


















有这好事?神经网络模型Word2vec竟能根据个人喜好推荐音乐
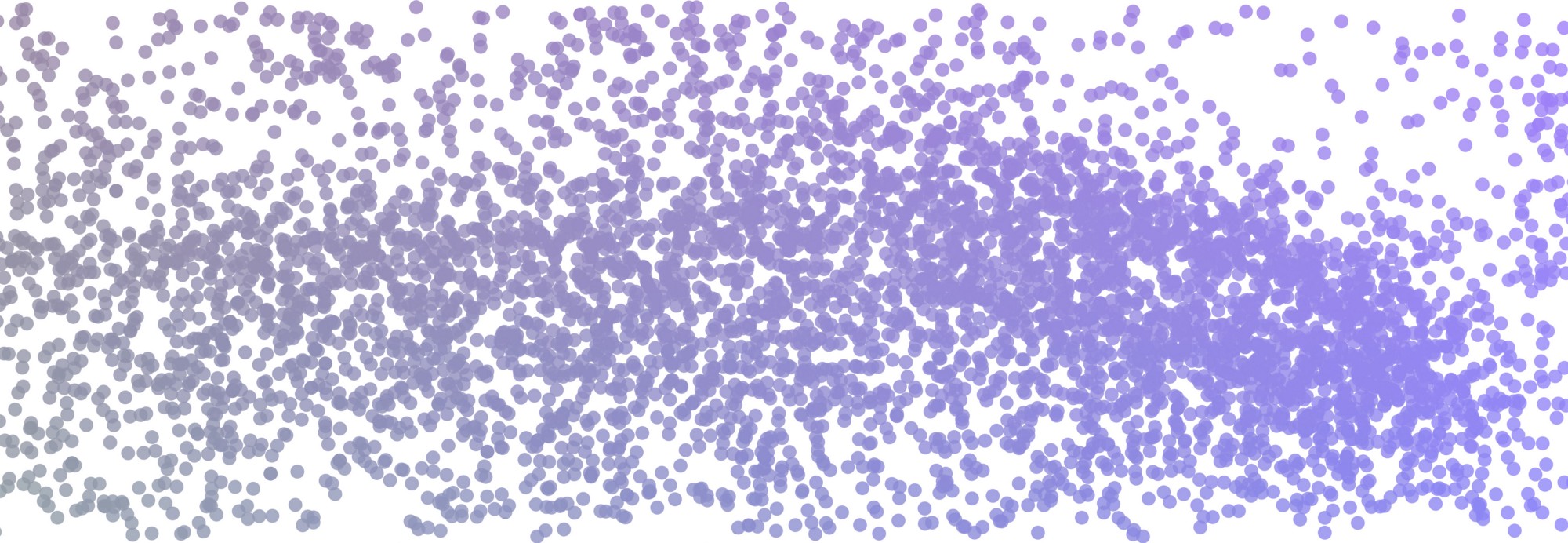
每一个点代表一首歌。分数越接近,歌曲就越相似。
流媒体服务已经改变了我们体验内容的方式。虽然推荐系统以前专注于向用户展示你可能想要购买的内容,但现在的流媒体平台必须专注于推荐你可以并想要享受的内容。由于任何内容都是可以立即访问的,流媒体模式可以通过个性化的电台或推荐播放列表来实现新发现的方法,在这种模式下,现在人们关注的焦点更多地是生成类似歌曲的序列,这些序列可以很好地组合在一起。
现在,每个月都有超过7亿的歌曲播放。这也意味着,所有这些流媒产生的数据量被证明是一种宝贵的训练集,我们可以用它来教授机器学习模型,以更好地理解用户的口味,并改进我们的音乐推荐。
在本文中,我将介绍一种神经网络方法,用于从我们拥有的流媒体数据中提取歌曲嵌入,以及如何使用该模型生成相关推荐。
推荐系统
推荐系统可归入两大类:
- 基于内容的系统是基于我们要推荐的项目特性的推荐系统。当谈论音乐时,内容会包括歌曲的类型,或者每分钟有多少节拍。
- 基于协作过滤的系统是依赖于历史使用数据的系统,它可以推荐其他类似的用户曾经收听过的音乐。这些系统忽略了内容本身的特点,并根据他们的推荐原则,即那些喜欢相同歌曲或歌手的人,通常会喜欢相同风格的音乐。
有了足够多的数据,协作过滤系统就能有效地推荐相关的音乐。协作过滤的基本思想是,如果用户1喜欢歌手A&B,而用户2喜欢歌手A、B和C,那么用户1也可能对歌手C感兴趣。
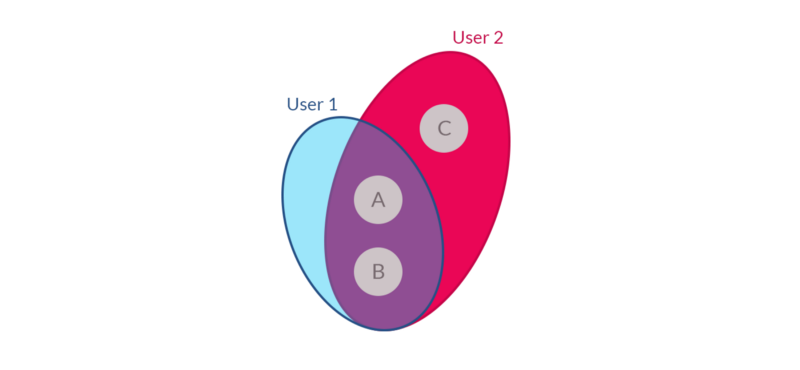
在所有用户中观察全球歌曲偏好,并应用经典的协作过滤方法,例如在用户项评分矩阵中进行矩阵分解,我们就能获得关于歌曲组的相关信息。因此,如果一组用户喜欢的大部分歌曲相同,我们可以推断出,这些用户在音乐中有着非常相似的品味,他们所听的歌曲是相似的。
因此,多个用户之间的全球共现(co-occurrence)给我们提供了“关于歌曲是如何相关的”这样有价值的信息;然而,他们没有捕捉到的一件事是,歌曲是如何在本地同时发生的。因此,他们可能会告诉我们,喜欢歌曲A的用户也可能喜欢歌曲B,但他们是否会在相同的播放列表或电台中收听呢?因此,我们不仅可以看到用户在他们的一生中所听的歌曲,还可以看到他们在什么背景下播放这些歌曲。
所以我们打算用Word2vec模型,它不仅能捕捉到相似的人们通常感兴趣的歌曲,还能捕捉到在非常相似的背景下,人们经常听到的歌曲。
Word2vec是什么?
Word2vec是一种神经网络模型,最初用于学习单词嵌入,这对自然语言处理任务非常有用。近年来,这一技术也被应用到包括产品推荐在内的更普遍的机器学习问题上。神经网络接收大量的文本,分析它,并对词汇中的每个单词产生一个表示该单词的数字向量。这些数字的向量是我们所追求的,因为我们将看到,它们编码了关于这个词的意义的重要信息与它出现的上下文相关。
它定义了两个主要模型:连续的词袋模型(Bag-of-Words model)和Skip-gram模型。在接下来的讨论中,我们将使用Skip-gram模型。
Word2vec的Skip-gram模型是一个浅层的神经网络,它有一个将单词作为输入的隐藏层,并试图预测它周围的单词的上下文。让我们以下列句子为例: 在上面的句子中,“back-alleys”这个词是我们当前的输入词,而“little”、“dark”、“behind”和“the”是我们想要预测的输入词的输出词。我们的神经网络是这样的:
在上面的句子中,“back-alleys”这个词是我们当前的输入词,而“little”、“dark”、“behind”和“the”是我们想要预测的输入词的输出词。我们的神经网络是这样的: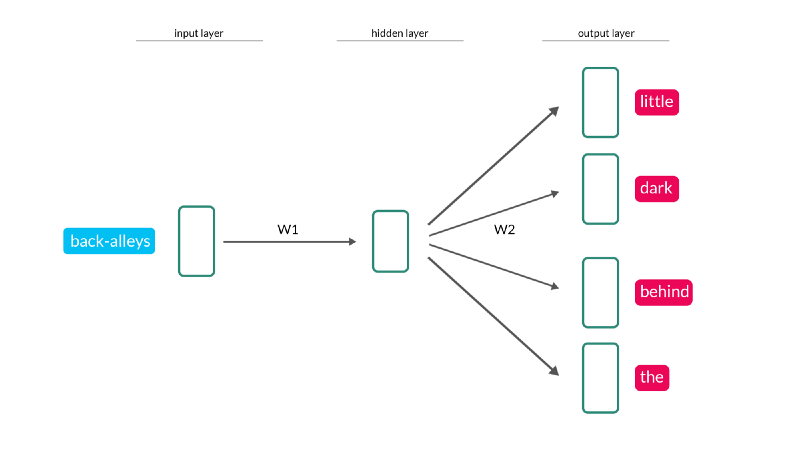 W1和W2代表权重矩阵,它控制了我们在输入上施加的连续变换的权重来得到输出。训练神经网络包括学习那些权重矩阵的值,这些值使我们的输出与所提供的训练数据最接近。
W1和W2代表权重矩阵,它控制了我们在输入上施加的连续变换的权重来得到输出。训练神经网络包括学习那些权重矩阵的值,这些值使我们的输出与所提供的训练数据最接近。
给定一个输入词,我们先通过网络进行第一个正向传播,以得到输出词是根据我们的训练数据所期望的概率。由于我们确切地知道我们对输出的期望是什么,我们可以测量预测中的误差,并利用反向传播将这个错误通过网络传播,并通过随机梯度下降来调整权重。通过这个步骤,我们稍微修改了W1和W2的值,这样它们就能更准确地预测出我们想要的输出词。当我们完成这个步骤时,我们将上下文窗口移到下一个单词,然后再次重复以上步骤。
我们对训练集里的所有句子重复以上步骤,当我们完成时,权重矩阵的值将会集中到产生最准确预测的那个值上。
有趣的是,如果两个不同的词出现在相似的环境中,我们预计,如果把这两个词中的任何一个作为输入,那么神经网络将输出非常类似的预测结果。我们之前已经提到过,权重矩阵的值控制了输出的预测,所以如果两个词出现在相似的上下文中,我们期望这两个词的权重矩阵值基本相同。
特别地,权重矩阵W1是一个矩阵,它的行数和我们词汇表中的单词一样多,每一行都包含与一个特定单词相关的权重。因此,由于相似的词汇需要输出类似的预测,所以矩阵W1中的行应该类似。这个矩阵中每个词的权重都是我们用来表示这个词的“嵌入”。
但这与音乐推荐有什么关系呢?我们可以把用户的收听队列想象成一个句子,每一个单词都是用户听过的一首歌。因此,对这些句子的Word2vec模型进行训练基本上意味着,对于每个用户过去听过的歌曲,我们都在使用他们之前和之后听过的歌曲来教授我们的模型,这些歌曲在某种程度上属于相同的背景。这里有一个想法,关于神经网络与歌曲而不是歌词相像的话将会是什么样子: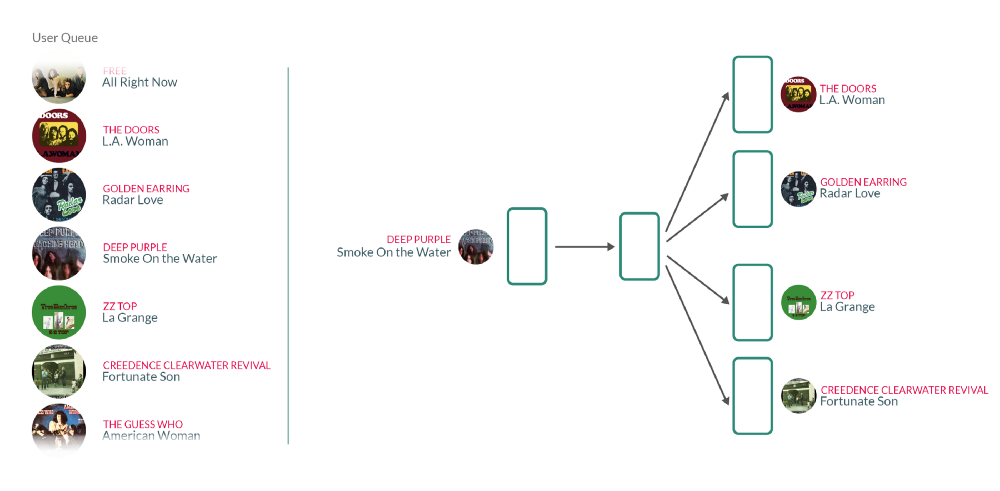 这是与上面讨论的文本分析方法相同的方法,除了文本单词之外,我们现在对每首歌都有唯一的标识符。
这是与上面讨论的文本分析方法相同的方法,除了文本单词之外,我们现在对每首歌都有唯一的标识符。
在训练阶段我们得到的是一个模型,每首歌都是由一个高维度空间中的权重向量来表示的。这些向量的有趣之处是,相似的歌曲将会有比不相关的歌曲有更紧密的权重。
歌曲向量用例
使用Word2vec,将我们的问题转化为在类似情景中出现的歌曲,并将其转化为数学数字,以捕捉这些本地的共现。我们可以把权重看作是一个高维空间中的坐标,每首歌都是由空间中的一个点来表示的。这个空间是由几十个维度定义的,我们不能很容易地把它想象成人类,但是我们可以使用降维技术,比如t-sne,把高维的向量降至到二维,并在图上画出来: 上图中的每一点都代表一首歌,每一个点之间的距离越近,歌曲就越相似。
上图中的每一点都代表一首歌,每一个点之间的距离越近,歌曲就越相似。
这些向量可以以多种方式使用,例如,作为其他机器学习算法的输入特性,但它们也可以自己使用,以找到类似的歌曲。
正如我们前面提到的,在相似的背景下,两首歌出现的次数越多,它们的坐标就越接近。给出特定歌曲,通过向量之间的余弦相似性,我们可以找到k首其他类似的歌曲。例如,黎巴嫩古典歌手Fayrouz的歌曲Shayef El Baher Shou Kbir和相同歌手的歌曲Bhebbak Ma Baaref Laych之间的余弦相似度是0.98,而歌曲Shayef El Baher Shou Kbir和现代黎巴嫩流行歌手Elissa的歌曲Saharna Ya Leil的相似之处只有0.09。这是有道理的,因为那些听Fayrouz的歌曲的人不太可能在他们的播放列表中与Elissa的流行音乐有联系性。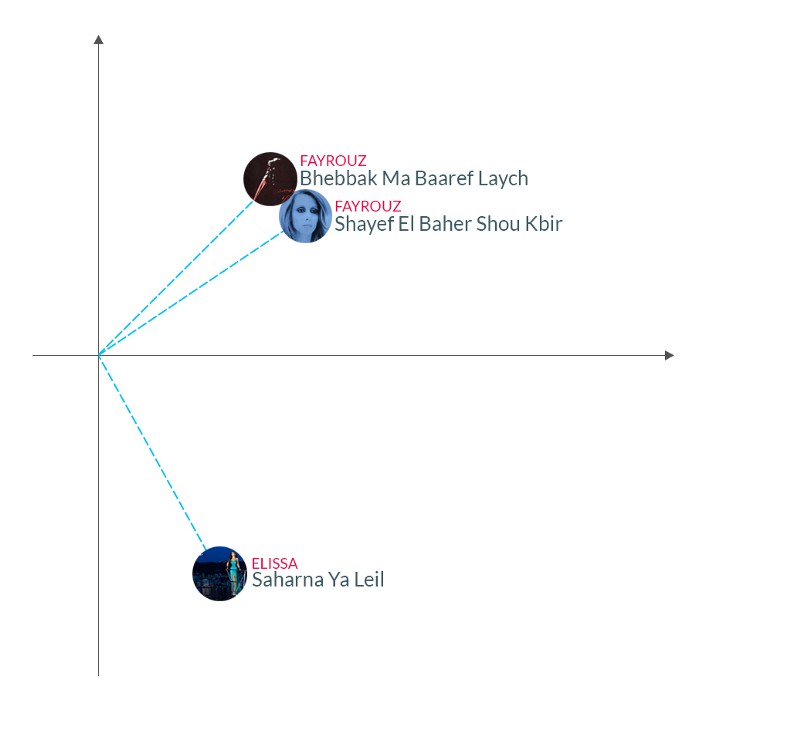 另一种有趣的方式是,我们可以使用歌曲矢量,将用户的收听习惯映射到这个空间,并基于此生成推荐。因为我们现在处理的是向量,我们可以用基本的运算来把向量相加。让我们举个例子,有一个听了三首歌的用户:Keaton Henson的In the Morning, London Grammar的Wasting My Young Years和Daughter的Youth。我们所能做的就是让这些向量对应这三首歌中的每一个,并把它们平均起来,找到一个与这三首歌的距离相等的点。我们所做的是将用户听过的歌曲列表转换成一个坐标向量,它代表了我们的歌曲所在的同一个向量空间中的用户。现在我们有了一个定义用户的向量,我们可以使用之前使用的相同的技术来找到与用户相近的点。下面的动画有助于可视化生成这些推荐所涉及的不同步骤:
另一种有趣的方式是,我们可以使用歌曲矢量,将用户的收听习惯映射到这个空间,并基于此生成推荐。因为我们现在处理的是向量,我们可以用基本的运算来把向量相加。让我们举个例子,有一个听了三首歌的用户:Keaton Henson的In the Morning, London Grammar的Wasting My Young Years和Daughter的Youth。我们所能做的就是让这些向量对应这三首歌中的每一个,并把它们平均起来,找到一个与这三首歌的距离相等的点。我们所做的是将用户听过的歌曲列表转换成一个坐标向量,它代表了我们的歌曲所在的同一个向量空间中的用户。现在我们有了一个定义用户的向量,我们可以使用之前使用的相同的技术来找到与用户相近的点。下面的动画有助于可视化生成这些推荐所涉及的不同步骤: 我们发现了一些歌曲,比如The Head and the Heart的Down in the Valley,Fleet Foxes的Mykonos和Ben Howard的Small Things,它们都和我们的输入歌曲一样,都是一样的民族风歌曲。请记住,我们所做的一切都不是基于对声学的研究,而是通过观察其他人在这些特定的歌曲中所听到的歌曲。
我们发现了一些歌曲,比如The Head and the Heart的Down in the Valley,Fleet Foxes的Mykonos和Ben Howard的Small Things,它们都和我们的输入歌曲一样,都是一样的民族风歌曲。请记住,我们所做的一切都不是基于对声学的研究,而是通过观察其他人在这些特定的歌曲中所听到的歌曲。
结论
Word2vec允许我们精确地对每首歌进行建模,并使用一个坐标向量来捕捉这首歌的背景。这使我们能够很容易地识别相似的歌曲,并使用向量运算来找到定义每个用户的向量。
目前,Word2vec的向量和其他的音乐推荐功能一起使用,主要是基于用户的收听习惯的音乐发现。所以下次当你通过推荐找到一首好歌的时候,想想成千上万的人在听这首歌,应该会很兴奋吧。









