











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenCV—Node.js教程系列:用Tensorflow和Caffe图像识别“做游戏”
2017年12月22日 由 xiaoshan.xiang 发表
174190
0

今天我们来看看OpenCV的深度神经网络模块。
如果你想要释放神经网络的awesomeness来识别和分类图像中的物体,但完全不知道深度学习如何工作,也不知道如何建立和训练神经网络了,那么我有好消息告诉你!
第一步要做什么呢?
在本教程中,我们将学习如何在OpenCV的DNN模块中加载来自Tensorflow和Caffe的预先训练的模型,我们将利用Node.js和OpenCV深入研究两个对象识别的例子。
首先,我们将使用Tensorflow的Inception模型来识别图像中显示的对象,然后使用COCO SSD模型在单个图像中检测和识别多个不同的对象。
让我们看看它是如何工作的!在我的github repo上可以找到示例的源代码。
github repo地址:https://github.com/justadudewhohacks/opencv4nodejs
Tensorflow Inception
在训练过程中,我们训练了Tensorflow Inception模型来识别1000类的对象。如果将图像输入到神经网络,它将输出图像中显示对象的每个类的可能性。
Tensorflow Inception地址:https://www.tensorflow.org/tutorials/image_recognition
要使用OpenCV的Inception模型,我们必须加载二进制的tensorflow_inception_graph.pb和来自imagenet_comp_graph_label_strings.txt的类名列表。你可以通过下载和解压缩“inception5h.zip”来获取这些文件。(见示例代码链接地址:https://github.com/justadudewhohacks/opencv4nodejs/blob/master/examples/dnnTensorflowInception.js)。
// replace with path where you unzipped inception model
const inceptionModelPath = '../data/dnn/tf-inception'
const modelFile = path.resolve(inceptionModelPath, 'tensorflow_inception_graph.pb');
const classNamesFile = path.resolve(inceptionModelPath, 'imagenet_comp_graph_label_strings.txt');
if (!fs.existsSync(modelFile) || !fs.existsSync(classNamesFile)) {
console.log('exiting: could not find inception model');
console.log('download the model from: https://storage.googleapis.com/download.tensorflow.org/models/inception5h.zip');
return;
}
// read classNames and store them in an array
const classNames = fs.readFileSync(classNamesFile).toString().split("\n");
// initialize tensorflow inception model from modelFile
const net = cv.readNetFromTensorflow(modelFile);
分类图像中的对象
为了对图像中的对象进行分类,我们将编写以下辅助函数:
const classifyImg = (img) => {
// inception model works with 224 x 224 images, so we resize
// our input images and pad the image with white pixels to
// make the images have the same width and height
const maxImgDim = 224;
const white = new cv.Vec(255, 255, 255);
const imgResized = img.resizeToMax(maxImgDim).padToSquare(white);
// network accepts blobs as input
const inputBlob = cv.blobFromImage(imgResized);
net.setInput(inputBlob);
// forward pass input through entire network, will return
// classification result as 1xN Mat with confidences of each class
const outputBlob = net.forward();
// find all labels with a minimum confidence
const minConfidence = 0.05;
const locations =
outputBlob
.threshold(minConfidence, 1, cv.THRESH_BINARY)
.convertTo(cv.CV_8U)
.findNonZero();
const result =
locations.map(pt => ({
confidence: parseInt(outputBlob.at(0, pt.x) * 100) / 100,
className: classNames[pt.x]
}))
// sort result by confidence
.sort((r0, r1) => r1.confidence - r0.confidence)
.map(res => `${res.className} (${res.confidence})`);
return result;
}这个函数的作用如下:
准备输入图像
首先我们要知道,Tensorflow Inception网络接受224x224大小的输入图像。这就是我们调整图像大小的原因,确保它最大的尺寸是224,我们用白色像素填充图像的剩余维度,比如宽度=高度(padToSquare)。
通过网络传递图像
我们可以简单地从图像创建一个blob并调用net . forward()正向传递输入并检索输出blob。
从输出blob中提取结果
为了泛化,输出blob将简单地表示为一个矩阵(cv.Mat),它的维数依赖于模型。Inception很简单。blob仅仅是一个1xN矩阵(其中N等于类的数量),它描述了所有类的概率分布。每个条目持有一个浮点数,代表对应类的置信度。这些条目总计增加到1.0(100%)。
我们想要更仔细地研究一下我们的图像最可能的类,因此我们正在寻找具有比minConfidence更大置信度的类(本例中为5%)。
这很容易实现,我们简单地将矩阵中的所有值设置为0.05,并查找所有未设置为零的条目(findNonZero)。最后,我们将根据置信度对结果进行排序,并利用置信度返回类名。
测试
现在我们将读取一些我们希望网络识别的样本数据:
const testData = [
{
image: '../data/banana.jpg',
label: 'banana'
},
{
image: '../data/husky.jpg',
label: 'husky'
},
{
image: '../data/car.jpeg',
label: 'car'
},
{
image: '../data/lenna.png',
label: 'lenna'
}
];
testData.forEach((data) => {
const img = cv.imread(data.image);
console.log('%s: ', data.label);
const predictions = classifyImg(img);
predictions.forEach(p => console.log(p));
console.log();
cv.imshowWait('img', img);
});
如果我们对每个图像进行预测,我们将得到以下输出(或查看标题图像):
banana:
banana (0.95)
husky:
Siberian husky (0.78)
Eskimo dog (0.21)
car:
sports car (0.57)
racer (0.12)
lenna:
sombrero (0.34)
cowboy hat (0.3)
相当有趣。我们对哈士奇和香蕉图像的内容有一个很精确的描述。对于汽车来说,我们可能会得到不同种类的汽车,但我们可以肯定地说,这是辆汽车一定在图像中出现。当然,网络不能在无限的类上被训练,这就是为什么它没有返回一些像“女人”这样的描述。然而,它识别出了这顶帽子。
COCO SSD
这很有效,但是我们如何处理显示多个对象的图像呢。为了在单个图像中识别多个对象,我们将使用所谓的单镜头多盒探测器(SSD)。在我们的第二个示例中,我们将研究一个SSD模型,它与COCO(环境中的通用对象)数据集进行了训练。我们使用的模型已经训练了84个不同的类。
COCO数据集地址:http://cocodataset.org/
由于这是一个Caffe模型,我们必须加载一个二进制的VGG_coco_SSD_300x300_iter_400000.caffemodel和一个 protoxt文件deploy.prototxt:
// replace with path where you unzipped inception model
const ssdcocoModelPath = '../data/dnn/coco-SSD_300x300'
const prototxt = path.resolve(ssdcocoModelPath, 'deploy.prototxt');
const modelFile = path.resolve(ssdcocoModelPath, 'VGG_coco_SSD_300x300_iter_400000.caffemodel');
if (!fs.existsSync(prototxt) || !fs.existsSync(modelFile)) {
console.log('exiting: could not find ssdcoco model');
console.log('download the model from: https://drive.google.com/file/d/0BzKzrI_SkD1_dUY1Ml9GRTFpUWc/view');
return;
}
// initialize ssdcoco model from prototxt and modelFile
const net = cv.readNetFromCaffe(prototxt, modelFile);
利用COCO进行分类
我们的分类函数看起来与初始阶段大致相同,但这次输入将是300x300图像,输出将是1x1xNx7矩阵。
const classifyImg = (img) => {
const white = new cv.Vec(255, 255, 255);
// ssdcoco model works with 300 x 300 images
const imgResized = img.resize(300, 300);
// network accepts blobs as input
const inputBlob = cv.blobFromImage(imgResized);
net.setInput(inputBlob);
// forward pass input through entire network, will return
// classification result as 1x1xNxM Mat
let outputBlob = net.forward();
// extract NxM Mat
outputBlob = outputBlob.flattenFloat(outputBlob.sizes[2], outputBlob.sizes[3]);
const results = Array(outputBlob.rows).fill(0)
.map((res, i) => {
const className = classNames[outputBlob.at(i, 1)];
const confidence = outputBlob.at(i, 2);
const topLeft = new cv.Point(
outputBlob.at(i, 3) * img.cols,
outputBlob.at(i, 6) * img.rows
);
const bottomRight = new cv.Point(
outputBlob.at(i, 5) * img.cols,
outputBlob.at(i, 4) * img.rows
);
return ({
className,
confidence,
topLeft,
bottomRight
})
});
return results;
};我不太清楚为什么输出是1x1xNx7矩阵,但实际上我们只对Nx7部分感兴趣。为了将第3和第4维度映射到一个2D矩阵中,我们可以使用flattenFloat utility。将这个与Inception 初始输出矩阵进行比较,这个次数N并不对应于每个类,而是对应于检测到的每个对象。此外,我们最终得到了每个对象的7个条目。
为什么是7项?
记住,这里的问题有点不同。我们想要检测每个图像的多个对象,因此我们不仅可以给每个类一个置信度。我们实际想要的是一个表示图像中每个对象位置的矩形。下面你可以找到每个条目对应的内容:
0.我真的不知道。
1.工作对象的类标签
2.置信度
3.矩形的最左x
4.矩形底部的y
5.矩形最右边的x
6.矩形顶部的y
输出矩阵给出了一些关于结果的非常简洁的信息。我们可以再次通过置信度来过滤结果,并将矩形绘制成每个识别对象的图像。
行动过程
为了简单起见,我将跳过绘制矩形和其他所有用于可视化的内容的代码。如果你想知道怎么做,你可以看看样本代码。
让我们把汽车的图像输入网络,然后用分类名称 car 来过滤结果:

好了!现在做一些有难度的。让我们尝试…早餐桌上的物品?
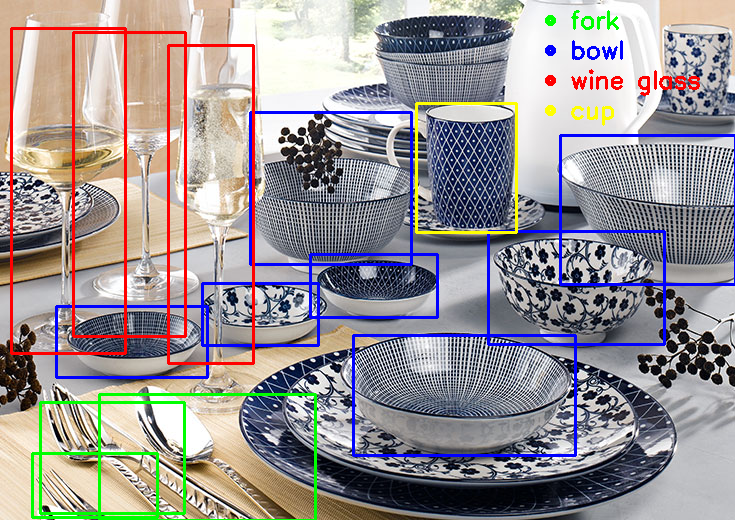
结语
这就是使用OpenCV和Node.js来神经网络识别图像中物体的过程。如果你用它来进行娱乐,我建议你去看看 Caffe Model Zoo,它为不同的使用案例提供了一些训练过的模型,你可以下载。
Caffe Model Zoo地址:https://github.com/BVLC/caffe/wiki/Model-Zoo

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消