











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






三天内NIPS 2017会议都发生了什么 一文带你看透全程亮点
2017年12月08日 由 xiaoshan.xiang 发表
948898
0
NIPS在本周三启动了,它打破了之前所有的记录。这次会议有8000多名与会者,似乎还有不断增长的趋势。本届NIPS共安排了9个Tutorial,涵盖多领域的主题,使每个人都能够感受到各个领域的最新发展。以下是关于本次会议一些关键性总结。
Nando de Freitas, Scott Rees, Oriol Vinyals
这篇演讲对深度学习当前的状态和最近的进展进行了深入的概述。卷积神经网络(CNN)和自回归模型开始在生产中广泛使用,显示了从研究到工业的快速转变。这些模型告诉我们引入感应偏压,如平移不变性(CNN)或时间递归(递归神经网络)是非常有用的。我们还发现,诸如残差网络或注意力等简单的“技巧”可以带来巨大的性能飞跃。有充分的理由相信我们会找到更多这样的“技巧”。展望未来,有几个令人兴奋的研究领域被提及:
CycleGAN论文地址:https://arxiv.org/abs/1703.10593
DiscoGAN论文地址:https://arxiv.org/abs/1703.05192
RobustFill论文地址:https://arxiv.org/pdf/1703.07469.pdf
Josh Tenenbaum, Vikash K Mansinghka
当今许多人工智能技术依赖于模式识别。然而,作者认为,智能不仅限于此,它包括解释世界,想象可能的后果,并建立一个解决问题的计划。为了弥合这一差距,他们提出了两个问题:
作者描述了一个直观的物理引擎,它成功地预测了塔块掉落的方向。这些通过创建一个模拟世界来进行工作的模型,可以很好并且可以很容易地扩展来回答其他问题,例如,如果某些块比其他块重,会发生什么?
直观物理引擎地址:http://www.pnas.org/content/110/45/18327.abstract
这种“常识”的方法可以让我们从更少的例子中学习现代的深度学习,并减少边缘案例。
Solon Barocas, Moritz Hardt
在机器学习过程中,道德困境比比皆是,但与自动驾驶汽车和具备人类级别的人工玩家的惊人报道相比,这类难题往往得不到关注。本教程对机器学习算法可以区分受保护类别的多种方式进行了精辟的批评,例如由于像制止和盘查这样的制度性政策而对不平衡采样进行训练,对有偏差的历史数据进行训练,或者仅仅不考虑少数文字类。 在这个概述之后,正式定义把这些问题放在一个易处理的格式中。示例和细节详见网址https://research.google.com/bigpicture/attacking-discrimination-in-ml/。
因果推理提供了另一种分析歧视的工具,但对于理解因果关系,却很少存在转钥式解决方案。也许最有趣的观察是,量度是模型本身。我们不能测量“智力”,但我们可以测量智商。我们不能衡量“置信度”,但我们可以衡量信用评分。这些措施只是代理,并建立在很少给予他们应有关注的偏见和假设之上。
最终,如果我们想确保我们不让歧视进入我们的模型,我们就需要让人类处于循环之中。当AlphaGo击败李世石(Lee Sedol)时,评论人士指出,AlphaGo做出了几个明显的非人类动作。当我们依赖算法在关键领域为我们做出关键决策时,我们不应该惊讶于结果是不人道的。
会议的第二天展示了许多有趣的研究,我们很高兴与你分享我们的最爱。
对于许多深度学习应用程序来说,从我们的模型中得到一个简单的预测是不够的。当不得不做出危及生命的决定,比如诊断病人或驾驶自动驾驶汽车时,我们想要衡量我们对预测的信心。不幸的是,大多数深度学习模型并不能有效地测量他们预测的确定性。最近,贝叶斯深度学习的领域一直在增长,部分原因是它可以通过测量模型的方差来解决这些问题。下面这个研究的成果。
贝叶斯深度学习中计算机视觉需要哪些不确定性?
亚历克斯·肯德尔(Alex Kendall),Yarin Gal
论文地址:https://arxiv.org/pdf/1703.04977.pdf
论文的作者提出了一个统一的贝叶斯框架来识别和估计两种类型的不确定性:
通过这种方式对网络进行建模,与非贝叶斯方法相比,他们都将模型性能提高了几个百分点,并且在实际的自驾应用中显示出高方差的例子(见上图)。

随着机器学习模式变得越来越复杂,他们提供的准确率的提高往往是以更难解释的成本为代价的。在大多数实际案例中,比如在批准贷款或预测犯罪活动时,了解导致模型决策的因素对于调试、验证和规范模型至关重要。这是一种有用的方法用来检测和减少我们在模型中看到的偏见。最近,许多研究都集中在为所有模型提供解释,并在今天提出了一些令人振奋的进展。
解释模型预测的统一方法
Scott M Lundberg,李苏银(Su-In Lee)
论文地址:https://arxiv.org/abs/1705.07874
本论文结合了最近成功用于解释模型的各种方法。方法如 LIME反复切换输入和存储模型预测的变化,以便围绕特定实例拟合线性模型,从而提供局部解释。作者指出,LIME等近期方法均属于加性特征归因方法[ditive feature attribution method]范畴。然后他们提出一个统一的特征置信度,SHAP值(SHapley加法解释[Additive exPlanation])。SHAP值提供的解释比LIME更接近人类的解释,而计算成本只稍微高一点。
LIME地址:http://www.kdd.org/kdd2016/papers/files/rfp0573-ribeiroA.pdf
流式弱子模性:解释神经网络正在运行(on the Fly)
伊桑·埃尔伯格(Ethan Elenberg),Alexandros Dimakis,Moran Feldman,Amin Karbasi
论文地址:https://arxiv.org/pdf/1703.02647.pdf
在这里,作者试图优化黑箱解释器的另一方面:速度。在NIPS上发表的论文中,为了提供比上述LIME快10倍的解释,引入了一种新的方法。主要贡献在于STREAK算法,它使得我们可以更有效地找到在特定类中被分类的实例最大可能性的特性。
由于大多数解释者仍然主要依靠单个实例进行工作,所以对一个模型进行全局解释的一种常见方法是以具有代表性的方式对示例进行抽样,分别解释每个示例,并汇总这些解释。这个过程通常会变得非常缓慢,所以让解释者更快的进展会对我们理解模型的能力产生很大的影响。
不要让这个名字欺骗你,以下所描述的这个论文是一个令人难以置信并令人印象深刻的作品,被NIPS评论家授予了顶级论文奖。使用这描述方法,作者建立了一个名为Libratus的人工智能,在单挑无限德克萨斯扑克比赛中击败了几名专业人士。
安全和嵌套子游戏解决信息不完善的游戏
Noam Brown, Tuomas Sandholm
论文地址:https://arxiv.org/pdf/1705.02955.pdf

在信息完美的游戏中,所有玩家都可以看到棋盘。例子包括国际象棋和围棋。尽管有重大的技术障碍,但在游戏中以完美的信息创造了人类水平(或更高)的性能,这些类型的游戏具有这样的优势,即在玩游戏时,未来可能的移动空间受到以前移动的限制。因此,一个子游戏的发展是独立于其他可能的子游戏,以便有一个更容易处理的解决方案空间。
相比之下,在信息不完善的游戏中,玩家并不知道完整的游戏状态。例如,举个例子,在扑克游戏中,玩家知道自己手中的牌,而不是对手的手牌。这类游戏无处不在,适用于许多现实生活中的情况,如谈判或拍卖。在信息不完善的情况下,随着游戏的发展,给定子游戏的策略可能取决于单独的子游戏。如果你曾经承认论点,以抓住一个朋友的虚假行为,你就会体验到在不完美的信息下,子游戏是如何相互影响的。
什么是安全的子游戏解决方案?这有点复杂,我鼓励你去看论文。由于信息不完善,决策空间可能太大而无法计算所有可能的解决方案,但推断出的简化抽象通常可以解决这个问题。使用这个蓝图战略,一个不安全的子游戏解决方案假定对手将使用简化策略进行抽象游戏。但是,这导致易于利用的行为。回到论证的例子,你正在利用你的朋友的策略,在该策略中他们认为他们会一如既往地执行他们所说的话。一个安全的子博弈解决方案并不会假设对手的策略,但假设蓝图战略是正确的。这为玩家提供了一个可以遵循的策略,但是也可以随着对手策略的变化而偏离该策略。
最后,当对手采取不属于简化抽象的行动时,“嵌套”部分进入。处理这些情况的一种方法就是简单地将其映射到抽象游戏中最接近的动作,并且在本文之前已经是最先进的。更好的方法是生成一个新的子游戏,它本身可能是一个简化抽象。如果对手继续在新的抽象之外采取行动,则可以产生新的嵌套子游戏。在辩论的情况下,这有点虚伪,如果你的朋友没有如预期的那样表示羞愧,而是试图争论一个侧面的观点,那么你自我正义的感觉就会崩溃,你就会被迫适应。
这篇论文解决了许多人认为还需要几年才会解决的问题,本文中的观点可能会在开发越来越复杂的人工智能方面发挥关键作用。信息不完美的情况,在现实世界中无处不在,我们现在有更好的工具来解决这些问题。
今天的许多演讲都集中在生成模型和强化学习领域的令人兴奋的进展。下面是我们认为最精彩的部分
皮特·阿比贝尔(Pieter Abbeel)
论文地址:https://arxiv.org/abs/1703.07326
皮特通过总结监督学习与强化学习(RL)之间的一些主要差异,开始了他的演讲。从本质上讲,RL主要关注的是学习一种有效的策略,让代理人与世界进行交互,以达到最佳的目标。例如,学习如何走路的策略。

Théophane Weber, Sébastien Racanière, David P. Reichert, Lars Buesing,Arthur Guez, Danilo Rezende, Adria Puigdomènech Badia, Oriol Vinyals, Nicolas Heess, Yujia Li, Razvan Pascanu, Peter Battaglia, David Silver, Daan Wierstra
论文地址:https://arxiv.org/abs/1707.06203
除非你对使用“想象力”来描述人工神经网络感到不快,否则本篇论文的方法看起来是一种令人兴奋的强化学习方法(RL)。这项工作的目的是克服目前RL所面临的两个关键挑战:1)深度强化吸学习方法现有的无模型需要大量的数据;2)它们通常不能很好地推广。相比之下,基于模型的方法在高维环境中成本很高。看到这些权衡,来自谷歌DeepMind的团队选择了一个两全其美的方法。首先,他们训练一个学习环境特征的模型。他们使用这个模型作为参考,然后训练一个代理来解释来自环境模型的预测,以告知他们的无模型代理。
艾米丽丹顿(Emily Denton),Vighnesh Birodkar
论文地址:https://arxiv.org/abs/1705.10915
一个名为DrNet的新模型旨在消除视频中与改变部分保持一致的部分。这些信息可用于生成一个目标保持一致的新视频,但其姿态和位置会随着时间而改变。该方法使用两个并行网络,一个学习视频的内容,例如一个人看起来像什么,而另一个在内容中学习时间变化,例如人的位姿。为了完成这项工作,一个关键的发现是如何正确地处罚网络学习的姿势,这样它就不会从内容中获取过多信息。

结果令人印象深刻。将这种方法应用到视频的前几帧中,他们引入了一个标准的LSTM,使用位姿和内容模型来生成数百个未来的新帧。虽然它们与真实的框架不一样,但它们的相似度是显著的,与其他方法相比,DrNet产生的干净的画面几乎没有任何的污点或重影。更妙的是,相对于已经产生大量轰动效应的生成对抗性网络,这个模型相对简单。也许明年我们会看到生成网络空间的多样性。
第一天
深度学习,实践和发展趋势
Nando de Freitas, Scott Rees, Oriol Vinyals
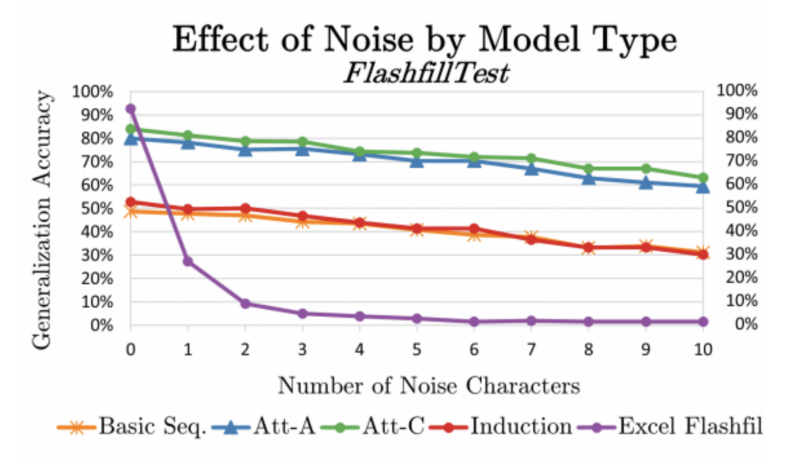
将常规程序(紫色)与RobustFill paper进行比较
这篇演讲对深度学习当前的状态和最近的进展进行了深入的概述。卷积神经网络(CNN)和自回归模型开始在生产中广泛使用,显示了从研究到工业的快速转变。这些模型告诉我们引入感应偏压,如平移不变性(CNN)或时间递归(递归神经网络)是非常有用的。我们还发现,诸如残差网络或注意力等简单的“技巧”可以带来巨大的性能飞跃。有充分的理由相信我们会找到更多这样的“技巧”。展望未来,有几个令人兴奋的研究领域被提及:
- 弱监督域映射:学习将一个域转换为另一个域,而不需要显式的输入/输出对。具体的例子包括自动编码器或最新的生成式对抗网络(GANs),如CycleGAN或者DiscoGAN。
CycleGAN论文地址:https://arxiv.org/abs/1703.10593
DiscoGAN论文地址:https://arxiv.org/abs/1703.05192
- 关于图形的深度学习:大量的输入数据,如朋友网络,产品推荐,或化学分子的结构表示,都可以用图形的形式来表示。作为数据类型的图形是序列的一般化,这使它们广泛适用,但也用序列数据处理问题也有不足,例如低效的批处理。此外,很难找到可以用于大部分图形的可伸缩张量表示。消息传递神经网络是已提出的用于从图形中学习的框架之一。
- 神经编程由神经网络直接生成有效的源代码(程序合成),或者使用潜在程序表示(程序归纳)的生成程序输出构成。一些第一个潜在的应用程序正在创建更强大的程序来输入噪音输入。RobustFill引入了Excel的FlashFill特性的神经版本,当噪音添加到输入数据时,它仍然能够很好地运行,与很快就会崩溃传统程序截然不同。
RobustFill论文地址:https://arxiv.org/pdf/1703.07469.pdf
工程和逆向工程智能使用概率程序,程序归纳和深度学习
Josh Tenenbaum, Vikash K Mansinghka
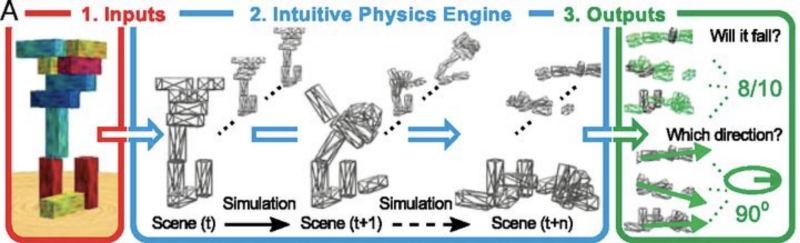
《来自Battaglia 2013年的直观物理模型图》
当今许多人工智能技术依赖于模式识别。然而,作者认为,智能不仅限于此,它包括解释世界,想象可能的后果,并建立一个解决问题的计划。为了弥合这一差距,他们提出了两个问题:
- 在景物理解上的常识:看一幅房地产照片,了解建筑物的结构,或者猜测画中人物的目标。
- 学习创建模型:通过建立一个关于世界如何运作的心智模型来理解事物。例如,预测一个塔块会从静止图像中哪条路掉下来。
作者描述了一个直观的物理引擎,它成功地预测了塔块掉落的方向。这些通过创建一个模拟世界来进行工作的模型,可以很好并且可以很容易地扩展来回答其他问题,例如,如果某些块比其他块重,会发生什么?
直观物理引擎地址:http://www.pnas.org/content/110/45/18327.abstract
这种“常识”的方法可以让我们从更少的例子中学习现代的深度学习,并减少边缘案例。
机器学习的公平性
Solon Barocas, Moritz Hardt
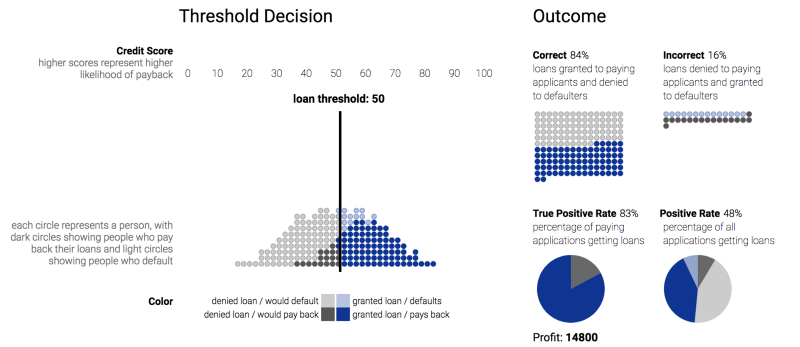
贷款模拟器的说明
在机器学习过程中,道德困境比比皆是,但与自动驾驶汽车和具备人类级别的人工玩家的惊人报道相比,这类难题往往得不到关注。本教程对机器学习算法可以区分受保护类别的多种方式进行了精辟的批评,例如由于像制止和盘查这样的制度性政策而对不平衡采样进行训练,对有偏差的历史数据进行训练,或者仅仅不考虑少数文字类。 在这个概述之后,正式定义把这些问题放在一个易处理的格式中。示例和细节详见网址https://research.google.com/bigpicture/attacking-discrimination-in-ml/。
因果推理提供了另一种分析歧视的工具,但对于理解因果关系,却很少存在转钥式解决方案。也许最有趣的观察是,量度是模型本身。我们不能测量“智力”,但我们可以测量智商。我们不能衡量“置信度”,但我们可以衡量信用评分。这些措施只是代理,并建立在很少给予他们应有关注的偏见和假设之上。
最终,如果我们想确保我们不让歧视进入我们的模型,我们就需要让人类处于循环之中。当AlphaGo击败李世石(Lee Sedol)时,评论人士指出,AlphaGo做出了几个明显的非人类动作。当我们依赖算法在关键领域为我们做出关键决策时,我们不应该惊讶于结果是不人道的。
第二天
会议的第二天展示了许多有趣的研究,我们很高兴与你分享我们的最爱。
获取不确定性
贝叶斯深度学习中计算机视觉需要哪些不确定性?
对于许多深度学习应用程序来说,从我们的模型中得到一个简单的预测是不够的。当不得不做出危及生命的决定,比如诊断病人或驾驶自动驾驶汽车时,我们想要衡量我们对预测的信心。不幸的是,大多数深度学习模型并不能有效地测量他们预测的确定性。最近,贝叶斯深度学习的领域一直在增长,部分原因是它可以通过测量模型的方差来解决这些问题。下面这个研究的成果。
贝叶斯深度学习中计算机视觉需要哪些不确定性?
亚历克斯·肯德尔(Alex Kendall),Yarin Gal
论文地址:https://arxiv.org/pdf/1703.04977.pdf
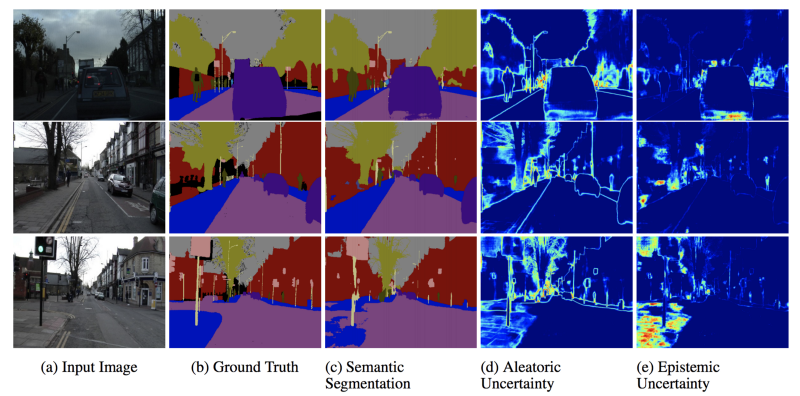
论文的作者提出了一个统一的贝叶斯框架来识别和估计两种类型的不确定性:
- 随机不确定性:由于观测中固有噪声(例如传感器噪声)造成的不确定性,这些噪声无法通过获取更多数据来降低。
- 认知不确定性:由于数据模型不完整造成的不确定性。可以通过获取更多的例子来解释。
通过这种方式对网络进行建模,与非贝叶斯方法相比,他们都将模型性能提高了几个百分点,并且在实际的自驾应用中显示出高方差的例子(见上图)。
模型解释性
流式弱子模性:解释神经网络正在运行(on the Fly)
随着机器学习模式变得越来越复杂,他们提供的准确率的提高往往是以更难解释的成本为代价的。在大多数实际案例中,比如在批准贷款或预测犯罪活动时,了解导致模型决策的因素对于调试、验证和规范模型至关重要。这是一种有用的方法用来检测和减少我们在模型中看到的偏见。最近,许多研究都集中在为所有模型提供解释,并在今天提出了一些令人振奋的进展。
解释模型预测的统一方法
Scott M Lundberg,李苏银(Su-In Lee)
论文地址:https://arxiv.org/abs/1705.07874
本论文结合了最近成功用于解释模型的各种方法。方法如 LIME反复切换输入和存储模型预测的变化,以便围绕特定实例拟合线性模型,从而提供局部解释。作者指出,LIME等近期方法均属于加性特征归因方法[ditive feature attribution method]范畴。然后他们提出一个统一的特征置信度,SHAP值(SHapley加法解释[Additive exPlanation])。SHAP值提供的解释比LIME更接近人类的解释,而计算成本只稍微高一点。
LIME地址:http://www.kdd.org/kdd2016/papers/files/rfp0573-ribeiroA.pdf
流式弱子模性:解释神经网络正在运行(on the Fly)
伊桑·埃尔伯格(Ethan Elenberg),Alexandros Dimakis,Moran Feldman,Amin Karbasi
论文地址:https://arxiv.org/pdf/1703.02647.pdf
在这里,作者试图优化黑箱解释器的另一方面:速度。在NIPS上发表的论文中,为了提供比上述LIME快10倍的解释,引入了一种新的方法。主要贡献在于STREAK算法,它使得我们可以更有效地找到在特定类中被分类的实例最大可能性的特性。
由于大多数解释者仍然主要依靠单个实例进行工作,所以对一个模型进行全局解释的一种常见方法是以具有代表性的方式对示例进行抽样,分别解释每个示例,并汇总这些解释。这个过程通常会变得非常缓慢,所以让解释者更快的进展会对我们理解模型的能力产生很大的影响。
打扑克
不要让这个名字欺骗你,以下所描述的这个论文是一个令人难以置信并令人印象深刻的作品,被NIPS评论家授予了顶级论文奖。使用这描述方法,作者建立了一个名为Libratus的人工智能,在单挑无限德克萨斯扑克比赛中击败了几名专业人士。
安全和嵌套子游戏解决信息不完善的游戏
Noam Brown, Tuomas Sandholm
论文地址:https://arxiv.org/pdf/1705.02955.pdf
人工智能对战德州扑克
在信息完美的游戏中,所有玩家都可以看到棋盘。例子包括国际象棋和围棋。尽管有重大的技术障碍,但在游戏中以完美的信息创造了人类水平(或更高)的性能,这些类型的游戏具有这样的优势,即在玩游戏时,未来可能的移动空间受到以前移动的限制。因此,一个子游戏的发展是独立于其他可能的子游戏,以便有一个更容易处理的解决方案空间。
相比之下,在信息不完善的游戏中,玩家并不知道完整的游戏状态。例如,举个例子,在扑克游戏中,玩家知道自己手中的牌,而不是对手的手牌。这类游戏无处不在,适用于许多现实生活中的情况,如谈判或拍卖。在信息不完善的情况下,随着游戏的发展,给定子游戏的策略可能取决于单独的子游戏。如果你曾经承认论点,以抓住一个朋友的虚假行为,你就会体验到在不完美的信息下,子游戏是如何相互影响的。
什么是安全的子游戏解决方案?这有点复杂,我鼓励你去看论文。由于信息不完善,决策空间可能太大而无法计算所有可能的解决方案,但推断出的简化抽象通常可以解决这个问题。使用这个蓝图战略,一个不安全的子游戏解决方案假定对手将使用简化策略进行抽象游戏。但是,这导致易于利用的行为。回到论证的例子,你正在利用你的朋友的策略,在该策略中他们认为他们会一如既往地执行他们所说的话。一个安全的子博弈解决方案并不会假设对手的策略,但假设蓝图战略是正确的。这为玩家提供了一个可以遵循的策略,但是也可以随着对手策略的变化而偏离该策略。
最后,当对手采取不属于简化抽象的行动时,“嵌套”部分进入。处理这些情况的一种方法就是简单地将其映射到抽象游戏中最接近的动作,并且在本文之前已经是最先进的。更好的方法是生成一个新的子游戏,它本身可能是一个简化抽象。如果对手继续在新的抽象之外采取行动,则可以产生新的嵌套子游戏。在辩论的情况下,这有点虚伪,如果你的朋友没有如预期的那样表示羞愧,而是试图争论一个侧面的观点,那么你自我正义的感觉就会崩溃,你就会被迫适应。
这篇论文解决了许多人认为还需要几年才会解决的问题,本文中的观点可能会在开发越来越复杂的人工智能方面发挥关键作用。信息不完美的情况,在现实世界中无处不在,我们现在有更好的工具来解决这些问题。
第三天
今天的许多演讲都集中在生成模型和强化学习领域的令人兴奋的进展。下面是我们认为最精彩的部分
机器人深度学习
皮特·阿比贝尔(Pieter Abbeel)
论文地址:https://arxiv.org/abs/1703.07326
皮特通过总结监督学习与强化学习(RL)之间的一些主要差异,开始了他的演讲。从本质上讲,RL主要关注的是学习一种有效的策略,让代理人与世界进行交互,以达到最佳的目标。例如,学习如何走路的策略。
我们能教会这个人走路吗?
深度强化学习的想象力—增强代理
Théophane Weber, Sébastien Racanière, David P. Reichert, Lars Buesing,Arthur Guez, Danilo Rezende, Adria Puigdomènech Badia, Oriol Vinyals, Nicolas Heess, Yujia Li, Razvan Pascanu, Peter Battaglia, David Silver, Daan Wierstra
论文地址:https://arxiv.org/abs/1707.06203
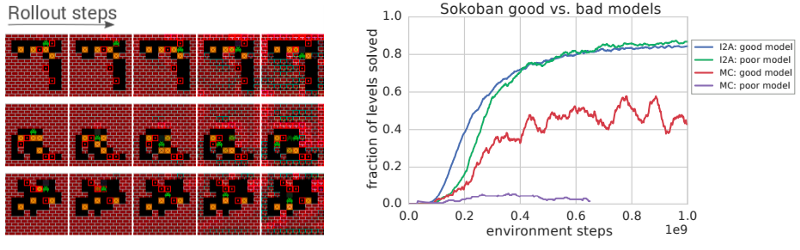
除非你对使用“想象力”来描述人工神经网络感到不快,否则本篇论文的方法看起来是一种令人兴奋的强化学习方法(RL)。这项工作的目的是克服目前RL所面临的两个关键挑战:1)深度强化吸学习方法现有的无模型需要大量的数据;2)它们通常不能很好地推广。相比之下,基于模型的方法在高维环境中成本很高。看到这些权衡,来自谷歌DeepMind的团队选择了一个两全其美的方法。首先,他们训练一个学习环境特征的模型。他们使用这个模型作为参考,然后训练一个代理来解释来自环境模型的预测,以告知他们的无模型代理。
DeepMind令人印象深刻的成果,显示了他们的无模型RL在噪音下的表现
视频中的消纠缠表征[Disentangled Representation]无监督学习
艾米丽丹顿(Emily Denton),Vighnesh Birodkar
论文地址:https://arxiv.org/abs/1705.10915
一个名为DrNet的新模型旨在消除视频中与改变部分保持一致的部分。这些信息可用于生成一个目标保持一致的新视频,但其姿态和位置会随着时间而改变。该方法使用两个并行网络,一个学习视频的内容,例如一个人看起来像什么,而另一个在内容中学习时间变化,例如人的位姿。为了完成这项工作,一个关键的发现是如何正确地处罚网络学习的姿势,这样它就不会从内容中获取过多信息。
从最初几帧生成的视频
结果令人印象深刻。将这种方法应用到视频的前几帧中,他们引入了一个标准的LSTM,使用位姿和内容模型来生成数百个未来的新帧。虽然它们与真实的框架不一样,但它们的相似度是显著的,与其他方法相比,DrNet产生的干净的画面几乎没有任何的污点或重影。更妙的是,相对于已经产生大量轰动效应的生成对抗性网络,这个模型相对简单。也许明年我们会看到生成网络空间的多样性。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消