


















外国网友如何使用机器学习将邮件分类? 其实很简单
背景:一名叫做Anthony Dm.的外国网友试图利用机器学习将一堆未标记的电子邮件进行分类,以下是他对这次操作发表的文章内容。
今天,我突然好奇将一堆未标记的电子邮件放在一个黑箱里,然后让机器弄清楚如何处理它们,会发生什么事情?但是,我没有任何想法。所以我做的第一件事就是找一个包含各种各样电子邮件的数据集。在研究了几个数据集之后,我想到了安然语料库(Enron corpus)。这个数据集有超过50万封来自安然公司员工的电子邮件,这些邮件数量对我接下来的训练已经足够了。
在编程语言方面,我使用Python连同它的强大的库:scikit-learn, pandas, numpy和matplotlib。
无监督机器学习
为了将未加标签的电子邮件集群化,我使用了无监督机器学习。是的,无监督,因为我只有输入的训练数据,也被称为特征,并且不包含结果。在监督机器学习中,我们使用输入及它们已知的结果。在这种情况下,我想根据信件内容对邮件进行分类,这绝对是一个无监督的机器学习任务。
在数据中加载
我没有在所有的50万封电子邮件中加载,而是将数据集分成了几个文件,每个文件都有1万封电子邮件。请相信我,你不会希望加载完整的安然数据集,并使用它进行复杂的计算。因为这会耗费太多的时间。
import pandas as pd
emails = pd.read_csv('split_emails_1.csv')
print emails.shape # (10000, 3)
现在,我在数据集中有1万封电子邮件,分为3列(索引、message_id和原始消息)。在处理这些数据之前,我将原始消息解析为key-value对。
下面是一个原始邮件消息的例子。
为了只处理发送人、接收人和邮件正文内容数据,我做了一个将这些数据提取到key-value对中的函数。
def parse_raw_message(raw_message):
lines = raw_message.split('\n')
email = {}
message = ''
keys_to_extract = ['from', 'to']
for line in lines:
if ':' not in line:
message += line.strip()
email['body'] = message
else:
pairs = line.split(':')
key = pairs[0].lower()
val = pairs[1].strip()
if key in keys_to_extract:
email[key] = val
return email
def parse_into_emails(messages):
emails = [parse_raw_message(message) for message in messages]
return {
'body': map_to_list(emails, 'body'),
'to': map_to_list(emails, 'to'),
'from_': map_to_list(emails, 'from')
}
在运行这个函数之后,我创建了一个新的DataFrame,它看起来如下:
email_df = pd.DataFrame(parse_into_emails(emails.message))
index body from_ to
0 After some... phillip.allen@.. tim.belden@..
百分百确定没有空列:
mail_df.drop(email_df.query(
"body == '' | to == '' | from_ == ''"
).index, inplace=True)
分析文本与TF-IDF
TF-IDF是术语词频–逆向文件频率(term frequency–inverse document frequency )的缩写,是一种数字统计数据,旨在反映一个词对集合或语料库中的文档的重要性。我需要给机器馈送(feed)一些它能理解的东西,机器虽然对文本不敏感,但是它们在数字上却能“发光”。这就是为什么我把邮件正文转换成一个文献-检索词矩阵(document-term matrix):
vect = TfidfVectorizer(stop_words='english', max_df=0.50, min_df=2)
X = vect.fit_transform(email_df.body)
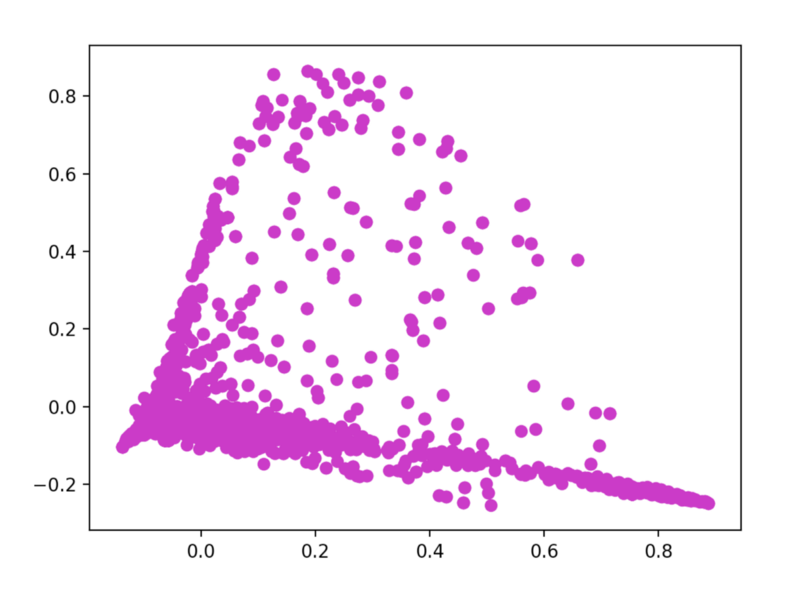
我快速地形象化了这个矩阵。为此,我首先需要对DTM(文献-检索词矩阵)进行二维表示。
X_dense = X.todense()
coords = PCA(n_components=2).fit_transform(X_dense)
plt.scatter(coords[:, 0], coords[:, 1], c='m')
plt.show()
 完成之后,我想找出这些邮件中最重要的关键词是什么。所以我把这个函数做得很精确:
完成之后,我想找出这些邮件中最重要的关键词是什么。所以我把这个函数做得很精确:
def top_tfidf_feats(row, features, top_n=20):
topn_ids = np.argsort(row)[::-1][:top_n]
top_feats = [(features[i], row[i]) for i in topn_ids]
df = pd.DataFrame(top_feats, columns=['features', 'score'])
return df
def top_feats_in_doc(X, features, row_id, top_n=25):
row = np.squeeze(X[row_id].toarray())
return top_tfidf_feats(row, features, top_n)
在一个文档上运行这个函数之后,它产生了以下结果。
features = vect.get_feature_names()
print top_feats_in_doc(X, features, 1, 10)
features score
0 meetings 0.383128
1 trip 0.324351
2 ski 0.280451
3 business 0.276205
4 takes 0.204126
5 try 0.161225
6 presenter 0.158455
7 stimulate 0.155878
8 quiet 0.148051
9 speaks 0.148051
10 productive 0.145076
11 honest 0.140225
12 flying 0.139182
13 desired 0.133885
14 boat 0.130366
15 golf 0.126318
16 traveling 0.125302
17 jet 0.124813
18 suggestion 0.124336
19 holding 0.120896
20 opinions 0.116045
21 prepare 0.112680
22 suggest 0.111434
23 round 0.108736
24 formal 0.106745
如果你查看下面相应的邮件内容,一切都会明白的。

下一步是编写一个函数来从所有的邮件中获取顶级术语(top terms)。
def top_mean_feats(X, features,
grp_ids=None, min_tfidf=0.1, top_n=25):
if grp_ids:
D = X[grp_ids].toarray()
else:
D = X.toarray()
D[D < min_tfidf] = 0
tfidf_means = np.mean(D, axis=0)
return top_tfidf_feats(tfidf_means, features, top_n)
从所有的邮件中返回到顶级术语。
print top_mean_feats(X, features, top_n=10)
features score
0 enron 0.044036
1 com 0.033229
2 ect 0.027058
3 hou 0.017350
4 message 0.016722
5 original 0.014824
6 phillip 0.012118
7 image 0.009894
8 gas 0.009022
9 john 0.008551
到目前为止,我所得到的结果是很有趣的,但是我想要更多地了解这台机器能够从这组数据中学到什么。
聚类与KMeans
KMeans是机器学习中使用的一种流行的聚类算法,K表示聚类(cluster)的数量。我创建了一个KMeans分类器,它有3种聚类和100次迭代。
n_clusters = 3
clf = KMeans(n_clusters=n_clusters, max_iter=100, init='k-means++', n_init=1)
labels = clf.fit_predict(X)
在训练了分类器之后,它产生了以下3种聚类。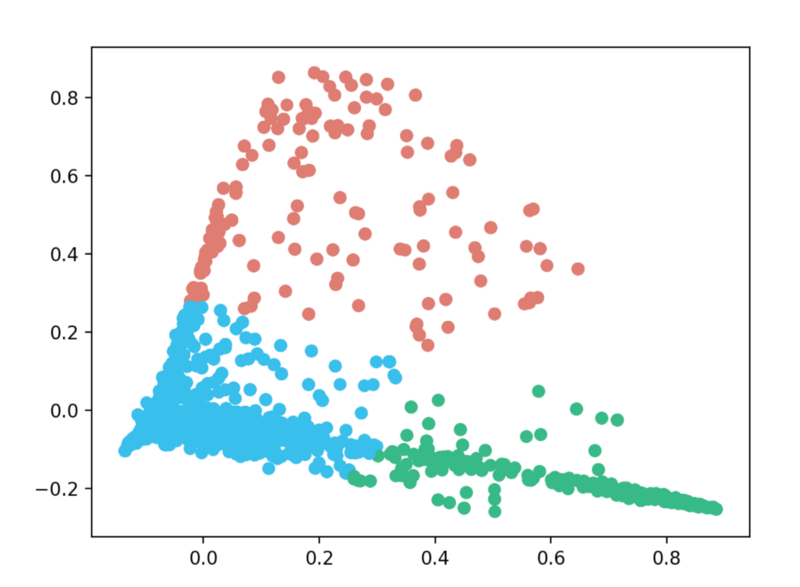
因为我现在知道了哪些邮件是机器分配给每个聚类的,所以我能够编写一个函数来提取每个聚类的顶级术语。
def top_feats_per_cluster(X, y, features, min_tfidf=0.1, top_n=25):
dfs = []
labels = np.unique(y)
for label in labels:
ids = np.where(y==label)
feats_df = top_mean_feats(X, features, ids, min_tfidf=min_tfidf, top_n=top_n)
feats_df.label = label
dfs.append(feats_df)
return dfs
我没有打印出这些术语,而是找到了一个很好的例子来说明如何用matlibplot来绘制这张图。所以我复制了这个函数,做了一些调整,然后得出了这个图: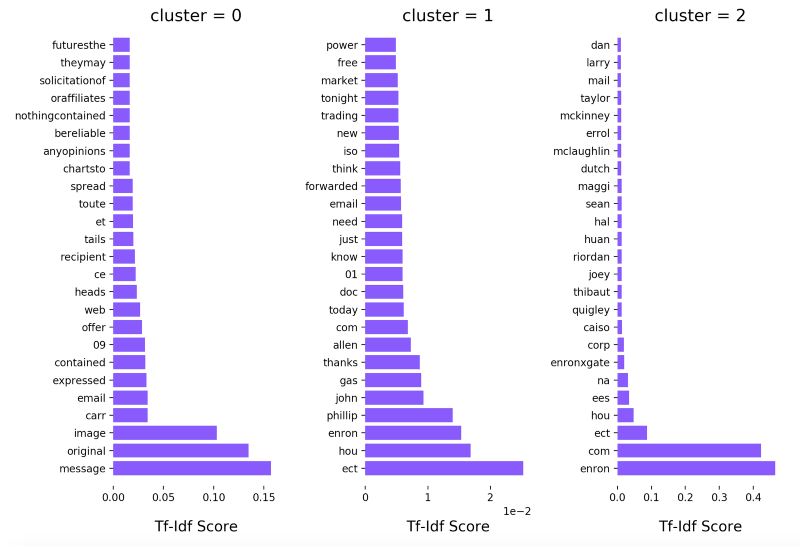
我立刻注意到聚类1,有一些奇怪的术语,比如“hou”和“ect”。为了更深入地了解为什么像“hou”和“ect”这样的术语如此“受欢迎”,我检查了数据集中的一些邮件,看看是否在其中找到一些答案。
Richard Burchfield
10/06/2000 06:59 AM
To: Phillip K Allen/HOU/ECT@ECT
cc: Beth Perlman/HOU/ECT@ECT
Subject: Consolidated positions: Issues & To Do list
在查看了数据集里的一些电子邮件之后,很明显这些术语是最热门的。它们几乎都是在每一个TO、CC(抄送)或BCC(密件抄送)的规则(rule)中。为了解决这个问题,我向Tfidfvectorizer添加了一些自定义的停止词(stopword)。因为停止词是一个冻结的列表,所以我做了一个拷贝,并把它传递给了vectorizer。
from sklearn.feature_extraction.text import TfidfVectorizer, ENGLISH_STOP_WORDS
stopwords = ENGLISH_STOP_WORDS.union(['ect', 'hou', 'com', 'recipient'])
vec = TfidfVectorizer(analyzer='word', stop_words=stopwords, max_df=0.3, min_df=2)
vec_train = vec.fit_transform(email_df.body)
添加停止词后的另一种聚类。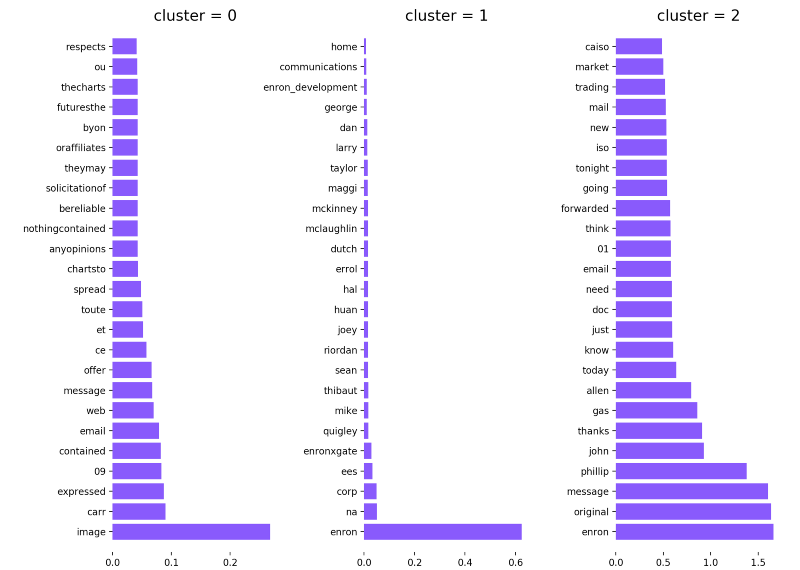
当我看着这张图的时候,我很快想到了三件事。
1.第一种聚类不包含令人兴奋的术语。
2.第二种聚类几乎由人的名字组成。
3.最后一种聚类看起来很有趣,绝对值得进一步研究。
我对Enron公司一无所知,但在看了最后一种聚类之后,不可否认的是“Phillip”和“John”这两家公司与Enron有一些重要的关系。
现在,我对那些聚类的邮件有了一些见解,现在是时候进一步进行我的研究了。
找到相关邮件
在发现了最流行的术语和最令人兴奋的邮件之后,我正在寻找一种方法来进一步分组与特定关键字相关的邮件。例如,发现所有与薪水(salary)或支出(expense)相关的邮件。
首先想到的方法是余弦相似性(cosine similarity)。这是一种常用的技术,用于测量数据挖掘领域里的聚类内的内聚性。
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。
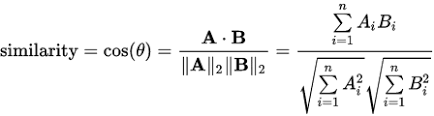
要找到一个邮件和所有其他邮件的余弦距离,我只需要计算第一个向量的点积和所有其他向量的点积,因为tfidf向量已经行标准化(row-normalized)了。为了得到第一个向量,我需要对矩阵行式(row-wise)进行切片(slice),以得到一个带有单行的子矩阵。
# The vector of the first email.
vec_train[0:1]
幸运的是,scikit-learn已经提供了成对的度量(metrics),度量在机器学习中的说法称之为内核(kernels),它适用于vector collection的密集和稀疏表示。在这种情况下,我需要一个点积,也就是所谓的线性内核(linear kernel)。
from sklearn.metrics.pairwise import linear_kernel
cosine_sim = linear_kernel(vec_train[0:1], vec_train).flatten()
print(cosine_sim)
[ 1. 0. 0. ..., 0. 0. 0.]
输出结果表明,第一个向量与数据集中的第一个邮件之间的余弦相似度是1,这是显而易见的,因为它是完全相同的邮件。
我希望看到与我能指定的“查询(query)”(例如,一个特定的关键字或术语)相关的邮件,而不是查找彼此相关的邮件。比方说,我想要找到所有相关的邮件到最后一个聚类中的一个顶级术语,例如“Phillip”,在这种情况下,我需要从查询(Phillip)中创建一个单独的向量,这个向量可以与原始向量相匹配。
vec = TfidfVectorizer(analyzer='word', stop_words=stopwords, max_df=0.3, min_df=2)
vec_train = vec.fit_transform(email_df.body)
query = "phillip"
vec_query = vec.transform([query])
cosine_sim = linear_kernel(vec_query, vec_train).flatten()
因此,为了找到与我的查询匹配的顶级的10个邮件,我使用了argsort函数和一些负面的数组切片(大多数相关的电子邮件具有更高的余弦相似值)。
related_email_indices = cosine_sim.argsort()[:-10:-1]
print(related_email_indices)
要查看这些邮件,我只需要查看它们的返回索引(indices)就可以了。
# Print out the first result
first_email_index = related_email_indices[0]
print(email_df.body.as_matrix()[first_email_index])
输出为:

为了使代码能够更加的可重复使用,我创建了一个类,可以快速查找任何我想要的术语或查询。
from sklearn.feature_extraction.text import TfidfVectorizer, ENGLISH_STOP_WORDS
from sklearn.metrics.pairwise import linear_kernel
from helpers import parse_into_emails
import pandas as pd
def read_email_bodies():
emails = pd.read_csv('split_emails.csv')
email_df = pd.DataFrame(parse_into_emails(emails.message))
email_df.drop(email_df.query("body == '' | to == '' | from_ == ''").index, inplace=True)
email_df.drop_duplicates(inplace=True)
return email_df['body']
class EmailDataset:
def __init__(self):
stopwords = ENGLISH_STOP_WORDS.union(['ect', 'hou', 'com', 'recipient'])
self.vec = TfidfVectorizer(analyzer='word', stop_words=stopwords, max_df=0.3, min_df=2)
self.emails = read_email_bodies()
# train on the given email data.
self.train()
def train(self):
self.vec_train = self.vec.fit_transform(self.emails)
def query(self, keyword, limit):
vec_keyword = self.vec.transform([keyword])
cosine_sim = linear_kernel(vec_keyword, self.vec_train).flatten()
related_email_indices = cosine_sim.argsort()[:-limit:-1]
return related_email_indices
def find_email_by_index(self, i):
return self.emails.as_matrix()[i]
在那之后,我忍不住要用更激动人心的关键词来搜索邮件,比如salary(薪水)或expenses(支出)。我做了一个新的查询,查找与关键字salary匹配的50个最相关的邮件。
ds = EmailDataset()
results = ds.query('salary', 100)
# print out the first result.
print(ds.find_email_by_index(results[0]))

另一个用于expense的查询,显示的第一个结果为:
总结
在本文中,我使用了一种无监督的聚类算法,让机器为邮件分组。在检查了这些聚类并发现了一些有趣的现象之后,我使用了一种更受监督的方法来分组与特定关键字相关的电子邮件。另外,还有很多更先进的技术,我们可以用它们来获得更深入的见解。









