











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






以超越精确性来提高对机器学习的信任
2018年01月15日 由 nanan 发表
300163
0

传统的机器学习工作流程主要集中在模型训练和优化上,最好的模型通常是通过像精确或错误这样的性能度量来选择的,我们倾向于假定一个模型如果超过了这些性能标准的某些阈值,就足以进行部署。然而,为什么一个模型做出的预测却被忽略了。但是能够理解和解释这些模型对于提高模型质量、增加信任和透明度以及减少偏差非常重要。由于复杂的机器学习模型本质上是黑盒子,而且太复杂,所以我们需要使用近似值来更好地了解它们的工作原理。其中一个方法是LIME,它代表局部可解释的模型-不可知的解释,并且是帮助理解和解释复杂机器学习模型所做决定的工具。
机器学习的准确性和误差
机器学习中的通用数据科学工作流程包括以下步骤:收集数据、清理和准备数据、训练模型,并根据验证和测试错误或其他性能标准选择最佳模型。尤其是那些为数字而活的数据科学家或统计学家,往往会因为小错误和高准确度而停下来。假设我们找到了一个能正确预测99%的测试用例模型,就其本身而言,这是一个非常好的表现,我们倾向于把这个模型展示给同事、团队领导、决策者或者其他可能对我们伟大模型感兴趣的人。最后,我们将模型部署到生产中。我们假设我们的模型是可信的,因为我们已经看到它表现得很好,但我们不知道它为什么表现得很好。
在机器学习中,我们通常看到准确性和模型复杂度之间的权衡:模型越复杂,解释起来就越困难。一个简单的线性模型很容易解释,因为它只考虑变量和预测因子之间的线性关系。但是由于它只考虑线性,所以它不能模拟更复杂的关系,而且测试数据的预测精度可能会更低。深层的神经网络处于另一端:由于它们能够推断出多个抽象层次,因此它们能够建模非常复杂的关系,从而达到非常高的准确性。但它们的复杂性也使得它们成为了黑盒子。我们不能理解模型中所有特征之间的复杂关系,因此我们必须使用性能标准,比如准确性和误差,作为我们相信模型的可靠性代表。
试图理解我们看似完美的模型所做的决定通常不是机器学习工作流程的一部分。那么为什么我们要花更多的时间和精力去理解模型,如果在技术上没有必要呢?
提高理解和解释复杂机器学习模型的一种方法是使用所谓的解释器函数。在我看来,模型理解和解释应该成为机器学习工作流程的一部分,其中有几个原因就是每个分类问题:
—模型改进
—信任和透明度
—识别和防止偏见
模型改进
理解特征、类和预测之间的关系,从而理解为什么机器学习模型做出了决定,哪些特性在这个决策中最重要,可以帮助我们决定它是否具有直观意义。
让我们来看看下面的例子:我们有一个深入的神经网络,用来区分狼和哈士奇的图像;它在许多图像上进行了训练,并在一组独立的图像上进行了测试。90%的测试图像被正确预测。但我们不知道的是,在没有解释器的情况下,这个模型的主要依据是背景:狼的图像通常有下雪的背景,而husky图像却很少。所以我们不知不觉地训练了一个雪地探测器…
有了关于如何和基于哪些特性模型预测的额外知识,我们可以直观地判断我们的模型是否正在采用有意义的模式,以及是否能够推广新的实例。
信任和透明度
了解我们的机器学习模型对于提高信任和提供关于他们的预测和决策的透明度也是必要的。考虑到新的“通用数据保护条例”(GDPR)将于2018年5月生效,这一点尤为重要。尽管关于第22条是否包含对算法派生决策的“解释权”仍然备受热议,但它可能还不足以让黑箱模型做出直接影响人们生活和生计的决策,比如贷款或监狱刑罚。
信任另一个特别重要的领域是医学。在这里,决定可能会给病人带来生死攸关的后果。机器学习模型在区分恶性肿瘤和不同类型的良性肿瘤方面有着惊人的准确性。但作为医学干预的依据,我们仍然需要专业人士对诊断的解释。解释为什么机器学习模型将某个病人的肿瘤分类为良性或恶性的依据,这将有助于医生信任并使用支持他们工作的机器学习模型。
即使在日常业务中,如果我们没有处理如此严重的后果,如果机器学习模式不能像预期的那样运行,它会产生非常严重的影响。对机器学习模型的更好理解可以节省大量时间,并防止长期的损失;如果一个模型没有做出明智的决定,我们可以在它进入部署之前捕获它并在那里造成破坏。
识别和防止偏见
机器学习模型中的公平性和偏见是一个被广泛讨论的话题。有偏见的模型往往是基于偏见的事实:如果我们用来训练我们模型的数据包含细微的偏差,我们的模型将会学习它们,从而传播一个自我实现的预言!其中一个著名的例子就是机器学习模型,用来建议囚犯的刑期,这显然反映了司法系统中种族不平等的固有偏见。其他的例子是用于招聘的模型,这些模型经常显示出我们的社会仍然对性别与特定职位的性别相关有偏见,比如男性软件工程师和女护士。
机器学习模型是我们生活中不同领域的有力工具,它们将变得越来越普遍。因此,作为数据科学家和决策者,我们的职责是了解我们开发和部署的模型如何做出决策,以便我们能够主动地防止偏见被强化和消除。
LIME
LIME代表本地可解释的模型-不可知的解释,是帮助理解和解释复杂机器学习模型所做决定的工具。它由Marco Ribeiro,Sameer Singh和Carlos Guestrin在2016年开发,可以用来解释任何分类模型,无论是随机森林,梯度增加树,神经网络等。适用于不同类型的输入数据,如表格数据(数据框)、图像或文本。
LIME的核心遵循三个概念:
—对于整个机器学习模型,在全球范围内并没有给出解释,但是在本地和每个实例中都是分开的
—即使机器学习模型可能对抽象工作起作用,也会给出原始输入特征的解释
—通过局部拟合一个简单模型的预测,给出了最重要特征的解释
这使我们能够大致了解哪些特性对单个实例的分类贡献最大,哪些特性与它相矛盾,以及它们是如何影响预测的。
下面的例子展示了如何使用LIME:
我在一个关于慢性肾病的数据上建立了随机森林模型。训练该模型以预测患者是否患有慢性肾病。该模型在验证数据上达到99%的准确率,在测试数据上达到95%。从技术上讲,我们可以在这里停下来宣布胜利。但是我们想知道为什么某些病人被诊断为慢性肾病,而其他人却没有。然后,一个医学专业人员就能够评估模型所学习的东西是否具有直观意义,是否可信。为了达到这个目的,我们可以使用LIME。
如上所述,LIME在每个实例上分别单独地工作。首先,我们举一个例子(在这个例子是来自一名患者的数据)并对其进行排列,也就是说,数据是通过轻微修改复制的。这将生成一个由类似实例组成的新数据集,它基于一个原始实例。对于这个per数据集中的每个实例,我们也计算了它与原始实例的相似程度,即在置换过程中所作的修改有多强。基本上,任何类型的统计距离和相似度度量都可以在此步骤中使用,例如,Euclidean距离转换为与指定宽度的指数内核相似。
接下来,我们之前训练过的复杂机器学习模型,将对每一个置换的实例进行预测。由于数据集的细微差别,我们可以跟踪这些变化如何影响预测。
最后,我们用一个简单的模型(通常是一个线性模型)对置换数据及其预测使用最重要的特征进行拟合。确定最重要的特性有不同的方法:我们通常定义我们想要包含的特性的数量(通常在5到10之间),然后:
—根据复杂机器学习模型的预测,在回归中选择权重最高的特征。
—应用正向选择,将特征添加到改进回归,以适应复杂机器学习模型的预测。
—根据复杂的机器学习模型预测,选择最小收缩的特性,并对其进行正则化。
—或者,根据我们选择的特性数量,将分支分割数量减少或相等的决策树匹配。
每个per实例和原始实例之间的相似性作为一个权重输入到简单的模型中,以便对与原始实例更相似的实例给予更高的重要性。这使我们不能使用任何简单的模型作为解释器,可以进行加权输入,例如ridge regression。
现在,我们可以解释原实例的预测。通过上面描述的示例模型,您可以看到如下图中6个患者/实例的8个最重要特征的LIME输出:
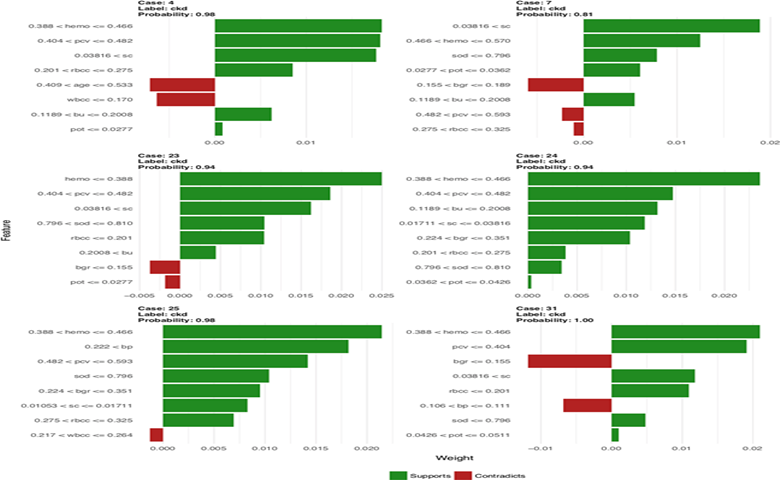
六个方面中的每一个方面都显示了对单个患者或实例的预测的解释。每个facet的头部给出了病例编号(这里是患者ID),并预测了类标签,且给出了概率。例如,上面的例子描述了被归类为“ckd”的案例4,概率为98%。在标题下面,我们找到了8个最重要特征的条形图;每条的长度显示特征的权重,正权重支持预测,负权重与之矛盾。再一次描述上方的例子:条状图显示血红蛋白的值在0.388到0.466之间,支持分类为“ckd”; packed cell volume (pcv)、血清肌酸酐(sc)等同样支持“ckd”的分类。另一方面,这个病人的年龄和白细胞计数(wbcc)更具有健康的特征,因此与“ckd”的分类相矛盾。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
算法没有偏见,我们有!
下一篇
使用机器学习来进行自动化文本分类








广告


写评论取消
回复取消