


















交互式机器学习:再次让Python变得“活泼”

你已经在Jupyter上编写了代码,它是一个无处不在的笔记本平台,用于编写和测试几乎所有主要的编程语言。你喜欢它,并且经常使用它。
但是你想要更多的控制,你想要在鼠标的简单滑动中改变变量,而不是通过写入for循环来改变。你应该做什么呢? 你可以使用IPython widget。
Python widget是什么?
Jupyter于2014年在IPython项目中诞生,并迅速发展,以支持所有主要编程语言的交互数据科学和科学计算。毫无疑问,它已经对数据科学家如何快速地测试和原型化他们的想法并将其展示给同行和开源社区产生了最大的影响。
然而,当用户能够交互式地控制模型的参数并查看实时的效果时,学习和试验数据就会变得真正的沉浸在其中。Jupyter中的大多数常见呈现都是静态的。然而,名为ipywidgets的元素在Jupyter notebook上展示了有趣的和交互式的控件。
Widget是在浏览器中有一个表示形式的重要的python对象,通常是通过前端(HTML/javascript)呈现通道的控件,比如滑动条、文本框等等。
之前的文章演示了使用基本的widget控件进行简单的曲线拟合练习。请阅读这篇文章,了解有关安装这个widget包的说明。在本文中将进一步扩展到交互机器学习技术领域。
交互式线性回归
我们用交互控制元素来演示单变量的简单线性回归。注意,这个想法可以很容易地扩展到复杂的多变量、非线性的、基于核的回归。但是,为了简化可视化,我们在演示中只使用单个变量。
在我的Github库中,可以使用boiler plate代码。
- Github库地址:https://github.com/tirthajyoti/Widgets
我们在两个阶段展示了交互性。首先,我们将数据生成过程作为输入变量和相关噪声的统计属性的函数。下面是这个过程的视频,用户可以使用简单的滑块控件动态地生成和绘制非线性函数。
[video width="726" height="720" mp4="https://www.atyun.com/uploadfile/2017/12/videoplayback-2.mp4"][/video]
在这里,生成函数,又称“参考标准”(ground truth),它是一个四次多项式,噪声来自于高斯分布。接下来,我们将使用scikit-learn的多项式特性生成和pipeline方法来编写线性回归函数。一个机器学习pipeline流程的详细说明(参照:https://towardsdatascience.com/machine-learning-with-python-easy-and-robust-method-to-fit-nonlinear-data-19e8a1ddbd49)。在这里,我们将整个函数封装在另一个交互式控件widget中,以便能够动态地更改线性模型的各种参数。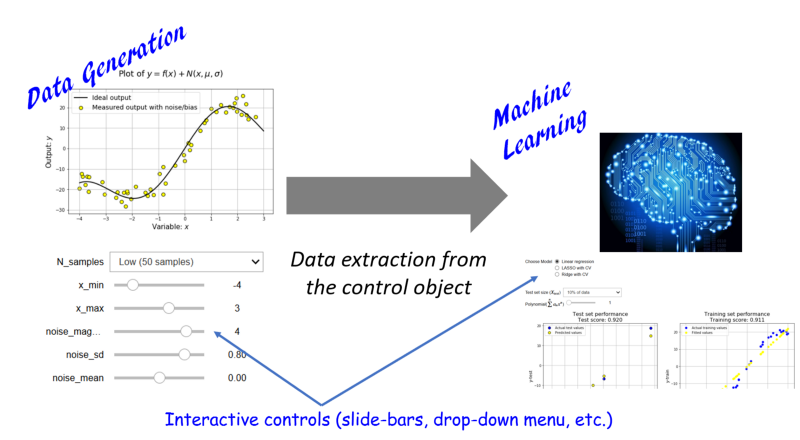 我们为下面的超参数引入交互控制。
我们为下面的超参数引入交互控制。
- 模型复杂性(多项式级)
- 正则化类型——LASSO或Ridge
- 测试集的大小(测试中使用的总样本数据的一小部分)
下面的视频展示了用户与线性回归模型的交互。请注意,测试和训练分数如何动态更新,以显示在模型复杂性变化时,过度拟合或不适应的趋势。我们可以回到数据生成控制,并增加降低噪声的大小,以观察其对拟合质量和偏差/方差的影响。
[video width="1058" height="720" mp4="https://www.atyun.com/uploadfile/2017/12/videopwdsWAlayback.mp4"][/video]









