











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






全面指南:通过机器学习对Youtube视图进行预测
2018年01月13日 由 xiaoshan.xiang 发表
111382
0
这个项目是由艾伦·王,Aravind Srinivasan,Kevin Yee和Ryan O ' farrell设计的。脚本和模型可以在这里找到。
脚本和模型地址:https://github.com/allenwang28/YouTube-Virality-Predictor
在我们的模型中输入你自己的缩略图和标题来预测视频视图。
模型地址:https://enigmatic-wave-74142.herokuapp.com/
在过去的5年中,YouTube向YouTube的内容创作者支付了超过50亿美元。PewDiePie在2016年仅靠YouTube就赚了500万美元,不包括YouTube之外的赞助、代言和其他交易。随着越来越多的公司利用YouTube来吸引千禧一代的观众,在YouTube上观看视频变得越来越有利可图。

我们的目标是创建一个模型,帮助预测下一个视频的视图计数。Youtube上涵盖各种类型的视频,如喜剧、体育、时尚、游戏和健身。健身视频是YouTube的重要组成部分。人们倾向于选择免费的在线健身视频,而不是聘请昂贵的私人教练。
在YouTube上观看相关视频的人将首先看到标题和缩略图。如果可以使用特定的标题和缩略图生成更多的潜在视图,那么Youtube用户可以使用这些信息来生成具有视频内容的最大值的潜在视图。因此,我们的目标是创建一个使用非视频功能的模型来预测健身视频发布者可以使用的视图计数以推广其频道。
因为无法找到一个合适的数据集,所以我们只能使用YouTube的8M数据集,其中包含32 GB的预先标注的数据,这些数据被标记为不同的类型(比如运动、时尚、电影)。我们过滤掉了所有与“健身和体育”相关的标签,还剩余15305个视频。为了增加我们的数据集的大小,我们去掉了先前数据集中每个用户的视频。我们现在有115362个视频。我们为每个视频收集了以下特征:
YouTube的8M数据集地址:https://research.google.com/youtube8m/
我们关注视频的标题和缩略图,因为这些是用户在浏览视频时最先看到的内容。我们必须从缩略图和标题中提取有意义的特性,在我们的模型中体现它们。
类似于我们在BuzzFeed等网站上看到的标题诱饵的效果,我们希望看到标题诱饵和缩略图在YouTube视频上产生良好的效果。我们注意到一些成功吸引用户关注的健身视频,有以下常见的特征:
我们尝试在标题和缩略图上训练神经网络,但是没有得到很好的结果。
我们决定采用不同的路线——使用预先训练的网络作为特征提取器。我们在Yahoo找到了一个开源的NSFW Scorer。我们在先前标题、当前标题和缩略图上运行这些,并提供了代表它们的信息的新特性,从以此产生新的可用特征。
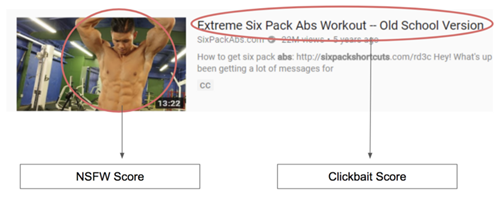
我们的主要目标是生成一个模型来预测视图的数量(或者视图的差异)。首先,我们删除一些离群值——也就是那些“病毒式”视频,我们将视图计数超过10万的视频定义为“病毒式”视频。
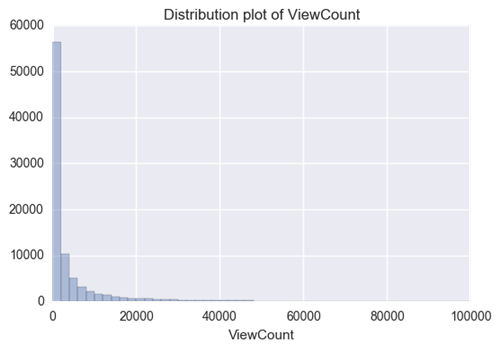
我们可以看到,视图计数分布严重扭曲,但却可以理解——大多数YouTube用户可能不会有这么多的视图。而且,YouTube-8M数据集视频似乎是随机抽取的(也就是说,不偏向流行视频),因为它的目标是为分类提供视频信息。
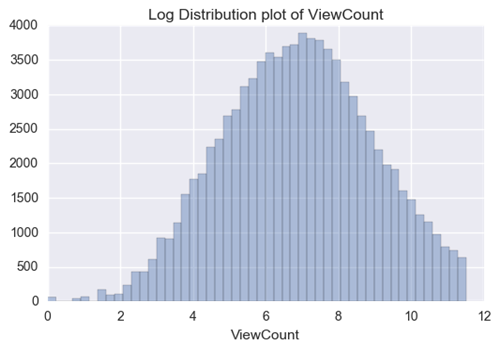
当我们最终得到预测因子时,我们想要预测类似于高斯曲线的东西。幸运的是,我们可以将日志转换应用到视图计数中,以使其能够做到这一点。
另一个我们可以试着预测的是视图计数的不同。我们从删除异常值开始——视频的视图计数增加或减少超过5x。
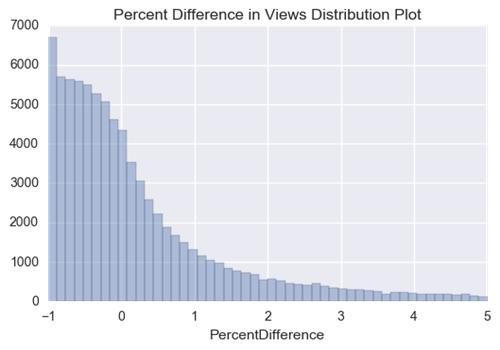
请注意,在我们的视频中,视图之间的差异通常在0左右波动,但实际上以-1为中心。 这被计算为:
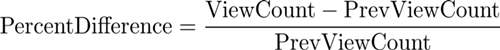
因此,百分比差值大约为-1的条目是当前视频的视图计数大约为0的条目。这很有趣 - 我们当前视图计数的大部分都是最近被刮掉的视频。 可能是这样的情况:视频没有足够长的时间来获得它的“真实”视图计数,可以这么说,我们可能需要一个特征来表示上传和删除它之间的时间。
最后,让我们来看看我们从标题和缩略图中提取的特征:
标题诱饵分数
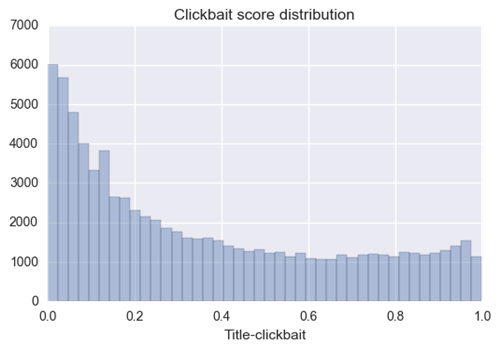
我们使用预先训练的网络为每个标题提取标题诱饵分数。 标题诱饵分数从0到1,分数越高,标题就越具有吸引力。 标题诱饵分数分布如下:
我们感兴趣的是YouTube用户是否在他们的频道上使用了不同级别的标题诱饵。所以我们计算了每个YouTube视频的标题诱饵分数的差异并绘制出了分布图:
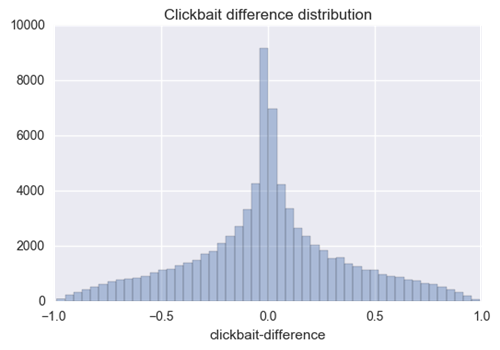
有趣的是,我们看到标题诱饵得分的差异看起来像一个零均值的高斯曲线。这意味着我们不希望YouTube用户在他们的标题中出现默认的“clickbait - iness”。
最后,我们比较了排名前10%和后10%的点击数:
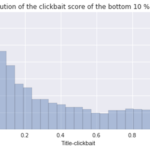
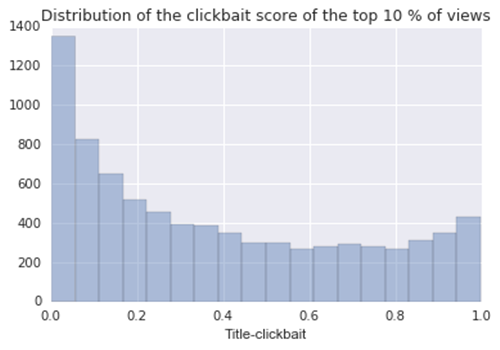
事实证明,“clickbait-y”标题不限于顶级的YouTube用户,它可能不会用一个十分安全的方式来产生更多的意见。“clickbait-iness”对查看次数的总体影响尚不清楚,但我们认为这一特征在我们的模型中不会提供太多的预测能力。
接下来,我们看看标题诱饵分数和视图计数之间的实际散点图:
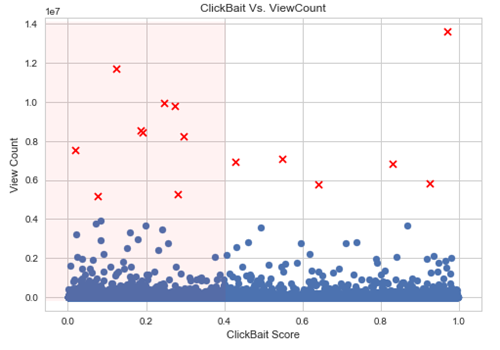
从这个图中,我们注意到视图计数和标题诱饵得分之间并没有多少关联,这意味着标题诱饵可能不是扩散的先决条件。
接下来,我们决定看看标题中的实际单词。
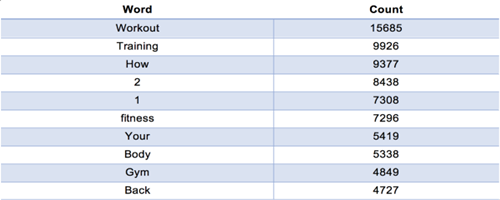
常见的词和语法
为了验证我们在标题中使用的技巧,我们决定找出最常用的单词和语法。过滤掉一些常见的单词,比如“the”,“to”,“and”等,一些非常普通的单词和单词:

NSFW得分
让我们看一下我们从缩略图中提取的NSFW分数的分布:
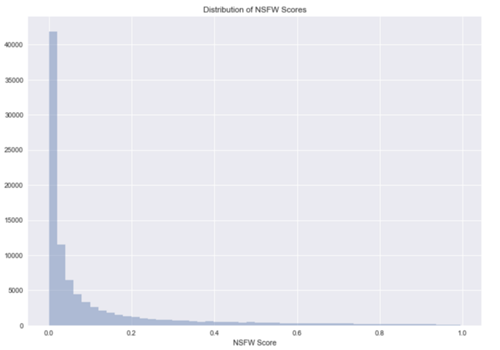
NSFW得分严重偏向0,均值是0.107。当我们看NSFW平均分数为前10%的观看视频和最后10%的观看视频时,我们发现这很有趣。
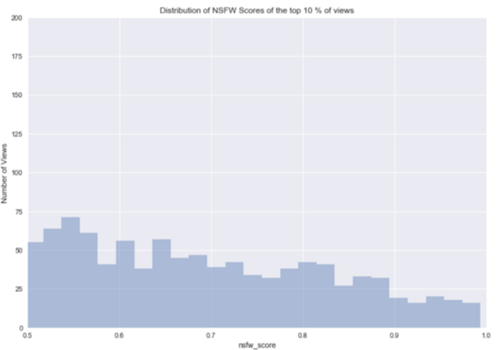
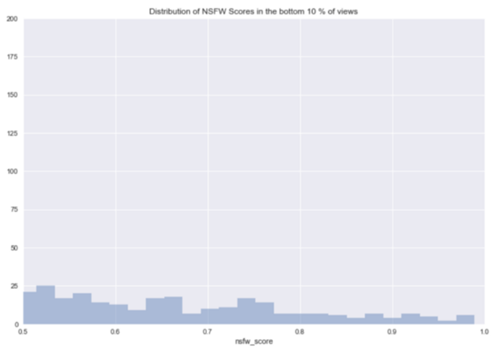
在前10%的情况下,nsfw_score的平均值是0.158,而在最后的10%中,nsfw_score的平均值是0.069。这似乎比诱饵标题分数提供了更多的预测能力,并且证实了我们所知道的所有的长期性卖点。
使用GradientBoostedRegressor,我们绘制特性重要度:
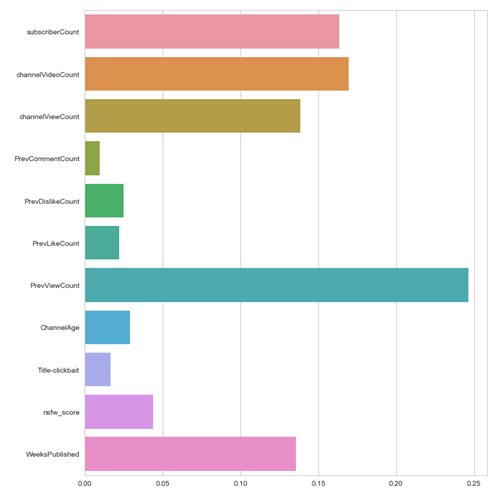
最终,看起来过往表现决定了未来的成功。你的频道最好的预测因素是你之前的视频的观看次数。缩略图的暗示性质和视频标题的“点击率”对观看者所能看到的视图计数的影响很小。最后,我们使用了XGBRegressor来预测日志转换的视图计数。我们使用交叉验证来获得:
R² = 0.750 ± 0.007
RMSE = 0.970 ± 0.021
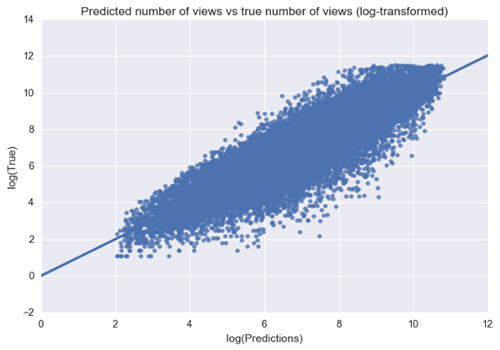
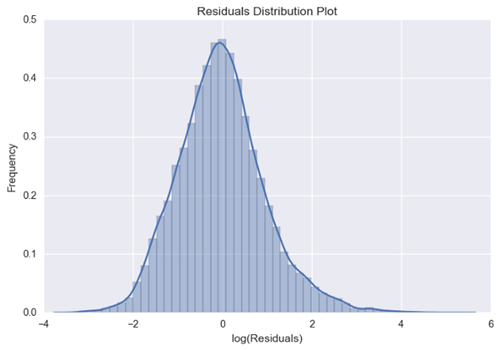
从我们对真实值图的预测,我们可以看到模型和数据似乎拟合的很好。另外,残差图意味着误差的偏差是由于零均值高斯分布。
最后,我们指数化输出来得到真实的视图计数:
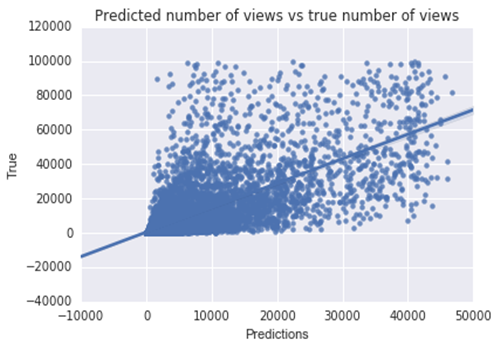
RMSE = 8727.0 ± 100.9
这意味着如果使用我们预测器的YouTube用户,可以预期实际结果在模型结果的8800个实际视图之内。对于一个拥有大约1000个视图的业余YouTube用户来说,这没有什么作用,但是对于一个拥有10万个视图的YouTube用户来说,它是非常有用的。然而,预测视图计数是困难的,所以这些结果是我们所期望的。
最初,当我们计划这个项目时,我们试图预测标题和缩略图本身的视图的数量。不幸的是,我们很快发现,视图的数量更多地与通道信息本身有关——它们的视图典型数量、订阅者数量等。本节将介绍我们尝试过的各种其他模型,以评估标题和缩略图对视图的影响。
标题的反馈神经网络/ LSTMs
由于我们有两个单独的文本序列,所以我们需要找到一种方法来将它们呈现为网络的输入。我们决定将先前的和当前的标题合并为一个明显的分离标记。如果在不同的标题之间确实有区别,那么网络应该获得它。
我们使用GloVe嵌入将每个标题转换成一个序列的向量,然后0 - p相加每个序列长度相同。
GloVe嵌入地址:https://nlp.stanford.edu/projects/glove/
首先,我们尝试了一个网络,它是一个相当标准的用于NLP任务的网络:

我们注意到网络训练迅速,但虽然训练损失迅速减少,但验证损失却开始增加。这表明这个模型可能过度拟合了。记住这一点,我们建立了第二个网络:

不同的是,在这个新的网络中,我们添加了更多的LSTM单位和另一个LSTM层。为了避免过度拟合,我们对每一项都进行了更多的规范化。我们训练了大约30个epoch,注意到训练损失会略有下降,但是验证损失也会有很大的波动。最终,仅仅使用视频的标题会产生比信号更多的噪音。每一个epoch都需要很长的时间来训练,特别是在许多的LSTM单元,所以我们决定不继续这条路线。
卷积神经网络:性别
这里的目的是验证缩略图中的人的性别是否与视图的数量相关。我们用这个预先训练好的CNN来提取一个二元性别特征。然而,和大多数性别分类CNN一样,我们的网络在识别缩略图中的面孔方面也遇到了问题。我们的网络也很难处理没有人物的缩略图。考虑到这种方法的问题,以及从每个缩略图中提取人脸所需要的时间,我们决定不将其作为特征提取器使用。
CNN地址:https://github.com/yu4u/age-gender-estimation
对于这个项目,我们有很多不同的想法。我们最初试图预测只给出标题和缩略图的视图计数。我们希望神经网络能够学习隐藏的功能,就像YouTube用户写的标题和创建的缩略图一样,但很快就发现这只是一厢情愿的想法。相反,我们能够找到比原始标题和缩略图更有意义的特征,并最终能够创建一个预测器,可以用于适当规模的YouTube频道。如果我们有更多的时间,我们可以尝试更多的事情:
脚本和模型地址:https://github.com/allenwang28/YouTube-Virality-Predictor
在我们的模型中输入你自己的缩略图和标题来预测视频视图。
模型地址:https://enigmatic-wave-74142.herokuapp.com/
背景
在过去的5年中,YouTube向YouTube的内容创作者支付了超过50亿美元。PewDiePie在2016年仅靠YouTube就赚了500万美元,不包括YouTube之外的赞助、代言和其他交易。随着越来越多的公司利用YouTube来吸引千禧一代的观众,在YouTube上观看视频变得越来越有利可图。
我们的目标是创建一个模型,帮助预测下一个视频的视图计数。Youtube上涵盖各种类型的视频,如喜剧、体育、时尚、游戏和健身。健身视频是YouTube的重要组成部分。人们倾向于选择免费的在线健身视频,而不是聘请昂贵的私人教练。
在YouTube上观看相关视频的人将首先看到标题和缩略图。如果可以使用特定的标题和缩略图生成更多的潜在视图,那么Youtube用户可以使用这些信息来生成具有视频内容的最大值的潜在视图。因此,我们的目标是创建一个使用非视频功能的模型来预测健身视频发布者可以使用的视图计数以推广其频道。
数据
因为无法找到一个合适的数据集,所以我们只能使用YouTube的8M数据集,其中包含32 GB的预先标注的数据,这些数据被标记为不同的类型(比如运动、时尚、电影)。我们过滤掉了所有与“健身和体育”相关的标签,还剩余15305个视频。为了增加我们的数据集的大小,我们去掉了先前数据集中每个用户的视频。我们现在有115362个视频。我们为每个视频收集了以下特征:
YouTube的8M数据集地址:https://research.google.com/youtube8m/
- 标题
- 缩略图
- 描述
- 喜欢数量
- 不喜欢数量
- 视图计数
- 最喜欢数量
- 评论数量
- 发表日期
- 频道用户数量
- 频道发布的视频数量
- 整个频道的视图计数
- 频道发布的前一段视频的评论数量
- 频道发布的前一段视频的视图计数
- 频道发布的前一段视频的标题
- 频道年限
特性工程和提取
我们关注视频的标题和缩略图,因为这些是用户在浏览视频时最先看到的内容。我们必须从缩略图和标题中提取有意义的特性,在我们的模型中体现它们。
类似于我们在BuzzFeed等网站上看到的标题诱饵的效果,我们希望看到标题诱饵和缩略图在YouTube视频上产生良好的效果。我们注意到一些成功吸引用户关注的健身视频,有以下常见的特征:
- 标题过度夸张并使用了感叹号
- 标题提供了保证和承诺
- 标题包括一个列表
- 缩略图包括一个与标题相符的男人或女人
我们尝试在标题和缩略图上训练神经网络,但是没有得到很好的结果。
我们决定采用不同的路线——使用预先训练的网络作为特征提取器。我们在Yahoo找到了一个开源的NSFW Scorer。我们在先前标题、当前标题和缩略图上运行这些,并提供了代表它们的信息的新特性,从以此产生新的可用特征。
数据探索
我们的主要目标是生成一个模型来预测视图的数量(或者视图的差异)。首先,我们删除一些离群值——也就是那些“病毒式”视频,我们将视图计数超过10万的视频定义为“病毒式”视频。
我们可以看到,视图计数分布严重扭曲,但却可以理解——大多数YouTube用户可能不会有这么多的视图。而且,YouTube-8M数据集视频似乎是随机抽取的(也就是说,不偏向流行视频),因为它的目标是为分类提供视频信息。
当我们最终得到预测因子时,我们想要预测类似于高斯曲线的东西。幸运的是,我们可以将日志转换应用到视图计数中,以使其能够做到这一点。
另一个我们可以试着预测的是视图计数的不同。我们从删除异常值开始——视频的视图计数增加或减少超过5x。
请注意,在我们的视频中,视图之间的差异通常在0左右波动,但实际上以-1为中心。 这被计算为:
因此,百分比差值大约为-1的条目是当前视频的视图计数大约为0的条目。这很有趣 - 我们当前视图计数的大部分都是最近被刮掉的视频。 可能是这样的情况:视频没有足够长的时间来获得它的“真实”视图计数,可以这么说,我们可能需要一个特征来表示上传和删除它之间的时间。
最后,让我们来看看我们从标题和缩略图中提取的特征:
标题诱饵分数
我们使用预先训练的网络为每个标题提取标题诱饵分数。 标题诱饵分数从0到1,分数越高,标题就越具有吸引力。 标题诱饵分数分布如下:
我们感兴趣的是YouTube用户是否在他们的频道上使用了不同级别的标题诱饵。所以我们计算了每个YouTube视频的标题诱饵分数的差异并绘制出了分布图:
有趣的是,我们看到标题诱饵得分的差异看起来像一个零均值的高斯曲线。这意味着我们不希望YouTube用户在他们的标题中出现默认的“clickbait - iness”。
最后,我们比较了排名前10%和后10%的点击数:
事实证明,“clickbait-y”标题不限于顶级的YouTube用户,它可能不会用一个十分安全的方式来产生更多的意见。“clickbait-iness”对查看次数的总体影响尚不清楚,但我们认为这一特征在我们的模型中不会提供太多的预测能力。
接下来,我们看看标题诱饵分数和视图计数之间的实际散点图:
从这个图中,我们注意到视图计数和标题诱饵得分之间并没有多少关联,这意味着标题诱饵可能不是扩散的先决条件。
接下来,我们决定看看标题中的实际单词。
常见的词和语法
为了验证我们在标题中使用的技巧,我们决定找出最常用的单词和语法。过滤掉一些常见的单词,比如“the”,“to”,“and”等,一些非常普通的单词和单词:
NSFW得分
让我们看一下我们从缩略图中提取的NSFW分数的分布:
NSFW得分严重偏向0,均值是0.107。当我们看NSFW平均分数为前10%的观看视频和最后10%的观看视频时,我们发现这很有趣。
在前10%的情况下,nsfw_score的平均值是0.158,而在最后的10%中,nsfw_score的平均值是0.069。这似乎比诱饵标题分数提供了更多的预测能力,并且证实了我们所知道的所有的长期性卖点。
预测
使用GradientBoostedRegressor,我们绘制特性重要度:
最终,看起来过往表现决定了未来的成功。你的频道最好的预测因素是你之前的视频的观看次数。缩略图的暗示性质和视频标题的“点击率”对观看者所能看到的视图计数的影响很小。最后,我们使用了XGBRegressor来预测日志转换的视图计数。我们使用交叉验证来获得:
R² = 0.750 ± 0.007
RMSE = 0.970 ± 0.021
从我们对真实值图的预测,我们可以看到模型和数据似乎拟合的很好。另外,残差图意味着误差的偏差是由于零均值高斯分布。
最后,我们指数化输出来得到真实的视图计数:
RMSE = 8727.0 ± 100.9
这意味着如果使用我们预测器的YouTube用户,可以预期实际结果在模型结果的8800个实际视图之内。对于一个拥有大约1000个视图的业余YouTube用户来说,这没有什么作用,但是对于一个拥有10万个视图的YouTube用户来说,它是非常有用的。然而,预测视图计数是困难的,所以这些结果是我们所期望的。
模型可能需要更多的调查
最初,当我们计划这个项目时,我们试图预测标题和缩略图本身的视图的数量。不幸的是,我们很快发现,视图的数量更多地与通道信息本身有关——它们的视图典型数量、订阅者数量等。本节将介绍我们尝试过的各种其他模型,以评估标题和缩略图对视图的影响。
标题的反馈神经网络/ LSTMs
由于我们有两个单独的文本序列,所以我们需要找到一种方法来将它们呈现为网络的输入。我们决定将先前的和当前的标题合并为一个明显的分离标记。如果在不同的标题之间确实有区别,那么网络应该获得它。
我们使用GloVe嵌入将每个标题转换成一个序列的向量,然后0 - p相加每个序列长度相同。
GloVe嵌入地址:https://nlp.stanford.edu/projects/glove/
首先,我们尝试了一个网络,它是一个相当标准的用于NLP任务的网络:
我们注意到网络训练迅速,但虽然训练损失迅速减少,但验证损失却开始增加。这表明这个模型可能过度拟合了。记住这一点,我们建立了第二个网络:
不同的是,在这个新的网络中,我们添加了更多的LSTM单位和另一个LSTM层。为了避免过度拟合,我们对每一项都进行了更多的规范化。我们训练了大约30个epoch,注意到训练损失会略有下降,但是验证损失也会有很大的波动。最终,仅仅使用视频的标题会产生比信号更多的噪音。每一个epoch都需要很长的时间来训练,特别是在许多的LSTM单元,所以我们决定不继续这条路线。
卷积神经网络:性别
这里的目的是验证缩略图中的人的性别是否与视图的数量相关。我们用这个预先训练好的CNN来提取一个二元性别特征。然而,和大多数性别分类CNN一样,我们的网络在识别缩略图中的面孔方面也遇到了问题。我们的网络也很难处理没有人物的缩略图。考虑到这种方法的问题,以及从每个缩略图中提取人脸所需要的时间,我们决定不将其作为特征提取器使用。
CNN地址:https://github.com/yu4u/age-gender-estimation
结论
对于这个项目,我们有很多不同的想法。我们最初试图预测只给出标题和缩略图的视图计数。我们希望神经网络能够学习隐藏的功能,就像YouTube用户写的标题和创建的缩略图一样,但很快就发现这只是一厢情愿的想法。相反,我们能够找到比原始标题和缩略图更有意义的特征,并最终能够创建一个预测器,可以用于适当规模的YouTube频道。如果我们有更多的时间,我们可以尝试更多的事情:
- 扩大到不同的流派;
- 在评论中应用情绪分析来创建一个更稳健的可以作为特征使用的“用户配置文件”;
- 通过对评论的情绪分析来创建一个强大的可以预测的“接收”特征(类似于喜欢/不喜欢);
- 使用生成模型创建注释;
- 在缩略图上训练CNN——因为NSFW分数似乎比诱饵标题的分数提供了更多的预测能力,所以CNN对缩略图的应用可能比在标题上训练的LSTM更好。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消