











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






一文读懂在深度学习中使用迁移学习的好处
2018年01月07日 由 yuxiangyu 发表
707343
0
迁移学习是一种使用为任务开发的模型做第二个任务模型起点的机器学习方法。
使用预训练模型作计算机视觉和自然语言处理任务的起点是深度学习中一种流行的方法。因为在这些问题上开发神经网络模型需要的大量计算资源和时间资源,并且预训练模型能提供给相关问题技术的巨大助力。
在这篇文章中,你会了解如何使用迁移学习来加速训练并改善深度学习模型的表现。
阅读这篇文章后,你会知道:

迁移学习是一种机器学习技术:一个训练用于完成某个任务上的模型被重新用于第二个相关任务上。
- 第526页,深度学习,2016。
迁移学习是一种优化,可以让你对第二个任务建模的进展变快或提高它的性能。
- 第11章:迁移学习,机器学习应用研究手册,2009年。
迁移学习与多任务学习和概念漂移等问题有关,并不完全是一个深度学习的研究领域。
由于训练深度学习模型需要巨大的计算资源或使用庞大的数据集,所以在深度学习中的迁移学习非常流行。
如果从第一个任务学习的模型特征是通用(general)的,迁移学习才在深度学习中起作用。
- 深度神经网络中的特征如何迁移?
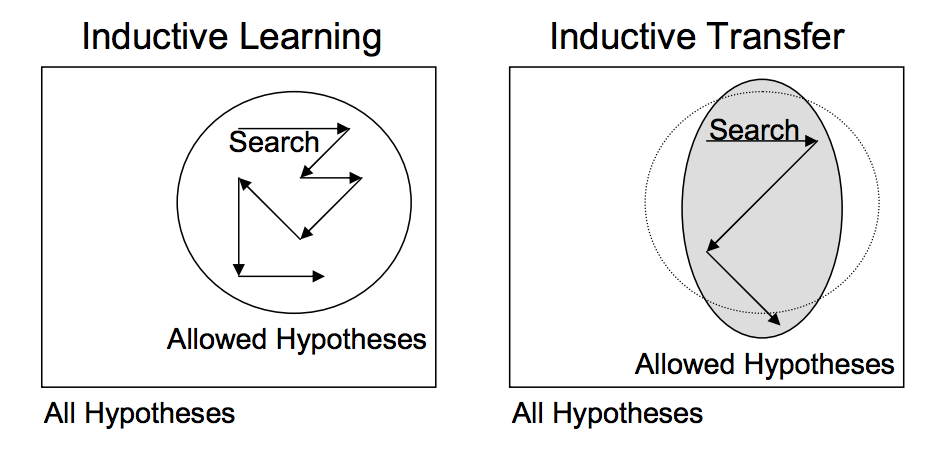
以这种形式用于深度学习的迁移学习被称为归纳迁移(inductive transfer)。这就是通过使用适合于不同但相关任务的模型,使可能模型的范围(模型偏差)以有利的方式缩小。
你可以在你自己的预测建模问题上使用迁移学习。两种常用方法如下:
这种第二类转移学习在深度学习领域是很常见的。
让我们用深度学习模型的两个常见的转移学习的例子来具体说明。
使用图像数据作为输入的预测性建模问题进行转移学习是很常见的。
这可能是以照片或视频数据作为输入的预测任务。
对于这些类型的问题,通常使用预先训练好的深度学习模型来处理大型和具有挑战性的图像分类任务,例如ImageNet 1000级照片分类竞赛。
为此次竞赛开发模型的研究机构经常发布最终的模型,并允许重复使用。这些模型可能需要几天或几周才能在现代硬件上进行训练。
这些模型可以下载,并直接合并到需要图像数据作为输入的新模型中。
这种模型的三个例子包括:
有关更多示例,请参阅Caffe模型动物园,其中共享了更多预先训练的模型。
这种方法是有效的,因为图像是在大量的照片上进行训练的,并且要求模型对相对较多的类进行预测,反过来要求模型有效地学习从照片中提取特征以便良好地执行问题。
在“斯坦福大学关于视觉识别的卷积神经网络课程”中,作者谨慎地选择在新模型中使用多少预训练模型。
- 迁移学习,CS231n卷积神经网络的视觉识别
使用文本作为输入或输出的自然语言处理问题进行传输学习是很常见的。
对于这些类型的问题,使用单词嵌入,即将单词映射到高维连续矢量空间,其中具有相似含义的不同单词具有相似的矢量表示。
存在有效的算法来学习这些分布式文字表示,研究机构通常会发布预先训练过的模型,这些模型是根据许可许可证在非常大的文本文档上进行训练的。
这种类型的两个例子包括:
这些分布式单词表示模型可以被下载并且被合并到深度学习语言模型中,或者作为输入的单词的解释或者作为模型输出的单词的生成。
Yoav Goldberg在他的“深度学习自然语言处理”一书中警告说:
- 第135页,自然语言处理中的神经网络方法,2017。
转移学习是一种优化,是节省时间或获得更好性能的捷径。
一般来说,直到模型开发和评估之后,在领域中使用转移学习才有好处。
Lisa Torrey和Jude Shavlik在转移学习的章节中描述了使用转移学习时要注意的三个可能的好处:
理想的情况下,你会看到成功应用转移学习的三个好处。
如果你能够用丰富的数据识别相关的任务,并且你有资源为该任务开发模型并在自己的问题上重复使用它,或者有可用的预训练模型你自己的模型的起点。
在一些你可能没有太多数据的问题上,转移学习可以使你发展熟练的模式,在没有转移学习的情况下你根本无法发展。
源数据或源模型的选择是一个公开的问题,可能需要通过经验开发的领域专业知识和/或直觉。
如果想深入了解,本节将提供更多有关该主题的资源。
在这篇文章中,你了解了如何使用迁移学习来加速训练并提高深度学习模型的性能。
具体来说,你了解到:
使用预训练模型作计算机视觉和自然语言处理任务的起点是深度学习中一种流行的方法。因为在这些问题上开发神经网络模型需要的大量计算资源和时间资源,并且预训练模型能提供给相关问题技术的巨大助力。
在这篇文章中,你会了解如何使用迁移学习来加速训练并改善深度学习模型的表现。
阅读这篇文章后,你会知道:
- 什么是迁移学习,以及它的使用方法。
- 深度学习中迁移学习的常见例子
- 什么时候在自己的预测建模问题上使用迁移学习。
什么是迁移学习?
迁移学习是一种机器学习技术:一个训练用于完成某个任务上的模型被重新用于第二个相关任务上。
迁移学习和域适应(domain adaptation)指的是在一个环境中学到的东西被利用来改善另一环境中的泛化
- 第526页,深度学习,2016。
迁移学习是一种优化,可以让你对第二个任务建模的进展变快或提高它的性能。
迁移学习是通过从已学习的相关任务中转移知识来改善新任务的学习。
- 第11章:迁移学习,机器学习应用研究手册,2009年。
迁移学习与多任务学习和概念漂移等问题有关,并不完全是一个深度学习的研究领域。
由于训练深度学习模型需要巨大的计算资源或使用庞大的数据集,所以在深度学习中的迁移学习非常流行。
如果从第一个任务学习的模型特征是通用(general)的,迁移学习才在深度学习中起作用。
在迁移学习中,我们首先在基础数据集和任务上训练一个基础网络,然后将学习到的特征重新调整或者转移到第二个目标网络上以训练目标数据集和任务。如果这些特征是通用的,这个过程往往会起作用,这意味着特征适合于基础任务和目标任务,而不是只适合于基础任务。
- 深度神经网络中的特征如何迁移?
以这种形式用于深度学习的迁移学习被称为归纳迁移(inductive transfer)。这就是通过使用适合于不同但相关任务的模型,使可能模型的范围(模型偏差)以有利的方式缩小。
如何使用转移学习?
你可以在你自己的预测建模问题上使用迁移学习。两种常用方法如下:
- 开发模型方法
- 预训练的模型方法
开发模型方法
- 选择源任务。你必须选择与大量数据相关的预测建模问题,这个大量数据要求输入数据、输出数据以及从输入到输出数据映射过程中学习的概念之间存在某种关系。
- 开发源模型。接下来,你必须为这个第一项任务开发一个熟练的模型。该模型必须比原始模型更好,以确保已经执行了一些特征学习。
- 重(chong)用模型。然后可以将适合于源任务的模型用作第二任务的模型的起点。这可能涉及使用全部或部分模型,这取决于所使用的建模技术。
- 调整模型。模型可能需要进行调整
- 对可用于任务的输入 - 输出配对数据调整或改进模型(视情况而定)。
预训练的模型方法
- 选择来源模型。预先训练的源模型是从可用的模型中选择的。许多研究机构发布了大量具有挑战性的数据集的模型,这些数据集可能包含在可供选择的候选模型库中。
- 重用模型。模型预先训练的模型然后可以被用作关于第二任务的模型的起点。这可能涉及使用全部或部分模型,这取决于所使用的建模技术。
- 调整模型。可选地,可能需要对可用于感兴趣任务的输入 - 输出配对数据调整或改进模型。
这种第二类转移学习在深度学习领域是很常见的。
深度学习转移学习的例子
让我们用深度学习模型的两个常见的转移学习的例子来具体说明。
转移学习与图像数据
使用图像数据作为输入的预测性建模问题进行转移学习是很常见的。
这可能是以照片或视频数据作为输入的预测任务。
对于这些类型的问题,通常使用预先训练好的深度学习模型来处理大型和具有挑战性的图像分类任务,例如ImageNet 1000级照片分类竞赛。
为此次竞赛开发模型的研究机构经常发布最终的模型,并允许重复使用。这些模型可能需要几天或几周才能在现代硬件上进行训练。
这些模型可以下载,并直接合并到需要图像数据作为输入的新模型中。
这种模型的三个例子包括:
有关更多示例,请参阅Caffe模型动物园,其中共享了更多预先训练的模型。
这种方法是有效的,因为图像是在大量的照片上进行训练的,并且要求模型对相对较多的类进行预测,反过来要求模型有效地学习从照片中提取特征以便良好地执行问题。
在“斯坦福大学关于视觉识别的卷积神经网络课程”中,作者谨慎地选择在新模型中使用多少预训练模型。
[卷积神经网络]特征在早期图层中更为通用,后面的图层更具有原始数据集特有的特征
- 迁移学习,CS231n卷积神经网络的视觉识别
迁移学习与语言数据
使用文本作为输入或输出的自然语言处理问题进行传输学习是很常见的。
对于这些类型的问题,使用单词嵌入,即将单词映射到高维连续矢量空间,其中具有相似含义的不同单词具有相似的矢量表示。
存在有效的算法来学习这些分布式文字表示,研究机构通常会发布预先训练过的模型,这些模型是根据许可许可证在非常大的文本文档上进行训练的。
这种类型的两个例子包括:
这些分布式单词表示模型可以被下载并且被合并到深度学习语言模型中,或者作为输入的单词的解释或者作为模型输出的单词的生成。
Yoav Goldberg在他的“深度学习自然语言处理”一书中警告说:
...可以下载训练过的预先训练过的单词向量,在训练状态和基础语料上的差异对结果表示有很大的影响,并且可用的预先训练的表示可能不是最好的选择你的特定用例。
- 第135页,自然语言处理中的神经网络方法,2017。
何时使用转移学习?
转移学习是一种优化,是节省时间或获得更好性能的捷径。
一般来说,直到模型开发和评估之后,在领域中使用转移学习才有好处。
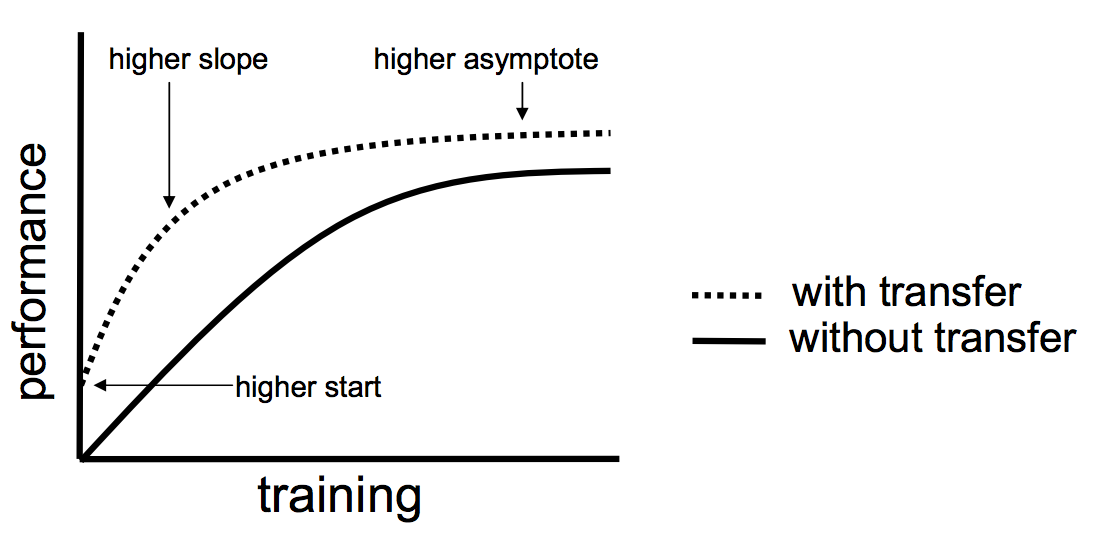
Lisa Torrey和Jude Shavlik在转移学习的章节中描述了使用转移学习时要注意的三个可能的好处:
- 更高的开始。源模型中的初始技能(在提炼模型之前)比其他方法要高。
- 较高的坡度。在训练源模型期间技能的提高速度比其他情况下更陡峭。
- 较高的渐近线。训练好的模型的融合技能要好于其他情况。
理想的情况下,你会看到成功应用转移学习的三个好处。
如果你能够用丰富的数据识别相关的任务,并且你有资源为该任务开发模型并在自己的问题上重复使用它,或者有可用的预训练模型你自己的模型的起点。
在一些你可能没有太多数据的问题上,转移学习可以使你发展熟练的模式,在没有转移学习的情况下你根本无法发展。
源数据或源模型的选择是一个公开的问题,可能需要通过经验开发的领域专业知识和/或直觉。
进一步阅读
如果想深入了解,本节将提供更多有关该主题的资源。
书
- 深度学习,2016(http://amzn.to/2fwdoKR)
- 自然语言处理中的神经网络方法,2017(http://amzn.to/2fwTPCn)
论文
- 关于迁移学习的调查,2010(https://pdfs.semanticscholar.org/a25f/bcbbae1e8f79c4360d26aa11a3abf1a11972.pdf)
- 第11章:迁移学习,机器学习应用研究手册,2009年(http://amzn.to/2fgeVro)
- 深度神经网络中的特征如何转移?(https://arxiv.org/abs/1411.1792)
预训练的模型
- Oxford VGG Model(http://www.robots.ox.ac.uk/~vgg/research/very_deep/)
- Google Inception Model(https://github.com/tensorflow/models/tree/master/inception)
- Microsoft ResNet Model(https://github.com/KaimingHe/deep-residual-networks)
- Google’s word2vec Model(https://code.google.com/archive/p/word2vec/)
- Stanford’s GloVe Model(https://nlp.stanford.edu/projects/glove/)
- Caffe Model Zoo(https://github.com/BVLC/caffe/wiki/Model-Zoo)
文章
- 维基百科中的迁移学习(https://en.wikipedia.org/wiki/Transfer_learning)
- Transfer Learning – Machine Learning’s Next Frontier, 2017.(http://ruder.io/transfer-learning/)
- Transfer Learning, CS231n Convolutional Neural Networks for Visual Recognition(http://cs231n.github.io/transfer-learning/)
- How does transfer learning work? on Quora(https://www.quora.com/How-does-transfer-learning-work)
总结
在这篇文章中,你了解了如何使用迁移学习来加速训练并提高深度学习模型的性能。
具体来说,你了解到:
- 什么是迁移学习,以及如何在深度学习中使用。
- 何时使用迁移学习。
- 用于计算机视觉和自然语言处理任务的转换学习的例子。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消