











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






当你开始深度学习时,请注意这些事情
2017年12月12日 由 xiaoshan.xiang 发表
139462
0
深度学习为数据科学提供了非常有效的工具,几乎可以解决任何领域的问题,并使用任何类型的数据。然而,深度学习算法的非直观性推导和使用需要非常仔细的实验设计,如果不能满足这一要求,不管数据的质量或深度学习网络的结构如何,都会导致糟糕的结果。
我第一次注意到这种缺陷大概是在十年前,当时我使用的算法使用了非直观特征来实现自动面部识别。我注意到,当使用当时最常见的面部识别基准(FERET, ORL, YaleB, JAFFE和其他),算法可以确定正确的面部即使只用一个很小的看似空白背景的一部分,通常情况下一个来自原始图像左上角的很小的子图像,不包含脸部的任何部分,如头发,衣服,或者其他可以识别出一个人的东西(1)。
我像他们想要的那样进行了实验,但没有使用完整的面部图像,我只使用了每个图像左上角的一小部分背景。这些算法能够准确识别人脸,有时甚至高达100%,即使图像中没有人脸。换句话说,算法在没有人脸的情况下进行面部识别。

没有脸的面部识别显然是不可能的,这意味着实验设计中的某些东西一定出错了。问题的根源可能是数据采集的过程,为了方便受试者,每个人的照片都是一次性获得的。因此,在照明条件微妙的变化下,相机的位置,甚至CCD在照片拍摄时的温度,可能会导致肉眼看起来不明显的差异,但深入学习算法可以识别它们并对这些图像进行分类,没有任何证据证明图像被人脸分类或者网络确实能识别面部的情况下,提供非常好的面部识别准确性。成千上万的科学论文都是基于这些数据集出版的。
类似的观察也通过自动对象识别数据集进行,深度学习在诸如ImageNet和其他类似的数据集上显示出了显著的改善。仅使用不允许对对象或场景识别的每个图像的很小一部分,就可以使用许多常见的对象识别数据集(2)来实现非常好的自动分类精度。

同样的情况不仅发生在图像数据上,也发生在音频数据(3)上。在使用每一个录音样本的前0.5秒时,我们用非常高的准确性复制了自动重音识别的非直观特征的实验。0.5秒不包含任何可听的信息,但由于背景噪声可以识别出正确的“重音”,即使没有任何重音信息记录(3)。
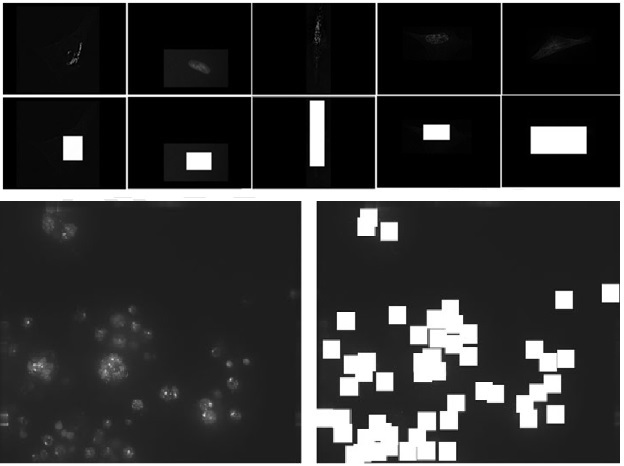
虽然这些实验是由计算机科学家和工程师设计的,但可能生物学家在声音实验设计方面更有经验。然而,对生物图像信息学中一些最基本的实验的快速研究也显示出了同样的问题:对细胞显微镜图像进行自动分析的实验可以在去除图像中的所有细胞后进行复制。同样,实验结果与图像中的细胞无关,表明分析是由背景决定的,而不是生物内容(4)。
使用非直观特征可能会导致似乎已经解决某个问题的假象,实际上并没有提供可靠的证据来证明这个问题实际上已经解决了。这些结果不仅使新手感到困惑,实际上也误导了大量有经验的研究人员,通常这些研究人员对数据分析和实验设计有着深刻的理解。
因此,当使用非直观特征时,设计必须非常仔细,需要有可靠的控制,而且对数据没有任何假设。例如,在面部识别的例子中,数据应该一次只收集一个样本,而不是单批次中的几个样本,假设在一个批次中获取几个样本就相当于在几个不同的采集会话中获取一个样本。
在机器学习中使用交叉验证的常见做法也会带来一些风险。如果训练样本不是独立于测试样本收集的,交叉验证可能会显示出由数据采集过程驱动良好的信号,而不是问题本身。在使用非直观特征的机器学习时,必须非常仔细地检查这些因素。
我第一次注意到这种缺陷大概是在十年前,当时我使用的算法使用了非直观特征来实现自动面部识别。我注意到,当使用当时最常见的面部识别基准(FERET, ORL, YaleB, JAFFE和其他),算法可以确定正确的面部即使只用一个很小的看似空白背景的一部分,通常情况下一个来自原始图像左上角的很小的子图像,不包含脸部的任何部分,如头发,衣服,或者其他可以识别出一个人的东西(1)。
我像他们想要的那样进行了实验,但没有使用完整的面部图像,我只使用了每个图像左上角的一小部分背景。这些算法能够准确识别人脸,有时甚至高达100%,即使图像中没有人脸。换句话说,算法在没有人脸的情况下进行面部识别。
左上角的100x100像素来自于FERET面部识别数据集的前10个主题。图像中没有人脸、头发和衣服,但算法仍然可以识别“人脸”(1)。
没有脸的面部识别显然是不可能的,这意味着实验设计中的某些东西一定出错了。问题的根源可能是数据采集的过程,为了方便受试者,每个人的照片都是一次性获得的。因此,在照明条件微妙的变化下,相机的位置,甚至CCD在照片拍摄时的温度,可能会导致肉眼看起来不明显的差异,但深入学习算法可以识别它们并对这些图像进行分类,没有任何证据证明图像被人脸分类或者网络确实能识别面部的情况下,提供非常好的面部识别准确性。成千上万的科学论文都是基于这些数据集出版的。
类似的观察也通过自动对象识别数据集进行,深度学习在诸如ImageNet和其他类似的数据集上显示出了显著的改善。仅使用不允许对对象或场景识别的每个图像的很小一部分,就可以使用许多常见的对象识别数据集(2)来实现非常好的自动分类精度。
在NEC动物数据集前5个对象右下角的20x20像素子图像。图像中没有任何信息可以识别动物,但算法仍然能够正确地对图像进行分类(2)。
同样的情况不仅发生在图像数据上,也发生在音频数据(3)上。在使用每一个录音样本的前0.5秒时,我们用非常高的准确性复制了自动重音识别的非直观特征的实验。0.5秒不包含任何可听的信息,但由于背景噪声可以识别出正确的“重音”,即使没有任何重音信息记录(3)。
虽然这些实验是由计算机科学家和工程师设计的,但可能生物学家在声音实验设计方面更有经验。然而,对生物图像信息学中一些最基本的实验的快速研究也显示出了同样的问题:对细胞显微镜图像进行自动分析的实验可以在去除图像中的所有细胞后进行复制。同样,实验结果与图像中的细胞无关,表明分析是由背景决定的,而不是生物内容(4)。
无论图像中包含的是细胞还是仅仅是白色矩形,自动识别算法都提供了几乎相同的结果。
使用非直观特征可能会导致似乎已经解决某个问题的假象,实际上并没有提供可靠的证据来证明这个问题实际上已经解决了。这些结果不仅使新手感到困惑,实际上也误导了大量有经验的研究人员,通常这些研究人员对数据分析和实验设计有着深刻的理解。
因此,当使用非直观特征时,设计必须非常仔细,需要有可靠的控制,而且对数据没有任何假设。例如,在面部识别的例子中,数据应该一次只收集一个样本,而不是单批次中的几个样本,假设在一个批次中获取几个样本就相当于在几个不同的采集会话中获取一个样本。
在机器学习中使用交叉验证的常见做法也会带来一些风险。如果训练样本不是独立于测试样本收集的,交叉验证可能会显示出由数据采集过程驱动良好的信号,而不是问题本身。在使用非直观特征的机器学习时,必须非常仔细地检查这些因素。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消