











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






无人零售背后的秘密:使用Tensorflow目标检测API实现更智能的零售结账
2017年12月13日 由 xiaoshan.xiang 发表
304416
0
我一直在使用Tensorflow目标检测API,并对这些模型的强大程度感到惊讶。我想要分享一些API实际使用案例的性能。
Tensorflow目标检测API地址:https://github.com/tensorflow/models/tree/master/research/object_detection
第一个使用案例是更智能的零售结账体验。Amazon Go商店宣布后,这是一个热门领域。
为商店设计智能货架,追踪顾客从货架挑选的东西。我通过构建两个目标检测模型来做到这一点 — 一个的追踪手,用来追踪被手部所选择的东西。第二个独立模型,用来监测货架空间。请参阅下面的GIF。通过使用两种模型,可以将错误最小化。

计算机视觉另一种用于零售收银台的应用程序可以代替结账系统中逐一扫描物品,将所有的东西都放在一起,相机能够检测和记录所有信息。也许我们甚至不需要结帐通道。购物车可以配备相机,你只需推着你的购物车购物,当你走出商店的时候,就会收到购物账单。这是不是太酷了!我用这个API设计了一个带有3个随机项目的“迷你”模型,这个模型可以很容易地检测出被放置的物品和数量。请参阅下面的GIF。通过各种各样的实验,我发现API即使在只有部分可见的商品上也表现得很好。

那么我们如何构建这个模型呢?
通过查看在线公开可用的数据集或创建自己的数据,可以收集图像。每种方法都有它的优点和缺点。例如,手部探测器可以使用公开可用的数据集来构建,就像“ Ego手部数据集”一样。这个数据集的手形、颜色和姿势有很大的变化,当模型应用于真实世界时,这是非常有用的。另一方面,对于货架上或购物车中的商品,最好收集你自己的数据,因为我们不希望从各方收集数据有太大的变化。在建立你的模型前,通过使用图像处理库(如PIL an OpenCV)创建额外的图像亮度的随机变化,缩放、旋转等,是增加数据的非常好的方法。这个过程可以创建很多额外的样本本,并且可以使模型强健。
Ego手部数据集地址:http://vision.soic.indiana.edu/projects/egohands/
对于目标检测模型,我们需要在目标周围的边框上注释。为了达成这一目的,我使用labelimg。它是用Python编写,并使用Qt进行接口。这是一个句柄[handle]工具,注释是用Pascal VOC格式创建的,这使得了用在Tensorflow Github上共享的脚本 - — create_pascal_tf_record.py 和 create_pet_tf_record.py.来创建TFRecord文件变得很容易。
labelimg地址:https://github.com/tzutalin/labelImg
create_pascal_tf_record.py脚本 地址:https://github.com/tensorflow/models/blob/master/research/object_detection/create_pascal_tf_record.py
create_pet_tf_record.py脚本地址:https://github.com/tensorflow/models/blob/master/research/object_detection/create_pet_tf_record.py
2.创建模型
关于如何在自定义数据集上训练Tensorflow目标检测API,我已经写了一个非常详细的教程——用Tensorflow检测检测API构建一个玩具检测器。包括相关的Github。
用Tensorflow目标检测API构建一个玩具检测器地址:https://towardsdatascience.com/building-a-toy-detector-with-tensorflow-object-detection-api-63c0fdf2ac95
相关的Github地址:https://github.com/priya-dwivedi/Deep-Learning/tree/master/tensorflow_toy_detector
构建模型时必须做出的一个重大决策是将目标检测模型用作微调检查点。已训练过的可用于COCO数据集的最新模型列表如下:
模型列表地址:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
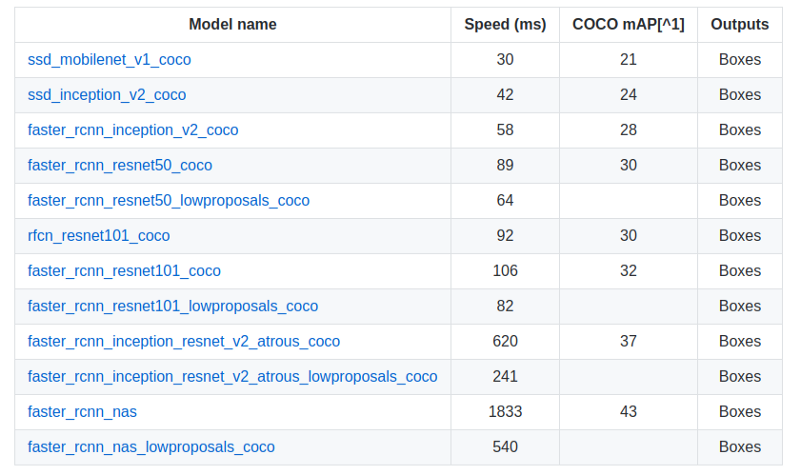
有一种直接的交易,即b / w速度和准确性。对于实时检测,最好使用SSD模型或者Faster RCNN Inception(这是我个人喜欢的)。对于货架上或购物车上的物品检测,我更喜欢较慢但更准确的模型,如 Faster RCNN Resnet 或更快的RCNN Inception Resnet。
我个人认为,真正的工作是在构建模型的第一个版本之后开始的!没有一个模型是完美的,当你开始使用它时,你会注意到它性能上的缺口。然后你需要用你的直觉来判断这些缺口是否可以被堵塞,模型是否需要改进,或者是否需要另一个模型或非模型的入侵来达到你想要的精度。如果你幸运的话,你只需要添加额外的数据以提高性能。
如果你想了解更多关于目标检测和Tensorflow目标检测API,请查看文章——谷歌Tensorflow目标检测API是实现图像识别的最简单的方法吗?
文章地址:https://medium.com/towards-data-science/is-google-tensorflow-object-detection-api-the-easiest-way-to-implement-image-recognition-a8bd1f500ea0
Tensorflow目标检测API地址:https://github.com/tensorflow/models/tree/master/research/object_detection
第一个使用案例是更智能的零售结账体验。Amazon Go商店宣布后,这是一个热门领域。
为商店设计智能货架,追踪顾客从货架挑选的东西。我通过构建两个目标检测模型来做到这一点 — 一个的追踪手,用来追踪被手部所选择的东西。第二个独立模型,用来监测货架空间。请参阅下面的GIF。通过使用两种模型,可以将错误最小化。
手部追踪和库存监控
计算机视觉另一种用于零售收银台的应用程序可以代替结账系统中逐一扫描物品,将所有的东西都放在一起,相机能够检测和记录所有信息。也许我们甚至不需要结帐通道。购物车可以配备相机,你只需推着你的购物车购物,当你走出商店的时候,就会收到购物账单。这是不是太酷了!我用这个API设计了一个带有3个随机项目的“迷你”模型,这个模型可以很容易地检测出被放置的物品和数量。请参阅下面的GIF。通过各种各样的实验,我发现API即使在只有部分可见的商品上也表现得很好。
高精度的商品检测
那么我们如何构建这个模型呢?
1.收集数据
通过查看在线公开可用的数据集或创建自己的数据,可以收集图像。每种方法都有它的优点和缺点。例如,手部探测器可以使用公开可用的数据集来构建,就像“ Ego手部数据集”一样。这个数据集的手形、颜色和姿势有很大的变化,当模型应用于真实世界时,这是非常有用的。另一方面,对于货架上或购物车中的商品,最好收集你自己的数据,因为我们不希望从各方收集数据有太大的变化。在建立你的模型前,通过使用图像处理库(如PIL an OpenCV)创建额外的图像亮度的随机变化,缩放、旋转等,是增加数据的非常好的方法。这个过程可以创建很多额外的样本本,并且可以使模型强健。
Ego手部数据集地址:http://vision.soic.indiana.edu/projects/egohands/
对于目标检测模型,我们需要在目标周围的边框上注释。为了达成这一目的,我使用labelimg。它是用Python编写,并使用Qt进行接口。这是一个句柄[handle]工具,注释是用Pascal VOC格式创建的,这使得了用在Tensorflow Github上共享的脚本 - — create_pascal_tf_record.py 和 create_pet_tf_record.py.来创建TFRecord文件变得很容易。
labelimg地址:https://github.com/tzutalin/labelImg
create_pascal_tf_record.py脚本 地址:https://github.com/tensorflow/models/blob/master/research/object_detection/create_pascal_tf_record.py
create_pet_tf_record.py脚本地址:https://github.com/tensorflow/models/blob/master/research/object_detection/create_pet_tf_record.py
2.创建模型
关于如何在自定义数据集上训练Tensorflow目标检测API,我已经写了一个非常详细的教程——用Tensorflow检测检测API构建一个玩具检测器。包括相关的Github。
用Tensorflow目标检测API构建一个玩具检测器地址:https://towardsdatascience.com/building-a-toy-detector-with-tensorflow-object-detection-api-63c0fdf2ac95
相关的Github地址:https://github.com/priya-dwivedi/Deep-Learning/tree/master/tensorflow_toy_detector
构建模型时必须做出的一个重大决策是将目标检测模型用作微调检查点。已训练过的可用于COCO数据集的最新模型列表如下:
模型列表地址:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md
Tensorflow CoCo训练的模型
有一种直接的交易,即b / w速度和准确性。对于实时检测,最好使用SSD模型或者Faster RCNN Inception(这是我个人喜欢的)。对于货架上或购物车上的物品检测,我更喜欢较慢但更准确的模型,如 Faster RCNN Resnet 或更快的RCNN Inception Resnet。
3 .测试和改进模型
我个人认为,真正的工作是在构建模型的第一个版本之后开始的!没有一个模型是完美的,当你开始使用它时,你会注意到它性能上的缺口。然后你需要用你的直觉来判断这些缺口是否可以被堵塞,模型是否需要改进,或者是否需要另一个模型或非模型的入侵来达到你想要的精度。如果你幸运的话,你只需要添加额外的数据以提高性能。
如果你想了解更多关于目标检测和Tensorflow目标检测API,请查看文章——谷歌Tensorflow目标检测API是实现图像识别的最简单的方法吗?
文章地址:https://medium.com/towards-data-science/is-google-tensorflow-object-detection-api-the-easiest-way-to-implement-image-recognition-a8bd1f500ea0

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消