


















在视频网站Netflix上进行个性化算法的创新,迎合你的口味排序视频
Netflix是一家美国在线视频网站。Netflix的视频体验是由一系列排名算法(Ranking Algorithm)组成的,每一种算法都针对不同的目的进行优化。例如,主页上Top Picks(最佳选择)排名会根据个性化的视频排名做出推荐,而Trending Now(当前流行趋势)这一栏也包含了最近的流行趋势。这些算法和许多其他的算法一起使用,为超过1亿的用户构建个性化的主页。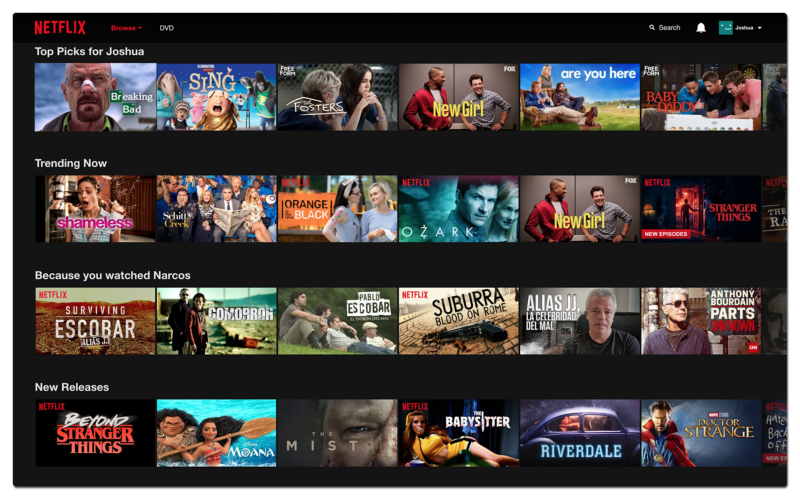 图1:一个个性化的Netflix主页的例子。Netflix使用许多排名算法(ranking algorithm)向网站的会员提供个性化的推荐。比如,视频从左到右的顺序是由特定的排名算法决定的。
图1:一个个性化的Netflix主页的例子。Netflix使用许多排名算法(ranking algorithm)向网站的会员提供个性化的推荐。比如,视频从左到右的顺序是由特定的排名算法决定的。
Netflix不断地改进视频推荐程序。开发过程从创建新的排名算法开始,并对它们在离线状态下的性能进行评估。然后利用A/B测试,对核心评估指标进行在线测量,这与Netflix的业务目标保持一致,即最大化会员满意度。这些指标包括每月的订阅保留率和会员花在流媒体上的时间。随着排名算法和Netflix产品的整体优化,在这些指标中有力的胜出需要越来越多的样本量和长期的实验持续时间。
为了加快算法创新的步伐,Netflix设计了一个两阶段的在线实验过程。第一阶段是一个快速的剪枝(pruning)步骤,在这个步骤中,Netflix从大量的想法中识别出最有希望的排名算法。第二阶段是传统的A/B测试,用于衡量其对更长期会员行为的影响。在这篇文章中,我们关注的是第一阶段的方法:一种交叉存取(interleaving)技术,它能解锁Netflix的更精确地测量会员偏好的能力。
利用交叉存取技术进行更快的算法创新
通过快速测试大量的想法来提高学习的速率是算法创新的一个主要驱动因素。Netflix已经扩展了可以测试的新算法的数量,通过引入在线实验的初步剪枝阶段来满足两个特性:
- 它对排名算法的质量非常敏感。也就是说,与传统的A/B测试相比,它能可靠地识别出最好的算法,而且样本量要小得多。
- 它是第二阶段成功的预测:第一阶段测量的度量标准与Netflix的核心A/B评估指标相一致。
Netflix使用一种交叉存取技术(地址:见下)完成了以上的工作,这极大地加速了他们的实验过程(见图2),第一阶段在几天内完成,留给他们的是一组最有前途的排名算法。第二阶段只使用这些选择算法,这使得他们可以在整个实验中分配到更少的会员,并且与传统的A/B测试相比,减少总的实验持续时间。
交叉存取技术:https://dl.acm.org/citation.cfm?id=2094078
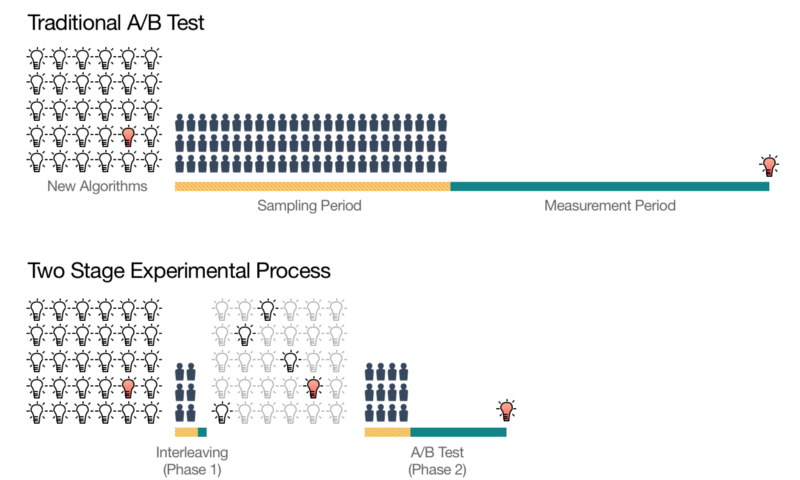
图2:使用交叉存取技术进行更快的算法创新。新算法是由“灯泡”来表示的。其中,有一个获胜的想法(用亮红灯表示)。这种交叉存取的方法可以快速地将最初的排名算法安排到最有前途的候选方案中,使他们能够比传统的A/B测试更快地进行实验,从而识别出获胜的想法。
使用重复的度量设计来确定偏好
为了让我们对交叉存取的敏感性有更深层的理解,我们用一个实验来确定可口可乐或百事可乐在人群中是否更受欢迎。如果我们使用传统的A/B测试,我们可能会随机地将人群分成两组,进行一次盲目的试验。第一组只提供可口可乐,第二组只提供百事可乐(两种饮料都没有可识别的标签)。在实验的结论中,我们可以通过测量两组之间的汽水消费差异,以及测量的不确定度,来确定测试的人是否存在对可口可乐或百事可乐的偏爱,这可以告诉我们是否存在统计上地显著差异。
虽然这种方法是可行的,但也有可能改进测量的机会。首先,有一个主要的测量不确定因素:汽水消费习惯的广泛变化,范围从那些几乎不喝苏打水的人到消耗大量苏打水的人。其次,碳酸饮料的消费者可能只占总人口的一小部分,但他们在碳酸饮料的消费中所占的比例很大。因此,即使是两组中重度汽水消费者之间的小的不平衡,也会对我们的结论产生不成比例的影响。在进行在线实验时,消费者互联网产品往往面临与最活跃用户有关的类似问题,比如在Netflix上衡量一个指标的变化,或者是在社交应用中分享的信息或照片。
作为传统A/B测试的替代品,我们可以使用重复测量来衡量人群对可口可乐和百事可乐的偏好。在这种方法中,人群不会随机分裂。相反,每个人都可以选择可口可乐或百事可乐(两种品牌都没有可识别的标签,但仍能在视觉上区分开来)。在实验的结论中,我们可以在一个人的水平上,比较可乐或百事可乐的汽水消耗量。在这个设计中,1)我们消除了广泛的人群消费习惯造成的不确定因素,2)通过给予每个人同等的权重,我们减少了这种测量在很大程度上受到重苏打(heavy soda)消费者不平衡的影响的可能性。
在Netflix交叉存取
在Netflix上,我们在实验的第一阶段使用交叉存取技术,以敏感地确定两种排名算法之间的会员偏好。下图描述了A/B测试和交叉存取之间的区别。在传统的A/B测试,我们选择两组订阅者:一组接触排名算法A,另一组接触B。在交叉存取技术中,我们选择一组单一的用户,这个用户接触由混合排名算法A和B产生的交叉存取排名。这允许我们当前并行选择用户,以确定他们的偏好排名算法。(会员无法区分哪个算法推荐了一个特定的视频。)Netflix通过比较所浏览的小时数和根据排名算法推荐视频的属性来计算排名算法的相对偏好。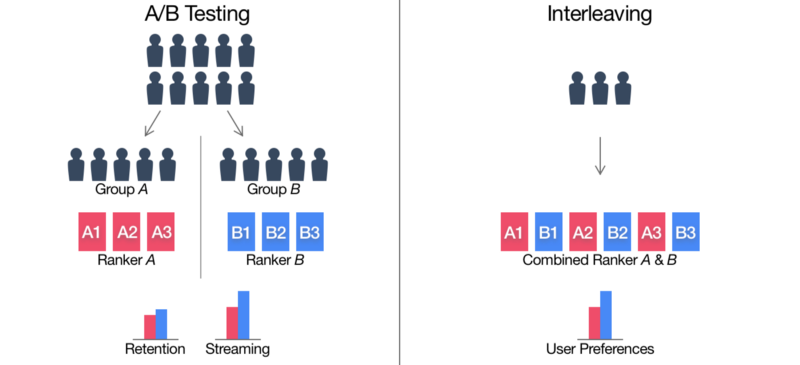 图3:A/B测试vs.交叉存取技术。在传统的A/B测试中,用户被分成两组,一组被放在排名算法A中,另一组则被分到B,核心评估指标像是保留(retention)和流动(streaming)在两个组中被测量和比较。相比之下,交叉存取技术则将一组成员暴露给了排名者A和B的混合排名。用户对排名算法的偏好是通过比较排名者A或B推荐的视频观看时间的比例来确定的。
图3:A/B测试vs.交叉存取技术。在传统的A/B测试中,用户被分成两组,一组被放在排名算法A中,另一组则被分到B,核心评估指标像是保留(retention)和流动(streaming)在两个组中被测量和比较。相比之下,交叉存取技术则将一组成员暴露给了排名者A和B的混合排名。用户对排名算法的偏好是通过比较排名者A或B推荐的视频观看时间的比例来确定的。
当我们在Netflix的主页上生成从两种排名算法A和B的交叉存取视频组时,我们必须考虑位置偏差的存在:当我们从左向右排视频时候,一名会员播放视频的概率会降低。为了获得有效的度量,我们必须确保在任何给定的位置上,一个视频同样可能来自排名算法A或B。
为了解决这个问题,我们一直在使用一种不同的团队选拔(team draft)交叉存取技术,它模拟了如何在一场体育比赛中挑选队员。在这个过程中,两个队长掷硬币决定谁先选。然后,他们轮流挑选,每个队长选择在他们的首选名单上排名最高的球员并且持续可行。这个过程将继续,直到团队选择完成。对于Netflix的视频偏好推荐,将这个类比应用于交叉存取技术中,视频代表了可用的球员和排名算法A和B代表了两队队长的顺序偏好。我们随机决定哪一种排名算法将第一个视频贡献给交叉存取列表。然后排名算法交替,每个算法贡献他们的排名最高的视频(见图4)。成员倾向于排名算法A或B是由在交叉存取行中产生的每小时观看分享数来衡量的,观看数归因于贡献视频的排名者。
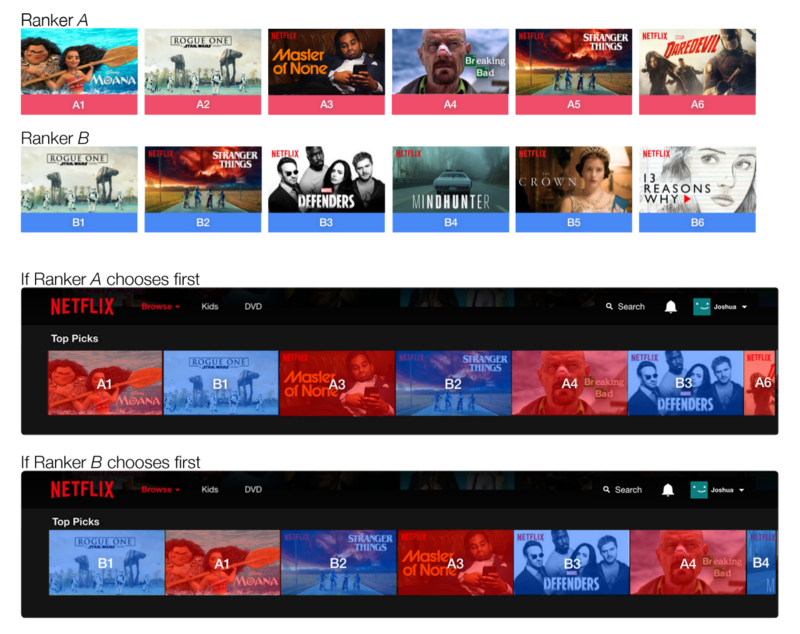 图四:使用团队选拔的两种排序算法的视频。排名算法A和B将各自拥有一组有序的个性化视频。我们从一个随机抛硬币的游戏开始,它决定了排序算法A或B是否贡献了第一个视频。然后,每一种算法都轮流为尚未出现在交叉存取列表中的最高级别视频做出贡献。交叉存取列表的两个可能结果取决于排名者首先选择哪一个。我们通过比较每个排名算法的查看时间的份额来衡量用户的偏好。
图四:使用团队选拔的两种排序算法的视频。排名算法A和B将各自拥有一组有序的个性化视频。我们从一个随机抛硬币的游戏开始,它决定了排序算法A或B是否贡献了第一个视频。然后,每一种算法都轮流为尚未出现在交叉存取列表中的最高级别视频做出贡献。交叉存取列表的两个可能结果取决于排名者首先选择哪一个。我们通过比较每个排名算法的查看时间的份额来衡量用户的偏好。
将交叉存取技术的敏感度与传统的A/B测试进行比较
Netflix在一个两阶段的在线实验过程中提出的第一个要求是,它需要以一个更小的样本量来可靠地识别出更好的排名算法。为了评估交叉存取是否能很好地满足这个要求,我们求助于一个案例,其中两个排名算法A和B都是已知的相对质量:排名者B比排名者A要好,然后我们用这两个排名者进行A/B测试。
为了比较交叉存取和A/B测试的敏感性,Netflix在不同的样本量中使用引导程序二次抽样计算了不同样本容量的交叉存取偏好和A/B度量。在执行引导分析时,我们可以模拟将N个用户分配给交叉存取单元或N/2个用户分配给传统A/B实验的每个单元。如果我们随机猜测哪个排名者更好,不同意真正的偏好的概率将是50%。当这个概率是5%时,我们就达到了95%的能力来检测出不同的等级。因此,一个跨越这个阈值的度量值越少,就越敏感。
图5显示了我们分析的结果。我们比较了在A/B设置中通常使用的两个指标:总体流和一个算法特定的参与度量。用于评估A/B测试的指标的敏感性可以在很大范围内变化。我们发现,交叉存取是非常敏感的:它需要比我们最敏感的A/B指标>100×较少的用户,才能达到95%的能力。
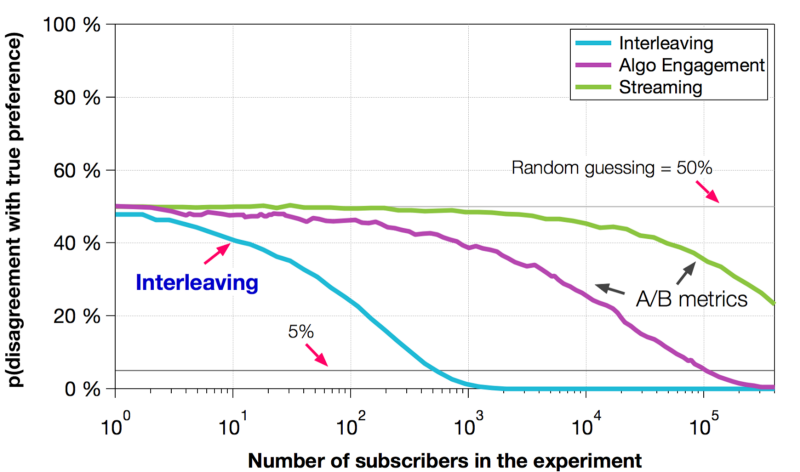 图5:交叉存取的敏感性vs.已知相对质量的两个排名者的传统的A/B指标。引导程序二次抽样是用来测量与传统的参与指标之间的相互关系的敏感性。我们发现,与最敏感的A/B指标相比,交叉存取可能需要>100×较少的用户来正确决定排名者偏好。
图5:交叉存取的敏感性vs.已知相对质量的两个排名者的传统的A/B指标。引导程序二次抽样是用来测量与传统的参与指标之间的相互关系的敏感性。我们发现,与最敏感的A/B指标相比,交叉存取可能需要>100×较少的用户来正确决定排名者偏好。
交叉存取指标与A/B指标之间的相关性
我们的第二个要求是,在交叉存取阶段度量的测量标准需要与我们的传统的A/B测试指标相一致。我们现在要评估的是,在随后的A/B测试中,这种互留偏好是否预示着排名者的表现。
下图显示了交叉存取偏好指标的变化vs.与控制相比的A/B指标变化。每个数据点都代表一个排名算法。我们发现,交叉存取指标与我们最敏感的A/B评估指标之间存在很强的相关性和一致性,这让我们相信,在传统的A/B实验中,交叉存取偏好是成功的预测。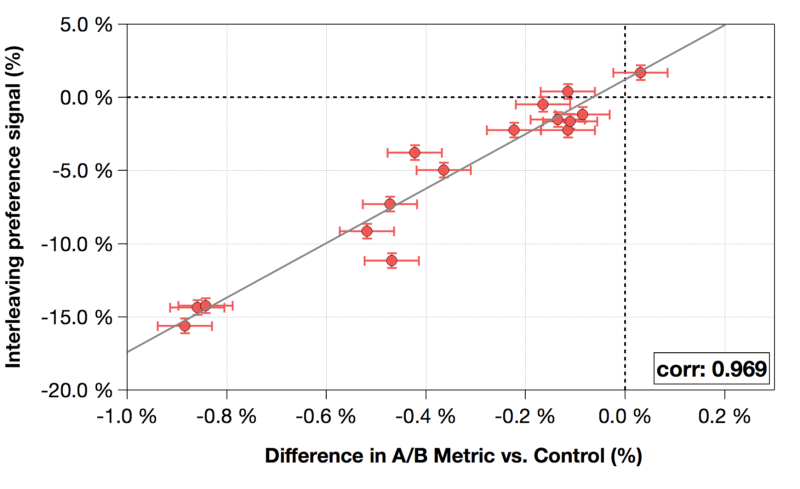 图6:与最敏感的A/B指标之间的交叉存取测量的相关性。每一个点都代表不同的排名算法对生产算法的评估。交叉存取偏好测量和我们最敏感的A/B指标之间存在很强的相关性。
图6:与最敏感的A/B指标之间的交叉存取测量的相关性。每一个点都代表不同的排名算法对生产算法的评估。交叉存取偏好测量和我们最敏感的A/B指标之间存在很强的相关性。
虽然交叉存取可以快速识别最好的排名算法,但它的局限性在于,它是一种对排名算法的用户偏好的相对度量。也就是说,它不允许我们直接测量诸如保留(retention)等度量指标的变化。









