











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如果我告诉你数据库索引是可以学习的,你会怎么做?
2017年12月27日 由 xiaoshan.xiang 发表
694843
0

这篇论文是我在NIPS中看到的,在过去的几天里,在ML的圈子里得到了相当多的关注。论文中反复强调:在他们的心里,数据库索引是模型。它们可能不(通常)是有统计学意义的,但它们是提供(希望相当快的)输入(索引创建的关键)和输出(内存中的位置)之间的映射的结构。二叉树,是一种典型的有序数据结构,甚至采用了树的形式,这是机器学习工具箱中的核心工具。
论文地址:https://www.arxiv-vanity.com/papers/1712.01208/
在这一关键的直觉上,该论文提出了这样的问题:如果这些结构只是模型,那么可以通过统计模型来学习,然后利用这些模型,被索引的数据的分布比目前使用的索引更好,更小,更有效吗?剧透:答案(至少对于数值型数据类型)是肯定的。
例如,它可能的情况是,所有的元素都是一样的长度,并且每个数字键的位置都会增加5:在这种情况下,你可以很容易地学习键和位置之间的线性回归映射,其速度远远超过有序分裂的B树。B树在最坏的情况下也是有效的,在这种情况下,数字键位置的CDF密度(如果你将其排序为一行的话)是真正随机的,并且假设其是未知的。
关于B树的一个有趣的事实是,每当添加新数据时,它们都需要重新平衡,作者认为这与重新训练模型类似。因此,出于比较的目的,他们只是比较了训练集的性能,因为B树和候选统计模型只有在经过重新训练才会起作用。
作者通过训练一个基线模型开始:包含2层,32个隐藏单元,并且紧密相连的网络。这个模型有两个主要问题。
- 首先,它生成预测min / max的搜索位置作为关键函数的速度非常缓慢:它需要在Tensorflow中训练,这需要很高的前期成本,对于这个小模型来说不值得。
- 其次,它在单个键的级别上并不是很精确。虽然它在学习累积键分布的整体形状方面做得很好,但它避免了CDF函数中局部变量的过度拟合,因此当你在关键空间的小区域“放大”时,它就变得不那么准确了。正因为如此,它并没有显著地加快查找过程,而是在做一个完整的基线键扫描。按照他们设计这个问题的思路,一个简单的模型可以很容易地将预期搜索误差从1亿减少到10000,但是由于模型中固有的平滑性假设,很难将其降低到100s量级。
解决这些问题有两个关键的解决方案:一个是实现细节,一个是理论创新。第一个是相对简单的(至少在概念上是这样):构建一个框架,通过该框架,你可以在Tensorflow中训练模型,但是模型的推理阶段是在c++中进行评估的。这使得以前测试的基准模型的性能显着提高:从80,000ns降至30ns。
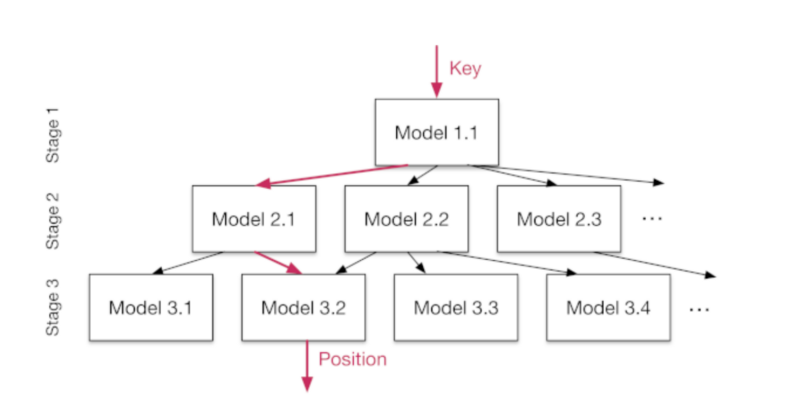
第二,框架作为解决“最后一英里”精度问题的解决方案,是递归模型。在这个框架中,我们从训练一个“顶层”模型开始,该模型输出对键的位置的预测。然后,我们把空间分成三个部分,然后分别学习每个子区域的模型。例如,顶层模型可以预测出,在一个10000长内存区域内,键4560将映射到位置2000。因此,他们根据顶层模型的预测,将观测结果分组,并对新模型进行特定训练,比如,预测位置在0到3500之间的键。
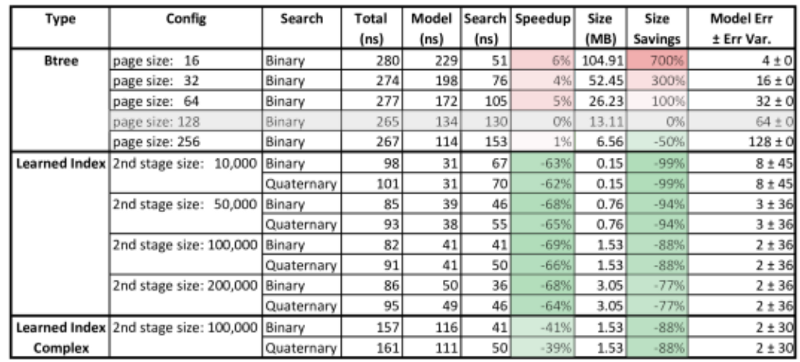
当这种方法——使用优化代码的层次结构模型——在带有数字键值的数据上进行尝试时,结果令人印象深刻。与B树相比,学习索引实现了有意义的提速,提高了超过60%。值得注意的是,下面的结果并不使用GPU。这表明,如果GPU在数据库硬件中变得更标准,这种改进甚至可能会增加。
它们目前只显示了对数字键建模的成果,但建议将目前用于文本(RNNs,character -level CNNs)的更复杂的方法添加到这个通用框架中。
为什么所有这些都是有趣的,除了可能导致新一代数据库索引设计的实际事实?
首先,我要承认,这篇论文在我在心里有特殊的意义。它除了介绍一些引人注目的ML概念之外,还使我更深入、更清晰地思考了索引工作背后的机制,而以前,这一直是我简单理解但没有深入研究的内容。
其次,利用机器学习模型来优化他们所运行的各种低级系统,这似乎有现实意义。这是我记得的第一批使用机器学习来优化计算过程的论文之一,但似乎不太可能是最后一个。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
利用机器学习实现工程洞察自动化








广告


写评论取消
回复取消