











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






音乐小白也能乐曲创作 微软Azure机器学习工作平台教你玩音乐
2017年12月11日 由 yining 发表
673587
0
使用深度学习从接近原始的输入中来学习特性表示,这表明它在多种情况下的、多个领域的表现优于传统的、特定于任务的、特征工程,包括对象识别、语音识别和文本分类。随着神经网络的发展,深度学习在诸如乐曲生成等计算创造性任务中越来越受欢迎。这一领域已经取得了巨大的进展,比如Magenta,一个专注于为艺术和音乐创建机器学习项目的开源项目,它由谷歌大脑团队和Flow Machines开发,后者已经发布了一个完整的AI生成的流行音乐专辑。对于那些对乐曲生成产生好奇的人,你可以在下面地址中找到更多的资源。
我们的工作目标是为那些想学习如何为音乐创作建立深度学习模型的新手数据科学家提供帮助。作为一个示例,下面的地址展示了通过训练LSTM模型生成的音乐。
在本文中,我们将向你展示如何使用Azure机器学习(AML)工作平台为简单的乐曲生成构建一个深度学习模型。
以下是对乐曲生成的一个深度学习模型的最重要的组成部分:
Piano roll介绍:
http://www.bcp.psych.ualberta.ca/~mike/Pearl_Street/Dictionary/contents/P/pianoroll.html
数据集
音乐有多种数字音频格式,从原始音频(WAV)到更多的语义表征(semantic representation),如MIDI(音乐设备数字接口)、ABC记谱法和活页乐谱。MIDI数据已经包含了馈送给深度神经网络的所需信息,我们只需将其转换为适当的数字表示来训练模型。对于这项工作,我们将使用scale-chords数据集。下载数据集(免费的小型安装包),它包含156个MIDI格式的scale chord文件。
scale-chords数据集:http://www.feelyoursound.com/scale-chords/
MIDI
MIDI是电子乐器的通信协议。MIDI文件的Python表示形式如下: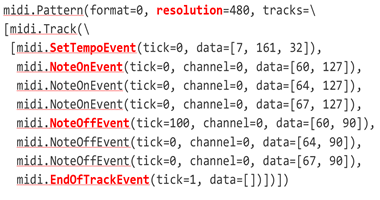
MIDI以“滴答声(tick)”表示时间,它代表了增量时间(delta time),也就是说,每个事件的滴答声都是相对于前一个的。每个MIDI文件的头文件包含该文件的分辨率,它给出每个节拍的滴答声次数。MIDI文件由一个或多个音轨组成,这些音轨进一步由事件消息组成,如以下:
音乐理论
输入表示
输入表示是任何乐曲生成系统的一个重要组成部分。为了将MIDI文件输入到神经网络,我们将MIDI转换为一个piano roll表示。一个piano roll是一个二维的音符VS时间的矩阵,在那个时间点上,绿色方块代表一个音符。我们使用MIDO python库来实现这一点。下图显示了在一个八度音阶上的简单的piano roll。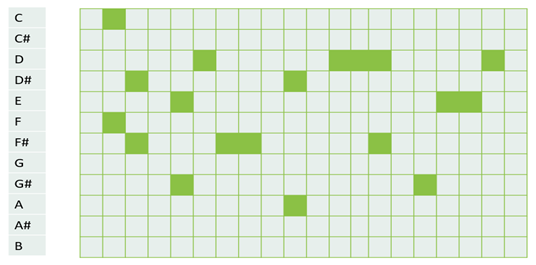
要将上面所示的MIDI文件转换为一个piano roll,我们需要按时间对MIDI事件进行量化。对MIDI事件进行量化的重要技巧是理解如何将MIDI的滴答声转换为绝对时间。要做到这一点,我们只需将节奏(每分钟节拍)乘以分辨率(每个节拍的滴答声),就能得到每秒的滴答声。
模型架构
递归神经网络(RNN)非常适合于序列预测任务,因为它们可以使用递归或循环的连接记忆来自输入序列的长期依赖关系。LSTMs是一种特殊类型的递归神经网络,它具有的可乘性使它们能够在更长的序列中保留内存,这使它们在学习音乐数据中出现的序列模式时非常有用。
有了这个推理,我们决定使用一个LSTM序列到序列模型,如下图所示。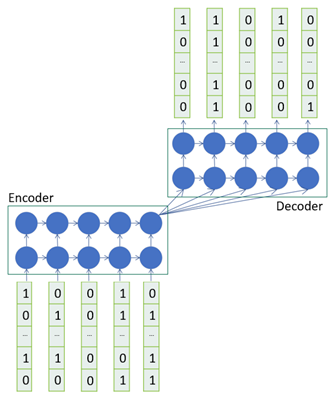
序列到序列模型(Seq2Seq)是由一个编码器(编码输入)和解码器(解码输出)组成的,用来将一个域的序列转换成另一个域的序列,例如以英语的序列到另一个域的序列,或是例如将同样的句子翻译成法语。这通常被用于机器翻译或自由形式的问题回答。在语言翻译中,在音乐中,在给定的时间周期中所播放的音符依赖于前几个音符,而序列到序列模型能够在看到整个输入后产生输出序列。
在上图所示的图形中,给出之前的音符,我们训练网络来生成一些音符长度。为了创造训练集,我们用一个滑动窗口在piano roll上。考虑一下,我们有一个12×10的piano roll,12表示一个八度的音符数,10表示一个piano roll的列数,每一列代表一个绝对的时间。假设一个滑动窗口为5,前5个列被输入编码器作为输入,而后5个列是模型试图学习的目标。由于我们产生了复调音乐,也就是多个音符同时出现,这是一个多标签的分类问题,因此我们需要使用二进制交叉熵损失。
一旦我们完成了我们的网络训练,我们就可以进行能够为我们提供一些音乐的测试。在这种情况下,测试数据被输入到编码器,而解码器的输出代表了模型生成的音乐!
值得注意的是,序列到序列模型的一个局限性是,当给定非常长的输入时,它们会被淹没,并且它们需要其他的语境(context)来源,例如注意力,以便能够自动地专注于输入的特定部分。
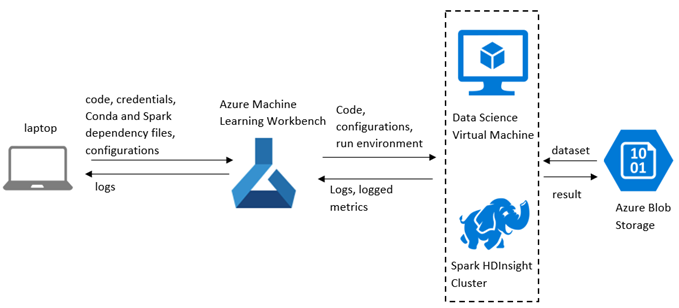
从高层次的角度来看,通过系统的数据流是这样的:
下一节将介绍如何使用Azure机器学习工作台进行设置。
开始使用Azure机器学习
Azure机器学习为数据科学家和机器学习开发人员提供了一个用于数据争论(data wrangling)和试验的工具集,其中包括以下内容:
Azure机器学习地址:https://azure.microsoft.com/en-us/blog/tools-for-the-ai-driven-digital-transformation/
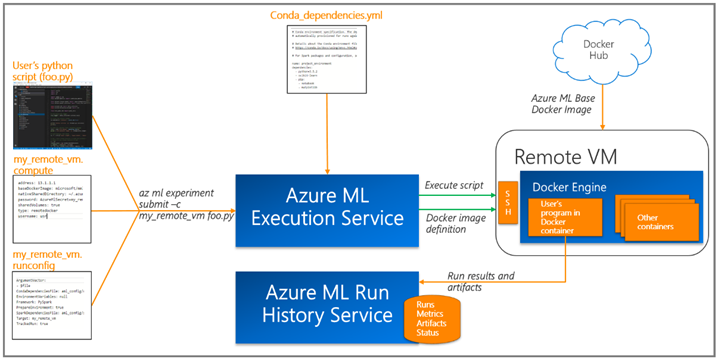
我们提供了使用带有GPU的数据科学虚拟机(dsvm),并使用了Azure机器学习工作平台提供的远程Docker执行环境来训练模型。
Azure机器学习允许你通过Azure机器学习日志API跟踪你的运行历史和模型度量,它帮助我们比较不同的实验,并可视化地比较结果。
训练一个乐曲生成模型
在这一节中,我们将集中讨论训练的设置。
使用Azure机器学习工作平台进行远程虚拟机(remote VM )的训练
Azure机器学习工作平台提供了一种简单的方法,可以扩展到诸如带有GPU的数据科学虚拟机(dsvm),它支持对深度学习模型进行更快速的训练,并为你的所有实验提供隔离、可复制和一致的运行。
步骤1:将远程虚拟机设置为执行目标
步骤2:配置my_dsvm.compute
步骤3:配置my_dsvm.runconfig
我们使用Azure storage来存储训练数据、预先训练的模型和生成的音乐。存储帐户凭证作为EnvironmentVariables被提供。
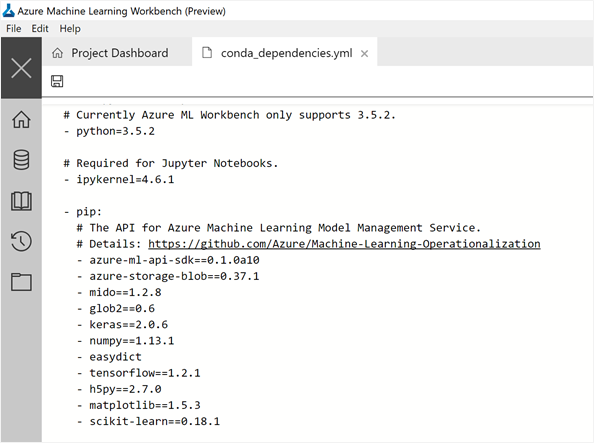
步骤4:Conda_dependencies.yml
步骤5:准备远程机器
步骤6:运行实验
比较运行
作为试验机器学习模型的一部分,我们希望比较不同批次和模型超参数的效果。我们可以在运行历史中对不同的epoch大小进行可视化,并将不同的运行与自定义输出进行比较,如下所示。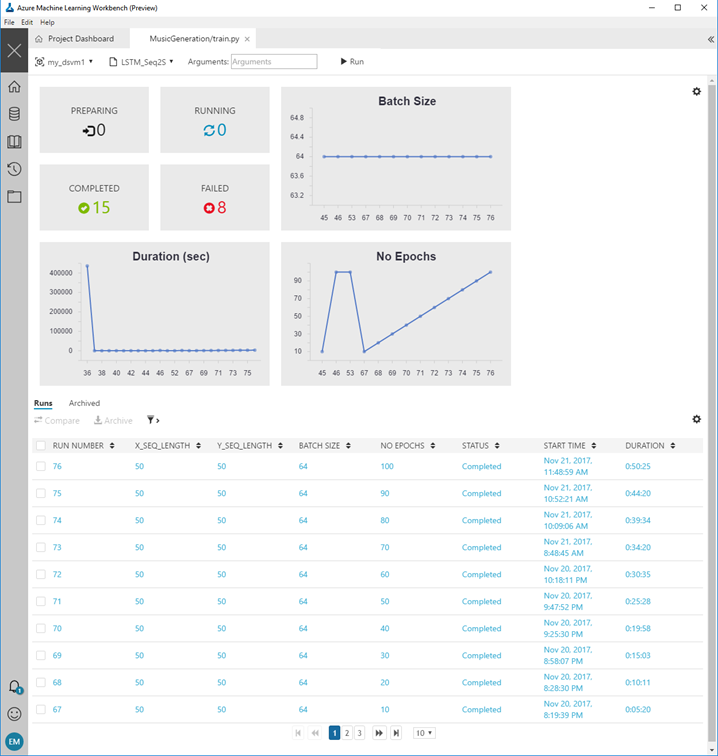
下一个图表显示了我们如何比较10、50和100个epoch的运行情况,并查看相应的损失曲线。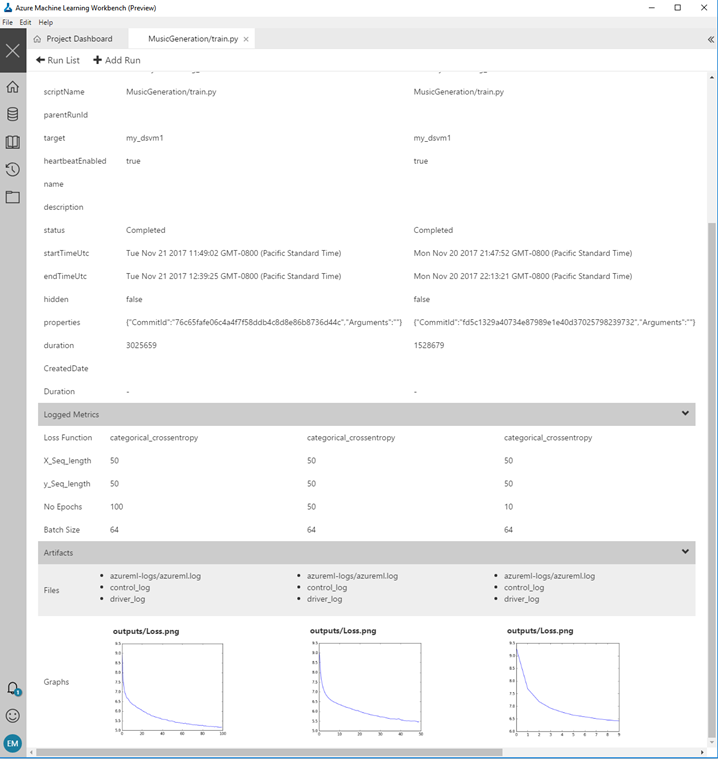
Scoring = Music Generation!
现在你可以通过加载在训练步骤中创建的模型来生成音乐,并调用model.predict() 来生成一些音乐。这是在MusicGeneration / score.py的代码。
总结
在这篇文章中,我们向你展示了如何使用Azure机器学习来构建自己的深度学习乐曲生成模型。这为你提供了一个快速迭代的敏捷实验框架,并提供了一种简单的方法,可以将其扩展到远程环境,例如带有GPU的数据科学虚拟机。
一旦你有了一个可以产生音乐的端到端深度学习模型,你就可以尝试不同的序列长度和不同的模型架构,并聆听它们对所产生的音乐的影响。
资源
本文为编译作品,原文地址:https://blogs.technet.microsoft.com/machinelearning/2017/12/06/music-generation-with-azure-machine-learning/
- 地址:http://www.asimovinstitute.org/analyzing-deep-learning-tools-music/
- Magenta:https://magenta.tensorflow.org/welcome-to-magenta
- Flow Machines:http://www.flow-machines.com/
我们的工作目标是为那些想学习如何为音乐创作建立深度学习模型的新手数据科学家提供帮助。作为一个示例,下面的地址展示了通过训练LSTM模型生成的音乐。
在本文中,我们将向你展示如何使用Azure机器学习(AML)工作平台为简单的乐曲生成构建一个深度学习模型。
以下是对乐曲生成的一个深度学习模型的最重要的组成部分:
- 数据集:用于训练模型的数据。在这个工作中,我们将使用scale-chords数据集。
- 输入表示:一个有意义的音符的矢量表示。在这项工作中,我们将使用一种piano roll表示。
- 模型架构:给出了之前的音符的输入,为学习预测一些音符的深度学习模型体系结构。这个工作使用一个序列到序列(Sequence-to-Sequence)模型,使用多层的LSTM来实现。
Piano roll介绍:
http://www.bcp.psych.ualberta.ca/~mike/Pearl_Street/Dictionary/contents/P/pianoroll.html
数据集
音乐有多种数字音频格式,从原始音频(WAV)到更多的语义表征(semantic representation),如MIDI(音乐设备数字接口)、ABC记谱法和活页乐谱。MIDI数据已经包含了馈送给深度神经网络的所需信息,我们只需将其转换为适当的数字表示来训练模型。对于这项工作,我们将使用scale-chords数据集。下载数据集(免费的小型安装包),它包含156个MIDI格式的scale chord文件。
scale-chords数据集:http://www.feelyoursound.com/scale-chords/
MIDI
MIDI是电子乐器的通信协议。MIDI文件的Python表示形式如下:
MIDI以“滴答声(tick)”表示时间,它代表了增量时间(delta time),也就是说,每个事件的滴答声都是相对于前一个的。每个MIDI文件的头文件包含该文件的分辨率,它给出每个节拍的滴答声次数。MIDI文件由一个或多个音轨组成,这些音轨进一步由事件消息组成,如以下:
- SetTempoEvent:用8位单词表示节拍。
- NoteOnEvent:表示已经按下或打开了一个音符。
- NoteOffEvent:表明一个音符已经被释放或关闭。
- EndOfTrackEvent:指示音轨已结束。
音乐理论
- 节拍(beat):音乐的基本单位时间,也就是四分音符。
- 音符(note):音符播放的音高或频率。例:在钢琴上以MIDI形式的C4音符的频率约为261.62557赫兹。
- 节奏(tempo):以每分钟的节拍数(BPM)表示=每分钟的四分音符(QPM)
每四分音符的微秒(MPQN)=MICROSECONDS_PER_MINUTE / BPM。
输入表示
输入表示是任何乐曲生成系统的一个重要组成部分。为了将MIDI文件输入到神经网络,我们将MIDI转换为一个piano roll表示。一个piano roll是一个二维的音符VS时间的矩阵,在那个时间点上,绿色方块代表一个音符。我们使用MIDO python库来实现这一点。下图显示了在一个八度音阶上的简单的piano roll。
要将上面所示的MIDI文件转换为一个piano roll,我们需要按时间对MIDI事件进行量化。对MIDI事件进行量化的重要技巧是理解如何将MIDI的滴答声转换为绝对时间。要做到这一点,我们只需将节奏(每分钟节拍)乘以分辨率(每个节拍的滴答声),就能得到每秒的滴答声。
模型架构
递归神经网络(RNN)非常适合于序列预测任务,因为它们可以使用递归或循环的连接记忆来自输入序列的长期依赖关系。LSTMs是一种特殊类型的递归神经网络,它具有的可乘性使它们能够在更长的序列中保留内存,这使它们在学习音乐数据中出现的序列模式时非常有用。
有了这个推理,我们决定使用一个LSTM序列到序列模型,如下图所示。
序列到序列模型(Seq2Seq)是由一个编码器(编码输入)和解码器(解码输出)组成的,用来将一个域的序列转换成另一个域的序列,例如以英语的序列到另一个域的序列,或是例如将同样的句子翻译成法语。这通常被用于机器翻译或自由形式的问题回答。在语言翻译中,在音乐中,在给定的时间周期中所播放的音符依赖于前几个音符,而序列到序列模型能够在看到整个输入后产生输出序列。
在上图所示的图形中,给出之前的音符,我们训练网络来生成一些音符长度。为了创造训练集,我们用一个滑动窗口在piano roll上。考虑一下,我们有一个12×10的piano roll,12表示一个八度的音符数,10表示一个piano roll的列数,每一列代表一个绝对的时间。假设一个滑动窗口为5,前5个列被输入编码器作为输入,而后5个列是模型试图学习的目标。由于我们产生了复调音乐,也就是多个音符同时出现,这是一个多标签的分类问题,因此我们需要使用二进制交叉熵损失。
一旦我们完成了我们的网络训练,我们就可以进行能够为我们提供一些音乐的测试。在这种情况下,测试数据被输入到编码器,而解码器的输出代表了模型生成的音乐!
值得注意的是,序列到序列模型的一个局限性是,当给定非常长的输入时,它们会被淹没,并且它们需要其他的语境(context)来源,例如注意力,以便能够自动地专注于输入的特定部分。
从高层次的角度来看,通过系统的数据流是这样的:
下一节将介绍如何使用Azure机器学习工作台进行设置。
开始使用Azure机器学习
Azure机器学习为数据科学家和机器学习开发人员提供了一个用于数据争论(data wrangling)和试验的工具集,其中包括以下内容:
Azure机器学习地址:https://azure.microsoft.com/en-us/blog/tools-for-the-ai-driven-digital-transformation/
- Azure机器学习工作平台。参阅安装和安装文档。
- Azure机器学习实验服务。参阅配置文档。地址:https://docs.microsoft.com/en-us/azure/machine-learning/preview/experimentation-service-configuration
- Azure机器学习模型管理。参阅管理和部署文档。地址:https://docs.microsoft.com/en-us/azure/machine-learning/preview/model-management-overview
我们提供了使用带有GPU的数据科学虚拟机(dsvm),并使用了Azure机器学习工作平台提供的远程Docker执行环境来训练模型。
Azure机器学习允许你通过Azure机器学习日志API跟踪你的运行历史和模型度量,它帮助我们比较不同的实验,并可视化地比较结果。
- Azure机器学习日志API:https://docs.microsoft.com/en-us/azure/machine-learning/preview/reference-logging-api
训练一个乐曲生成模型
在这一节中,我们将集中讨论训练的设置。
使用Azure机器学习工作平台进行远程虚拟机(remote VM )的训练
Azure机器学习工作平台提供了一种简单的方法,可以扩展到诸如带有GPU的数据科学虚拟机(dsvm),它支持对深度学习模型进行更快速的训练,并为你的所有实验提供隔离、可复制和一致的运行。
步骤1:将远程虚拟机设置为执行目标
az ml computetarget attach –name “my_dsvm” –address “my_dsvm_ip_address” –username “my_name” –password
“my_password” –type remotedocker
步骤2:配置my_dsvm.compute
baseDockerImage: microsoft/mmlspark:plus-gpu-0.7.91
nvidiaDocker: true
步骤3:配置my_dsvm.runconfig
EnvironmentVariables:
“STORAGE_ACCOUNT_NAME”:
“STORAGE_ACCOUNT_KEY”:
Framework: Python
PrepareEnvironment: true
我们使用Azure storage来存储训练数据、预先训练的模型和生成的音乐。存储帐户凭证作为EnvironmentVariables被提供。
步骤4:Conda_dependencies.yml
步骤5:准备远程机器
az ml experiment –c prepare m_dsvm
步骤6:运行实验
az ml experiment submit -c my_dsvm Musicgeneration/train.py
评估工作流程
比较运行
作为试验机器学习模型的一部分,我们希望比较不同批次和模型超参数的效果。我们可以在运行历史中对不同的epoch大小进行可视化,并将不同的运行与自定义输出进行比较,如下所示。
下一个图表显示了我们如何比较10、50和100个epoch的运行情况,并查看相应的损失曲线。
Scoring = Music Generation!
现在你可以通过加载在训练步骤中创建的模型来生成音乐,并调用model.predict() 来生成一些音乐。这是在MusicGeneration / score.py的代码。
az ml experiment submit -c my_dsvm Musicgeneration/score.py
总结
在这篇文章中,我们向你展示了如何使用Azure机器学习来构建自己的深度学习乐曲生成模型。这为你提供了一个快速迭代的敏捷实验框架,并提供了一种简单的方法,可以将其扩展到远程环境,例如带有GPU的数据科学虚拟机。
一旦你有了一个可以产生音乐的端到端深度学习模型,你就可以尝试不同的序列长度和不同的模型架构,并聆听它们对所产生的音乐的影响。
资源
- 项目代码:https://github.com/Azure/MachineLearning-MusicGeneration
- Azure机器学习文档:https://docs.microsoft.com/en-us/azure/machine-learning/preview/quickstart-installation
- Scale-chords数据集:http://www.feelyoursound.com/scale-chords/
本文为编译作品,原文地址:https://blogs.technet.microsoft.com/machinelearning/2017/12/06/music-generation-with-azure-machine-learning/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消