











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Prodigy,从根本上有效的自主学习驱动的注释工具
2017年12月14日 由 yining 发表
824252
0
Prodigy是一种非常高效的机器教学工具,数据科学家可以在无需外部注释的情况下,为新功能创建端到端原型,并且可以顺利地进行生产。无论你是在进行实体识别、意图检测还是图像分类,Prodigy都可以帮助你更快地训练和评估你的模型。
注释通常是项目停滞的部分。有了Prodigy,你可以在吃早餐的时候生成一个想法,并在午餐之前就能为你的想法得到结果。一旦模型得到了训练,你就可以将其导出为一个版本化的Python包,从而使系统更容易地投入生产。
1.打开并快速运行。你可以直接开箱使用Prodigy——你所需要的就是Python和网络浏览器。如果以这种方式运行,则使用SQLite将注释存储在本地文件中。对于远程使用,你可以使用内置的SQLite、MySQL或PostgreSQL后端。
2.使用内置的注释Recipe或编写自己的注释。Recipe控制了注释示例和处理逻辑的流,并定义了如何更新你的模型。
Prodigy提供了很多有用的组件,包括用于通用格式的加载器、实时API流、存储后端和用于一系列任务的神经网络模型。
由于Recipe是作为Python函数实现的,所以很容易集成你自己的解决方案。无论你的ETL逻辑多么复杂,如果你可以从Python函数调用它,你就可以在Prodigy中使用它。
3.从命令行运行Recipe,并开始注释。Recipe装饰器使用你的函数的签名来生成一个命令行界面,使你可以轻松地使用不同的设置来运行相同的Recipe,并在你的注释项目中重用Recipe。当你运行Recipe命令时,Prodigy将启动一个web服务器,这样你就可以开始注释了。
4.在modern web应用程序中保持高效。Prodigy的web应用可以让你直接从浏览器,甚至是在移动设备上标注文字、实体、分类和图片。它的modern UI界面让你专注,并且只要求你一次做一个二元决策。
当你点击或浏览这些例子时,注释会通过REST API被发送回Prodigy。Prodigy可以实时更新你的模型,并选择最重要的问题在下一次回答。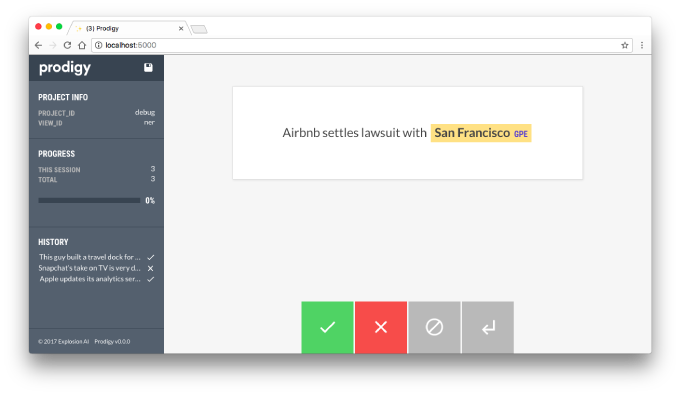
注释接口
大多数注释工具都避免向用户提出任何建议,以避免对注释产生偏差。Prodigy采取了相反的方法:尽可能少地询问用户。你的模型所生成的结构越复杂,你就能从Prodigy的二进制接口中获得更多的好处。
内置的神经网络模型
Prodigy为许多常用的应用程序提供高质量的统计模型。你也可以使用Prodigy来训练或评估你自己的解决方案——它可以与任何统计模型一起工作。
立即导出并使用你的模型
Prodigy可以导出现成的模型,这使得测试结果很容易,并将其投入生产。内置的NLP Recipes输出spaCy模型,你可以将其打包到可安装的模块中。你也可以通过定制的Recipe来使用任何机器学习库。内置对TensorFlow、Keras、PyTorch和scikit-learn模式的支持也很快就会投入使用。

你可以和Prodigy做什么?
Prodigy的可插式架构使你可以很容易地使用你自己的组件来存储、加载、分类、示例选择甚至注释。它的内置功能支持简单而强大的工作流:
个人使用
适合自由职业者,独立开发人员,业余爱好者。内容包括:
售价:290美元
企业使用
适合创业公司,数据科学团队。内容包括:
售价:390美元,总共5个名额。
Prodigy官网:https://prodi.gy/
注释通常是项目停滞的部分。有了Prodigy,你可以在吃早餐的时候生成一个想法,并在午餐之前就能为你的想法得到结果。一旦模型得到了训练,你就可以将其导出为一个版本化的Python包,从而使系统更容易地投入生产。
1.打开并快速运行。你可以直接开箱使用Prodigy——你所需要的就是Python和网络浏览器。如果以这种方式运行,则使用SQLite将注释存储在本地文件中。对于远程使用,你可以使用内置的SQLite、MySQL或PostgreSQL后端。
prodigy dataset my_dataset "New dataset"
✨ Created dataset 'my_dataset'.
2.使用内置的注释Recipe或编写自己的注释。Recipe控制了注释示例和处理逻辑的流,并定义了如何更新你的模型。
Prodigy提供了很多有用的组件,包括用于通用格式的加载器、实时API流、存储后端和用于一系列任务的神经网络模型。
由于Recipe是作为Python函数实现的,所以很容易集成你自己的解决方案。无论你的ETL逻辑多么复杂,如果你可以从Python函数调用它,你就可以在Prodigy中使用它。
RECIPE.PY
import prodigy
from prodigy.components.loaders import NewYorkTimes
@prodigy.recipe('news_headlines', dataset=("ID"), query=("Query"))
def news_headlines(dataset, query):
return {
'dataset': dataset,
'stream': NewYorkTimes(query=query, key='xxx')
}
3.从命令行运行Recipe,并开始注释。Recipe装饰器使用你的函数的签名来生成一个命令行界面,使你可以轻松地使用不同的设置来运行相同的Recipe,并在你的注释项目中重用Recipe。当你运行Recipe命令时,Prodigy将启动一个web服务器,这样你就可以开始注释了。
prodigy news_headlines my_dataset "Silicon Valley" -F recipe.py
✨ Starting the web server on port 8080...
4.在modern web应用程序中保持高效。Prodigy的web应用可以让你直接从浏览器,甚至是在移动设备上标注文字、实体、分类和图片。它的modern UI界面让你专注,并且只要求你一次做一个二元决策。
当你点击或浏览这些例子时,注释会通过REST API被发送回Prodigy。Prodigy可以实时更新你的模型,并选择最重要的问题在下一次回答。
Prodigy的有效注释Recipe
Prodigy将模型放在循环中,这样它就可以积极地参与到训练过程中,并在训练过程中学习。该模型使用它已经知道的东西来找出接下来要问的内容,并根据所提供的答案进行更新。没有复杂的配置系统可以使用:你只需编写一个Python函数,它将组件作为一个字典返回。Prodigy有各种各样的内置Recipe,可以被链接在一起构建复杂的系统。
RECIPE.PY
@prodigy.recipe('custom_recipe', dataset=("ID"))
def custom_recipe(dataset):
# text source, processing logic and model
return {'dataset': dataset}
注释接口
大多数注释工具都避免向用户提出任何建议,以避免对注释产生偏差。Prodigy采取了相反的方法:尽可能少地询问用户。你的模型所生成的结构越复杂,你就能从Prodigy的二进制接口中获得更多的好处。
内置的神经网络模型
Prodigy为许多常用的应用程序提供高质量的统计模型。你也可以使用Prodigy来训练或评估你自己的解决方案——它可以与任何统计模型一起工作。
- 命名实体识别:从现有的模型开始并调整其准确性,添加一个新的实体类型或从头开始训练一个新的模式。Prodigy支持创建术语列表的新模式,并使用它们来引导NER模型。
- 文本分类:分类文本的意图,情绪,话题,或任何其他计划。在长文档中,可以使用一种注意力机制,这样你只需要阅读它认为最相关的句子。
- 文本相似度:将一个数值相似的分数分配给两段文字。有了Prodigy,你可以判断两个句子中的哪一个更好。
- 图像分类:根据对象、样式、上下文或任何其他你感兴趣的度量对图像进行分类。
立即导出并使用你的模型
Prodigy可以导出现成的模型,这使得测试结果很容易,并将其投入生产。内置的NLP Recipes输出spaCy模型,你可以将其打包到可安装的模块中。你也可以通过定制的Recipe来使用任何机器学习库。内置对TensorFlow、Keras、PyTorch和scikit-learn模式的支持也很快就会投入使用。
USE A MODEL WITH SPACY V2.0
prodigy textcat.batch-train dataset /tmp/model
>>> import spacy
>>> nlp = spacy.load('/tmp/model')
>>> doc = nlp(u"Try the text classification model")
>>> print(doc.cats)
选择存储后端
你可以使用你最喜欢的数据库来保存所收集的所有注释的副本。要么连接到一个内置选项,要么集成你自己的选项。
对各种文件格式的支持
Prodigy支持最常用的文件格式,并将检测到从文件扩展中使用的加载器。
数据科学工作流中的缺失部分
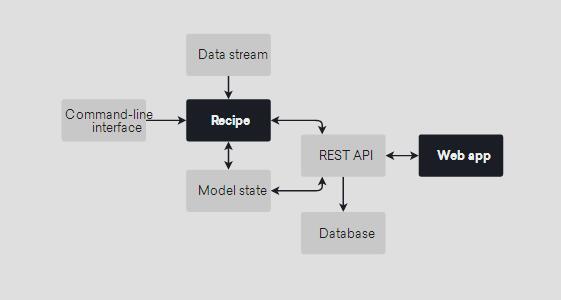
Prodigy汇集了来自机器学习和用户体验的最先进的见解。有了持续的活动学习系统,你只需要注释那些模型还不知道答案的例子。web应用程序是强大的、可扩展的,并且遵循了现代用户体验原则。原因非常简单:它的设计目的是帮助你一次只关注一个决定。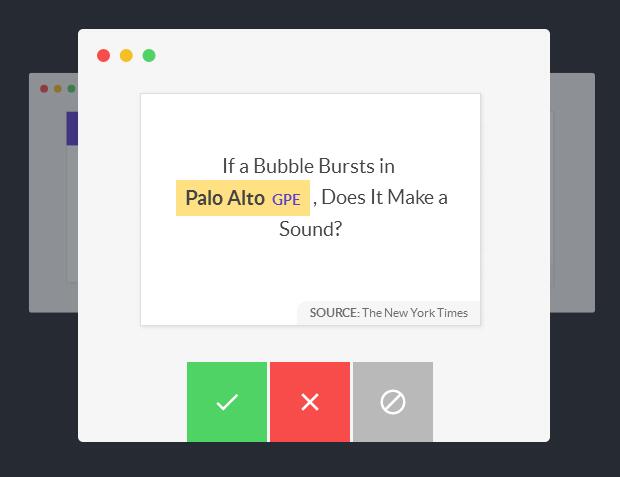
- 尝试动态演示:https://prodi.gy/demo
作为在Python中最流行的自然语言处理开源库spaCy的制造商,我们看到越来越多的公司意识到他们需要投资建立自己的人工智能技术。人工智能不是你可以从第三方供应商大量购买的商品。你需要构建自己的系统,拥有自己的工具并控制你的数据。Prodigy具有同样的思想。该工具是自包含的、可扩展的,并且永远是你的。无论你的管道有多复杂——如果你可以从Python函数中调用它,那么你就可以在Prodigy中使用它。
你可以和Prodigy做什么?
Prodigy的可插式架构使你可以很容易地使用你自己的组件来存储、加载、分类、示例选择甚至注释。它的内置功能支持简单而强大的工作流:
- 创建、改进或评估情绪分析、意图检测和任何其他文本分类任务的模型。
- 扩展spaCy最先进的命名实体识别器。
- 在你正在研究的文本上,提高spaCy模型的准确性。
- A/B测试机器翻译、字幕或图像处理系统。
- 注释图像分割和对象检测数据。
个人使用
适合自由职业者,独立开发人员,业余爱好者。内容包括:
- 使用12个月免费升级的终身许可。
- 个人和专业项目的无限制使用。
- Prodigy安装程序、web应用程序和广泛的文档。
售价:290美元
企业使用
适合创业公司,数据科学团队。内容包括:
- 使用12个月免费升级的终身许可。
- 为你和你的团队提供灵活且可转换的浮动许可证。
- Prodigy安装程序、web应用程序和广泛的文档。
售价:390美元,总共5个名额。
Prodigy官网:https://prodi.gy/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消