


















一文教你在Python中打造你自己专属的面部识别系统
人脸识别是用户身份验证的最新趋势。苹果推出的新一代iPhone X使用面部识别技术来验证用户身份。百度也在使“刷脸”的方式允许员工进入办公室。对于很多人来说,这些应用程序有一种魔力。但在这篇文章中,我们的目的是通过教你如何在Python中制作你自己的面部识别系统的简化版本来揭开这个主题的神秘性。
背景
在讨论实现的细节之前,我想讨论FaceNet的细节,它是我们将在我们的系统中使用的网络。
FaceNet
FaceNet是一个神经网络,它可以学习从脸部图像到紧凑的欧几里得空间(Euclidean space)的映射,在这个空间里,距离对应的是人脸的相似性。也就是说,两张面部图像越相似,它们之间的距离就越小。
Triplet Loss
FaceNet使用了一种名为Triplet Loss的独特的损失方法来计算损失。Triplet Loss最小化了anchor与正数之间的距离,这些图像包含相同的身份,并最大化了anchor与负数之间的距离,这些图像包含不同的身份。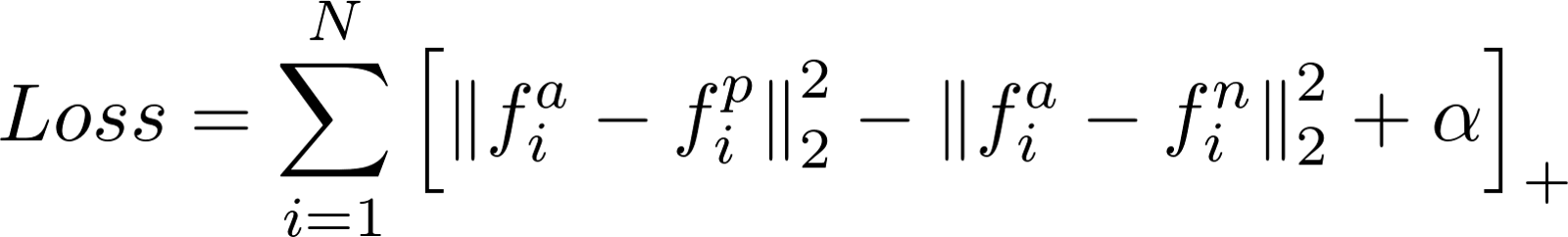
图1: Triplet Loss等式
- f(a)指的是anchor的输出编码
- f(p)指的是正的输出编码
- f(n)指的是负的输出编码
- α是一个常量,用来确保网络不会对f(a)-f(p)=f(a)-f(n)=0进行优化
- […]+等于最大值(0,总和)
Siamese网络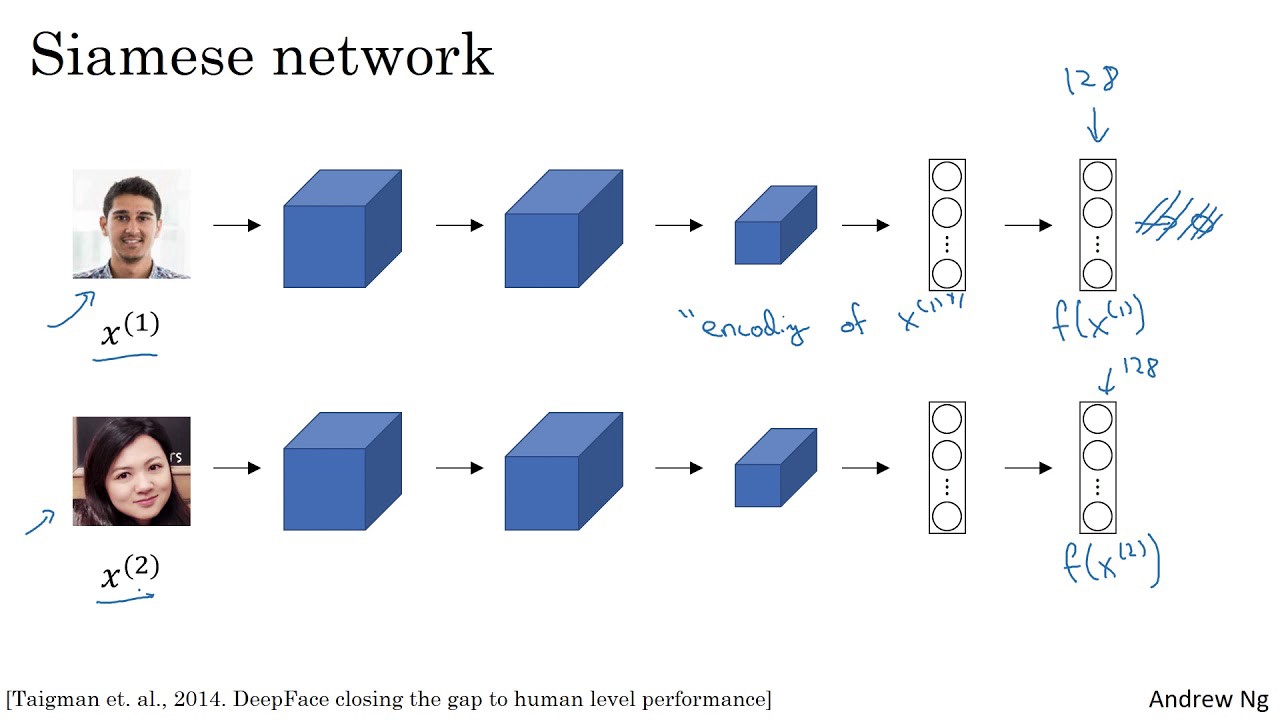
图2:一个Siamese网络的例子,它使用面部图像作为输入,输出一个128位数字编码的图像。
FaceNet是一个Siamese网络。Siamese网络是一种神经网络体系结构,它学习如何区分两个输入。这使他们能够了解哪些图像是相似的,哪些不是。这些图像可以包含面部图像。
Siamese网络由两个完全相同的神经网络组成,每个神经网络都有相同的权重。首先,每个网络将两个输入图像中的一个作为输入。然后,每个网络的最后一层的输出被发送到一个函数,该函数决定这些图像是否包含相同的身份。
在FaceNet中,这是通过计算两个输出之间的距离来完成的。
实现
既然我们已经阐明了这个理论,我们就可以直接去实现这个过程。在我们的实现中,我们将使用Keras和Tensorflow。此外,我们还使用了从deeplearning.ai的repo中得到的两个实用程序文件来为所有与FaceNet网络的交互做了个摘要:
- fr_utils.py包含了向网络提供图像的函数,并获取图像的编码
- inception_blocks_v2.py包含了准备和编译FaceNet网络的函数
Kera地址:https://keras.io/
Tensorflow地址:https://www.tensorflow.org/
deeplearning.ai的repo地址:https://github.com/shahariarrabby/deeplearning.ai/tree/master/COURSE%204%20Convolutional%20Neural%20Networks/Week%2004/Face%20Recognition
编译FaceNet网络
我们要做的第一件事就是编译FaceNet网络,这样我们就可以在面部识别系统中使用它。
import os
import glob
import numpy as np
import cv2
import tensorflow as tf
from fr_utils import *
from inception_blocks_v2 import *
from keras import backend as K
K.set_image_data_format('channels_first')
FRmodel = faceRecoModel(input_shape=(3, 96, 96))
def triplet_loss(y_true, y_pred, alpha = 0.3):
anchor, positive, negative = y_pred[0], y_pred[1], y_pred[2]
pos_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,
positive)), axis=-1)
neg_dist = tf.reduce_sum(tf.square(tf.subtract(anchor,
negative)), axis=-1)
basic_loss = tf.add(tf.subtract(pos_dist, neg_dist), alpha)
loss = tf.reduce_sum(tf.maximum(basic_loss, 0.0))
return loss
FRmodel.compile(optimizer = 'adam', loss = triplet_loss, metrics = ['accuracy'])
load_weights_from_FaceNet(FRmodel)
我们将以一个(3,96,96)的输入形状开始初始化我们的网络。这意味着红-绿-蓝(RGB)通道是向网络馈送的图像卷(image volume)的第一个维度。所有被馈送网络的图像必须是96x96像素的图像。
接下来,我们将定义Triplet Loss函数。上面的代码片段中的函数遵循我们在上一节中定义的Triplet Loss方程的定义。
一旦我们有了损失函数,我们就可以使用Keras来编译我们的面部识别模型。我们将使用Adam优化器来最小化由Triplet Loss函数计算的损失。
准备一个数据库
现在我们已经编译了FaceNet,我们准备一个我们希望我们的系统能够识别的个人数据库。我们将使用图像目录中包含的所有图像,以供我们的个人数据库使用。
注意:我们将只在实现中使用每个单独的图像。原因是FaceNet网络强大到只需要一个单独的图像就能识别它们!
def prepare_database():
database = {}
for file in glob.glob("images/*"):
identity = os.path.splitext(os.path.basename(file))[0]
database[identity] = img_path_to_encoding(file, FRmodel)
return database
对于每个图像,我们将把图像数据转换为128个浮点数的编码。我们通过调用函数img_path_to_encoding来实现这一点。该函数接受一个图像的路径,并将图像输入到我们的面部识别网络中。然后,它返回来自网络的输出,这恰好是图像的编码。
一旦我们将每个图像的编码添加到我们的数据库,我们的系统就可以开始识别人脸了!
识别人脸
正如在背景部分所讨论的,FaceNet被训练来尽可能地最小化同一个体的图像之间的距离,并使不同个体之间的图像之间的距离最大化。我们的实现使用这些信息来确定为我们的系统馈送的新图像最有可能是哪一个个体。
def who_is_it(image, database, model):
encoding = img_to_encoding(image, model)
min_dist = 100
identity = None
# Loop over the database dictionary's names and encodings.
for (name, db_enc) in database.items():
dist = np.linalg.norm(db_enc - encoding)
print('distance for %s is %s' %(name, dist))
if dist < min_dist:
min_dist = dist
identity = name
if min_dist > 0.52:
return None
else:
return identity
上面的函数将新图像输入到一个名为img_to_encoding的效用函数中。该函数使用FaceNet处理图像,并返回图像的编码。既然我们有了编码,我们就能找到最可能属于这个图像的那个个体。
为了找到个体,我们通过数据库,计算新图像和数据库中的每个个体之间的距离。在新图像中距离最小的个体被选为最有可能的候选。
最后,我们必须确定候选图像和新图像是否包含相同的对象。因为在我们的循环结束时,我们只确定了最有可能的个体。这就是下面的代码片段所发挥的作用。
if min_dist > 0.52:
return None
else:
return identity
- 如果距离大于0.52,那么我们将确定新图像中的个体不存在于我们的数据库中。
- 但是,如果距离等于或小于0.52,那么我们确定它们是相同的个体!
这里比较棘手的部分是,值0.52是通过在我的特定数据集上反复实验来实现的。最好的值可能要低得多或稍微高一些,这取决于你的实现和数据。我建议尝试不同的值,看看哪个值最适合你的系统!
使用面部识别建立一个系统
在这篇文章的开头,我链接到的Github库中的代码是一个演示,它使用笔记本电脑的摄像头来为我们的面部识别算法馈送视频帧。一旦算法识别出框架中的一个人,演示就会播放一个音频信息,它允许用户在数据库中使用它们的图像名称。图3显示了演示示例。

图3:当网络在图片中识别出个体时,图片即时被捕捉。数据库中图像的名称是“skuli.jpg”,因此播出的音频信息是“Welcome skuli, have a nice day!”
结论
现在,你应该熟悉了面部识别系统的工作方式,以及如何使用python中的FaceNet网络的预先训练版本来创建你自己的简化的面部识别系统。如果你想在Github库中进行演示,并添加你认识的人的图像,那么就可以继续使用这个库来进行你的下一次实验。









