使用Tensorflow对象检测在安卓手机上“寻找”皮卡丘
2018年01月23日 由 yining 发表
937285
0
在TensorFlow的许多功能和工具中,隐藏着一个名为TensorFlow对象探测API(TensorFlow Object Detection API)的组件。正如它的名字所表达的,这个库的目的是训练一个神经网络,它能够识别一个框架中的物体。这个库的用例和可能性几乎是无限的。它可以通过训练来检测一张图像上的猫、汽车、浣熊等等对象。本文将用它来实现皮卡丘的检测。
TensorFlow对象检测API:https://github.com/tensorflow/models/tree/master/research/object_detection

本文的目的是描述我在训练自己的自定义对象检测模型时所采取的步骤,并展示我的皮卡丘检测技能,以便你可以自己尝试。首先,我将从程序包的介绍开始。其次,我将继续讨论如何将我的皮卡丘图像转换为正确的格式并创建数据集。然后,我将尽可能详细地写关于训练的过程,以及如何评估它。最后,我将演示如何在Python notebook中使用该模型,以及将其导出到安卓手机的过程。

在应用中的检测的屏幕截图
这个程序包是TensorFlow对对象检测问题的响应——也就是说,在一个框架中检测实际对象(皮卡丘)的过程。它的独特之处在于它能够准确地记录速度和内存使用情况(反之亦然),因此你可以根据你的需要和你的选择平台(手机)来调整模型。这个库包含了许多不被发现的对象检测架构,如SSD(Single Shot MultiBox Detector)、Faster R-CNN(Faster Region-based Convolutional Neural Network)和R-FCN(Region-based Fully Convolutional Networks),以及一些特征提取器,如MobileNet、Inception和Resnet;这些提取器是非常重要的,因为它们在系统的速度/性能平衡中扮演了重要的角色。
此外,该库还提供了一些已经准备好的用于检测的模型,在Google Cloud中进行训练的选项,再加上TensorBoard的支持来监控训练。
既然我们已经了解了这个实验所使用的系统,我将继续解释如何构建你自己的自定义模型。
构建自己的自定义模型
安装
在我们开始之前,请确保你的计算机上安装了TensorFlow。接下来,clone包含对象检测API的repo,链接如下:
https://github.com/tensorflow/models
找到“
research”目录并执行:
# From tensorflow/models/research/
protoc object_detection/protos/*.proto --python_out=.
这个过程编译了Protobuf库。
Protobuf下载地址:
https://developers.google.com/protocol-buffers/docs/downloads
最后,你需要将库添加到PYTHONPATH中。可以通过执行下面的命令来完成:
# From tensorflow/models/research/
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
有关所需的所有依赖项的更多细节:
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md
现在来看看我是如何从许多皮卡丘图像到一个由TensorFlow读取的数据集。
创建数据集并处理图像
创建数据集是成功训练模型所需的众多步骤中的第一步,在本节中,我将介绍完成此任务所需的所有步骤。对于这个项目,我将230个中等大小的皮卡丘的图片下载到一个名为“images”的目录中。为了得到更好的结果,我试图从图像中获得不同角度和形状的皮卡丘,但老实讲,皮卡丘是一个不存在的黄色长耳的小老鼠,所以很难找到大量的合适的图像。
一些被使用的图像
一旦你获得了所有的图像,下一步就是对它们进行标记。这是什么意思? 因为我们在做对象检测,所以我们需要一个关于物体到底是什么的基本事实。为此,我们需要在对象周围画一个边框,让系统知道边框里面的“东西”是我们想要学习的实际对象。我用于这个任务的软件是一个叫RectLabel的Mac应用。
RectLabel:
https://rectlabel.com/
这就是一个带有边框的图像的样子:
 愤怒的皮卡丘。被一个边框包围着
愤怒的皮卡丘。被一个边框包围着
在RectLabel中,你需要为你的图像的每个边框设置一个标签,在我的例子中,标签是“Pikachu”。一旦你对所有图像进行了标记,你就会注意到你有一个名为“annotations”的目录,其中有许多XML文件用来描述每个图像的边框。
分成训练和测试数据集
一旦所有的图像都被贴上了标签,我的下一步就是将数据集分解成一个训练和测试数据集。在图像所在的同一个目录中,我创建了一个名为“
train”和“
test”的目录,并将大约70%的图像和它们各自的XML添加到“
train”目录,剩下的30%添加到“
test”目录。
生成TFRECORD
在数据集的分离之后,唯一缺少的是将我们的图像和它们的XML转换成一个由TensorFlow可读的格式。这种格式被称为“
tfrecord”,并且从我们的图像中生成它,需要两个步骤。首先,为了简单起见,两组XML(训练和测试)的数据都被转换为两个CSV文件(再一次,训练和测试),使用的是修改版本的xml_to_csv.py代码。
代码地址:
https://github.com/datitran/raccoon_dataset
然后,使用CSV文件,tfrecord数据集是使用脚本generate_tfrecord.py创建的(该脚本也能从上面的代码地址中找到)。请记住,在运行脚本之前,必须在函数class_text_to_int中指定对象的类。
创建标签映射
需要一个“
labels”映射,指示标签及其索引。下面就是他们的样子:
item {
id: 1
name: 'Pikachu'
}
将“Pikachu”标签替换为你想用的标签,并且重要的是,总是从index 1开始,因为index 0是预留的。我将这个文件在一个名为“training”的新目录下保存为object-detection.pbtxt。
训练模型
管道(The Pipeline)
完整的训练过程由一个称为“pipeline”的配置文件来处理。管道被划分为五个主要结构,负责定义模型、训练和评估过程参数,以及训练和评估数据集的输入。这条管道的架构是这样的:
model {
(... Add model config here...)
}
train_config : {
(... Add train_config here...)
}
train_input_reader: {
(... Add train_input configuration here...)
}
eval_config: {
}
eval_input_reader: {
(... Add eval_input configuration here...)
}
但是!你不必从头开始编写(write)整个管道。事实上,TensorFlow开发人员建议训练应该使用他们自己的和已经训练过的模型作为起点。这背后的原因是从头开始训练一个全新的模型可能需要相当长的时间。因此,TensorFlow提供了几个配置文件(下方),只需要很少的更改就可以使其在新的训练环境中工作。我使用的模型是ssd_mobilenet_v1_coco_11_06_2017。
在我的训练中,我使用了配置文件ssd_mobilenet_v1_pets.config作为一个起点。因为我的类的数量只有一个,所以我改变了变量num_classes。num_steps停止训练前,fine_tune_checkpoint指向模型下载的位置,还有train_input_reader和eval_input_reader的变量input_path和label_map_path指向训练和测试数据集与标签映射。
我不会细讲配置文件的每一个细节,不过,我想解释一下SSD和MobileNet是什么意思。SSD是一种基于单一前馈神经网络的神经网络结构。它被称为“single shot”,因为它可以预测图像的类和在同一步骤中表示检测(称为anchor)的边框的位置。与此相反的是一个架构,它需要一个称为“proposal generator”的第二个组件来预测该框的确切位置。MobileNet是一个卷积特征提取器,用于在移动设备上工作,用于获取图像的高级特征。一旦准备好了管道,就把它添加到“training”目录中。然后,继续使用下面的命令开始训练:
python object_detection/train.py --logtostderr
--train_dir=path/to/training/
--pipeline_config_path=path/to/training/ssd_mobilenet_v1_pets.config
在训练期间和之后评估模型
这个库提供了在训练期间和之后评估模型所需的代码。每次训练产生一个新的检查点时,评估工具将使用给定目录中可用的图像进行预测(在我的例子中,我使用了来自测试集中的图像)。要运行评估工具,执行以下操作:
python object_detection/eval.py --logtostderr
--train_dir=path/to/training/
--pipeline_config_path=path/to/training/ssd_mobilenet_v1_pets.config
--checkpoint_dir=path/to/training/ --eval_dir=path/to/training/
TensorBoard
通过TensorFlow的可视化平台TensorBoard,可以看到训练和评估阶段的结果。在这里,我们可以监控一些指标,如训练时间、总损失、步骤数等等。很酷的一点是,当模型被训练的时候,TensorBoard也可以工作,这是一个很好的工具,可以确保训练的方向是正确的。
要执行TensorBoard,请执行以下命令:
tensorboard --logdir=path/to/training/
导出模型
训练完成后,下一步是导出模型,以便可以使用它。为了执行这一步,该库提供了名为export_inference_graph.py的脚本。
在导出之前,请确保你在训练目录中有以下文件:
model.ckpt-${CHECKPOINT_NUMBER}.data-00000-of-00001,
model.ckpt-${CHECKPOINT_NUMBER}.index
model.ckpt-${CHECKPOINT_NUMBER}.meta
你可能有几个具有相同格式的文件,但是使用不同的检查点数量。因此,只需选择所需的检查点,并执行以下命令:
python object_detection/export_inference_graph.py
--input_type image_tensor
--
pipeline_config_path=path/to/training/ssd_mobilenet_v1_pets.config
--trained_checkpoint_prefix=path/to/training/model.ckpt-xxxxx
--output_directory path/to/output/directory
输出将是一个文件,该文件包含一个叫做frozen_inference_graph.pb模型的“冻结(frozen)”版本。
结果
在训练阶段结束时,该模型的精确度为87%,总损失为0.67。然而,在训练过程中,模型的精确度最高达到了95%。尽管如此,精确度最高的模型并没有达到我预期设想的结果。例如,它将许多黄色物体(甚至一些人)归类为皮卡丘。另一方面,我注意到,精确度为87%的模型产生的假阳性结果较少,因而忽略了一些皮卡丘。下面的图片是由TensorBoard制作的总损失和精确度图表。
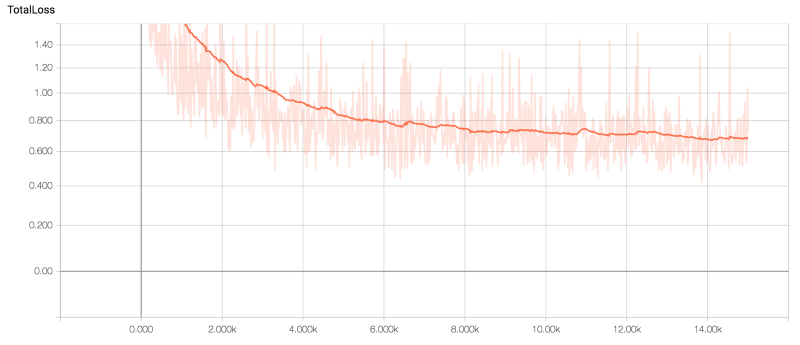
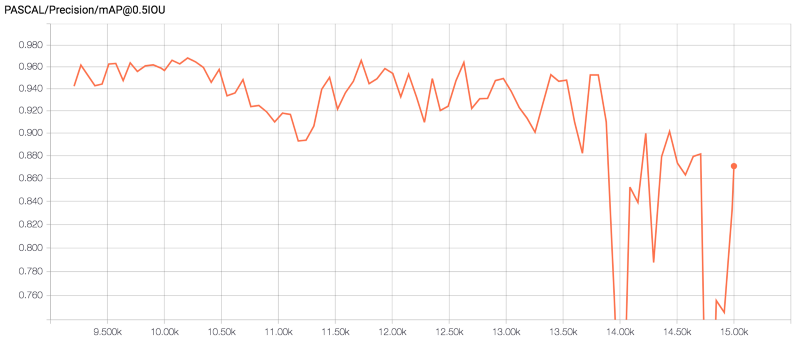
精确度指标
TensorBoard还会自动评估评估集的一些图像。它真正的好处是,通过使用一个滑块(slider),你可以看到预测的置信(confidence)是如何根据模型的检查点的变化而变化的。

更多的皮卡丘。这种检测是在TensorBoard中进行的
图像检测包包括一个notebook,用来测试TensorFlow提供的预先训练过的模型。然而,这个notebook可以被修改为使用自定义训练模型的frozen版本(我们导出的版本),所以我就这样做了。
notebook地址:
https://github.com/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb
下面,你可以看到一些在notebook上的发现。

皮卡丘在锻炼

皮卡丘和lil bro
人类装扮成皮卡丘。没有被检测到
在安卓手机上检测皮卡丘
到目前为止,我们已经对模型进行了训练,并对其进行了评估。现在是时候把它导入安卓手机中了,这样我们就可以用手机摄像头来检测皮卡丘了。然而,这个部分是非常复杂的,所以我会尽可能详细地解释主要步骤。但是,我确信你们中有些人在进行这个操作时会有一些问题,所以如果我的指导不能够帮到你们,我想先道歉。
让我们转到TensorFlow的安卓部分。首先,你需要下载Android Studio。然后,clone上面的提到的TensorFlow的repo,并使用你刚刚clone的TensorFlow的repo中的目录在Android Studio中导入一个的新项目,叫做“Android”。
作为补充说明,我还建议通过README对库进行熟悉。README建议将构建变得最简单,并建议将Gradle(一个基于Apache Ant和Apache Maven概念的项目自动化构建工具)构建的nativeBuildSystem变量改变为零,然而,我将其更改为cmake来构建它(没有任何其他的替代方案)。
构建完成后,下一步是将frozen模型添加到“assets”目录中。然后,在那里的文件夹中,创建一个名为“labels”的文件,在第一行中写入???(还记得我说过第一个类是被预留的吗?),在第二行中,写上你的对象的标签(在我的例子中,我的标签为“Pikachu”)。
然后,打开位于“java”目录中的名为“DetectionActitivity.java”的文件;这是应用程序用来执行探测的代码。查找变量TF_OD_API_MODEL_FILE和TF_OD_API_LABELS_FILE,并且在第一个文件中,将其值更改为位于“assets”文件夹中的frozen模型的路径,然后在第二个文件中写入带有标签的文件路径。你应该知道的另一个有用的变量是MINIMUM_CONFIDENCE_TF_OD_API,它是跟踪检测所需的最低置信。
现在我们准备好了! 点击“run”按钮,选择你的安卓设备,然后等待几秒钟,直到该应用安装在手机上。需要注意的一个重要的细节:不是一个,而是四个应用将安装在手机上,然而,我们所包含的检测模型是TF Detect。如果一切顺利的话,应用启动,找到你的对象的一些图片,看看这个模型是否能够检测到它们。以下是我在手机上做的一些检测:

穿着和服的皮卡丘
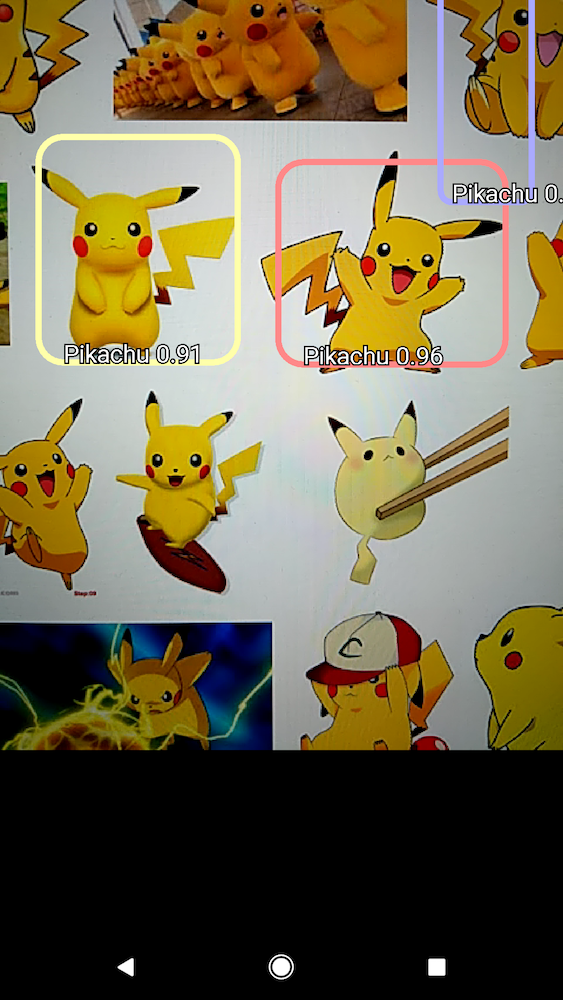
几个皮卡丘。其中大部分没有被检测到
总结和回顾
在本文中,我解释了使用TensorFlow对象检测库来训练自定义模型的所有必要步骤。在开始的时候,我提供了一些关于这个库的背景信息以及它是如何工作的,接下来是关于如何标记、处理和图像来生成数据集的指南。后来,我把注意力集中在如何进行训练上。在这一节中,我谈到了训练管道,如何使用TensorBoard来评估模型。然后,一旦训练完成,我就完成了导出模型并导入Python notebook和安卓手机的过程。




























