遍历所有训练数据的次数,最后决定我们的学习速率alpha。
numEpochs = 400
batchSize = 10
alpha = 1e-5
然后,我们为交叉熵,准确性检查和反向传播优化创建范围。
with tf.name_scope('cross_entropy'):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=Ylogits, labels=Y_)
loss = tf.reduce_mean(cross_entropy)
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(Y, 1), tf.argmax(Y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate=alpha).minimize(loss)然后,我们可以创建我们的会话并初始化所有的变量。
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
为TensorBoard创建摘要
现在,我们也要使用TensorBoard,这样我们可以看到我们的分类器的工作效果。我们将创建两个图:一个用于我们的训练集,一个用于我们的测试集。我们可以通过使用add_graph函数来显示我们的图形网络。我们将使用摘要标量来衡量我们的总体损失和准确性,将我们的摘要合并到一起,这样我们只需要调用write_op记录我们的标量。
writer_1 = tf.summary.FileWriter("/tmp/cnn/train")
writer_2 = tf.summary.FileWriter("/tmp/cnn/test")
writer_1.add_graph(sess.graph)
tf.summary.scalar('Loss', loss)
tf.summary.scalar('Accuracy', accuracy)
tf.summary.histogram("weights1_1", filter1_1)
write_op = tf.summary.merge_all()训练模型
然后我们可以编码进行评估和训练。我不希望每步都记录损失和准确性,因为这会大大减慢分类器的速度。所以,我们每五步记录一次。
steps = int(train_x.shape[0]/batchSize)
for i in range(numEpochs):
accHist = []
accHist2 = []
train_x, train_y = imf.shuffle(train_x, train_y)
for ii in range(steps):
#Calculate our current step
step = i * steps + ii
#Feed forward batch of train images into graph and log accuracy
acc = sess.run([accuracy], feed_dict={X: train_x[(ii*batchSize):((ii+1)*batchSize),:,:,:], Y_: train_y[(ii*batchSize):((ii+1)*batchSize)], keepRate1: 1, keepRate2: 1})
accHist.append(acc)
if step % 5 == 0:
# Get Train Summary for one batch and add summary to TensorBoard
summary = sess.run(write_op, feed_dict={X: train_x[(ii*batchSize):((ii+1)*batchSize),:,:,:], Y_: train_y[(ii*batchSize):((ii+1)*batchSize)], keepRate1: 1, keepRate2: 1})
writer_1.add_summary(summary, step)
writer_1.flush()
# Get Test Summary on random 10 test images and add summary to TensorBoard
test_x, test_y = imf.shuffle(test_x, test_y)
summary = sess.run(write_op, feed_dict={X: test_x[0:10,:,:,:], Y_: test_y[0:10], keepRate1: 1, keepRate2: 1})
writer_2.add_summary(summary, step)
writer_2.flush()
#Back propigate using adam optimizer to update weights and biases.
sess.run(train_step, feed_dict={X: train_x[(ii*batchSize):((ii+1)*batchSize),:,:,:], Y_: train_y[(ii*batchSize):((ii+1)*batchSize)], keepRate1: 0.2, keepRate2: 0.5})
print('Epoch number {} Training Accuracy: {}'.format(i+1, np.mean(accHist)))
#Feed forward all test images into graph and log accuracy
for iii in range(int(test_x.shape[0]/batchSize)):
acc = sess.run(accuracy, feed_dict={X: test_x[(iii*batchSize):((iii+1)*batchSize),:,:,:], Y_: test_y[(iii*batchSize):((iii+1)*batchSize)], keepRate1: 1, keepRate2: 1})
accHist2.append(acc)
print("Test Set Accuracy: {}".format(np.mean(accHist2)))
可视化图表
在训练中,通过在终端中激活TensorBoard来检查TensorBoard结果。
tensorboard --logdir="/tmp/cnn/"
然后,我们可以将我们的Web浏览器指向默认的TensorBoard地址http://0.0.0.0/6006。我们先来看看我们的图表模型。
正如你所看到的,通过使用范围,我们得到了完美的可视化的图形。
测试性能
让我们来看看准确性和损失的标量历史记录。
你可能发现,这个图反应了一个很大的问题。我们的训练数据,分类器获得了100%的准确性和0损失,但是我们的测试数据最多只能达到80%的准确性,损失也很大。这是典型的过拟合现象,可能的原因包括没有足够的训练数据或神经元过多。
我们可以通过调整,缩放和旋转我们的训练数据来创建更多的训练数据,但是更简单的方法是添加dropout到池化和完全连接的层的输出中。这将使每个训练步骤完全切割,在层中随机丢弃一部分神经元。这将迫使我们的分类器每次只训练一小组神经元,而非整个集合。这让神经元专注于特定的任务。剔除80%的卷积层和50%完全连接层效果非常好。
通过减少神经元,我们能够达到90%的测试准确性,几乎是10%的性能增长!但缺点是分类器花了大约6倍的时间来训练。
可视化进化滤波器
为了好玩,每50个训练步骤,我通过滤波器传递一个图像,把滤波器的权重进化做成一个gif。它的效果很酷,并我们可以通过它对卷积网络的工作方式有更好的认识。以下是两个滤波器来自conv1_2:
你可以看到最初的权重初始化显示了图像很多细节,但随着时间的推移权重更新,他们变得更加专注于检测某些边缘。令我吃惊的是,我发现第一个卷积核filter1_1几乎没有变化。似乎初始权重初始化本身已经足够好了。我们继续深入,在conv2_2中你可以看到它开始检测更抽象和普遍的特征。
总而言之,使用少于400个训练图像进行训练,训练后准确性几乎可以达到90%,这给我留下了深刻的印象。我相信,如果有更多的训练数据,更多的超参数调整,我可以取得更好的结果。
这篇文章总结了如何使用TensorFlow从零开始创建卷积神经网络,以及如何从TensorBoard获取推论以及如何使我们的滤波器可视化。重点记住,使用少量数据制作分类器时,更容易的方法取一个已经使用多个GPU进行训练的大型数据集的模型和权重(如GoogLeNet或VGG16),并截断最后一层并用他们自己的分类器替换它们。然后,分类器所要做的就是学习最后一层的权重,并使用预先存在的训练过的已有的滤波器权重。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消