


















自动机器学习:利用遗传算法优化递归神经网络
在本文中,我们将学习如何应用遗传算法(GA)来寻找一个最优的窗口大小和一些基于递归神经网络(RNN)的长短期记忆(LSTM)单元。为此,我们将使用Keras来训练和评估时间序列预测问题的模型。对于遗传算法,将使用名为DEAP的python包。本文的主要目的是让读者熟悉遗传算法,以找到最优设置;因此,本文只研究两个参数。此外,本文假定读者对RNN有所认识(理论和应用)。
DEAP地址:https://github.com/DEAP/deap
具有完整代码的ipython netbook可以在以下链接中找到。
代码地址:https://github.com/aqibsaeed/Genetic-Algorithm-RNN
遗传算法
遗传算法是一种启发式搜索,是一种基于自然选择过程的优化方法。它们被广泛应用于在较大的参数空间寻找近似最优解的优化问题。物种进化的过程(例子中的解决方法)是模仿的,依赖于生物启发的部分,例如交叉。此外,由于它不考虑辅助信息(例如导数),它可以用于离散和连续优化。
对于遗传算法,必须满足两个先决条件,a)解决方案表示或定义一个染色体,b)适应度函数来评估产生的解决方案。在我们的例子中,二进制数组是解决方案的遗传表示(参见图1),模型在验证集上的均方根误差(RMSE)将成为一个适应度值。此外,构成遗传算法的三种基本操作如下:
- 选择:它定义了为进一步的复制而保留的解决方案。例如赌轮选择。
- 交叉:它描述了如何从现有的解决方案创建新的解决方案。例如n点交叉。
- 突变:它的目的是通过随机交换或关闭解决方案,将多样性和新奇性引入到解决方案池(solution pool)中。例如二进制突变。
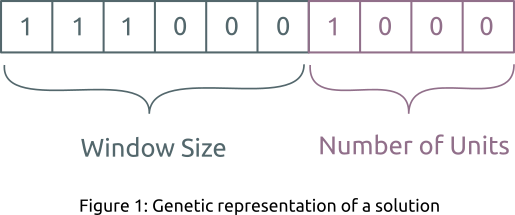
图1
有时,一种被称为“Elitism”的技术也被使用,它只保留少数最好的解决方案,并传递给下一代。图2描述了一个完整的遗传算法,其中,初始解(种群)是随机生成的。接下来,根据适应度函数和选择进行评估,然后进行交叉和变异。这个过程重复定义迭代的次数中重复。最后,选择一个具有最高适应度分数的解决方案作为最佳解决方案。
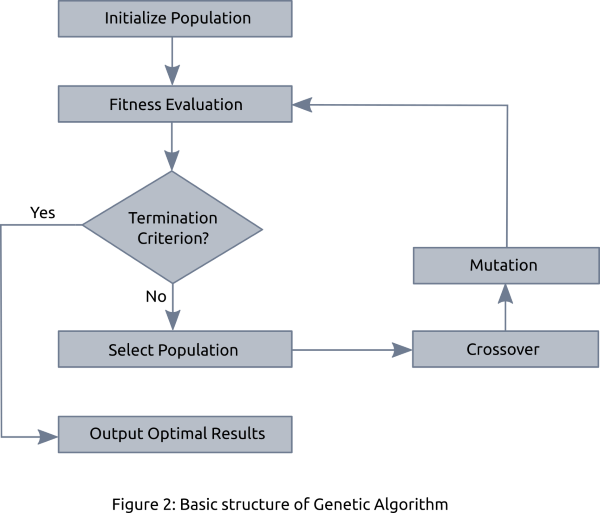
图2
实现
现在,我们对遗传算法是什么以及它如何工作有一个很好的理解。接下来,让我们开始编码。
我们将使用风力发电预测数据。它由7个风力发电场的标准(0-1)风能度量组成。为了简单起见,我们将使用第一个风力发电场(名为wp1),但我鼓励读者尝试并扩展代码,以预测所有7个风力发电场的能源。
风能预测数据地址:https://www.kaggle.com/c/GEF2012-wind-forecasting/data
导入所需的包,加载数据集并定义两个辅助函数。第一个方法prepare_dataset将数据分割成块,为模型训练创建XY对。X是过去(例1到t-1)的风电价值(wind power value),Y将在t时刻为未来值(future value)。第二种方法train_evaluate执行三件事,1)解码遗传算法解决方案以获得窗口大小和单元数。2)使用GA找到的窗口大小来准备数据集,并将其划分为训练和验证集,3)训练LSTM模型,在验证集上计算RMSE,并返回该值将其作为当前遗传算法解决方案的适应度值。
import numpy as np
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split as split
from keras.layers import LSTM, Input, Dense
from keras.models import Model
from deap import base, creator, tools, algorithms
from scipy.stats import bernoulli
from bitstring import BitArray
np.random.seed(1120)
data = pd.read_csv('train.csv')
data = np.reshape(np.array(data['wp1']),(len(data['wp1']),1))
# Use first 17,257 points as training/validation and rest of the 1500 points as test set.
train_data = data[0:17257]
test_data = data[17257:]def prepare_dataset(data, window_size):
X, Y = np.empty((0,window_size)), np.empty((0))
for i in range(len(data)-window_size-1):
X = np.vstack([X,data[i:(i + window_size),0]])
Y = np.append(Y,data[i + window_size,0])
X = np.reshape(X,(len(X),window_size,1))
Y = np.reshape(Y,(len(Y),1))
return X, Y
def train_evaluate(ga_individual_solution):
# Decode GA solution to integer for window_size and num_units
window_size_bits = BitArray(ga_individual_solution[0:6])
num_units_bits = BitArray(ga_individual_solution[6:])
window_size = window_size_bits.uint
num_units = num_units_bits.uint
print('\nWindow Size: ', window_size, ', Num of Units: ', num_units)
# Return fitness score of 100 if window_size or num_unit is zero
if window_size == 0 or num_units == 0:
return 100,
# Segment the train_data based on new window_size; split into train and validation (80/20)
X,Y = prepare_dataset(train_data,window_size)
X_train, X_val, y_train, y_val = split(X, Y, test_size = 0.20, random_state = 1120)
# Train LSTM model and predict on validation set
inputs = Input(shape=(window_size,1))
x = LSTM(num_units, input_shape=(window_size,1))(inputs)
predictions = Dense(1, activation='linear')(x)
model = Model(inputs=inputs, outputs=predictions)
model.compile(optimizer='adam',loss='mean_squared_error')
model.fit(X_train, y_train, epochs=5, batch_size=10,shuffle=True)
y_pred = model.predict(X_val)
# Calculate the RMSE score as fitness score for GA
rmse = np.sqrt(mean_squared_error(y_val, y_pred))
print('Validation RMSE: ', rmse,'\n')
return rmse,
接下来,使用DEAP包来定义运行遗传算法的东西。对于长度为10的解,我们将使用二进制表示。它将使用伯努利分布随机初始化。同样,使用了有序交叉、随机突变和赌轮选择。遗传算法参数值被任意初始化;我建议你在不同的设置下尝试。
population_size = 4
num_generations = 4
gene_length = 10
# As we are trying to minimize the RMSE score, that's why using -1.0.
# In case, when you want to maximize accuracy for instance, use 1.0
creator.create('FitnessMax', base.Fitness, weights = (-1.0,))
creator.create('Individual', list , fitness = creator.FitnessMax)
toolbox = base.Toolbox()
toolbox.register('binary', bernoulli.rvs, 0.5)
toolbox.register('individual', tools.initRepeat, creator.Individual, toolbox.binary,
n = gene_length)
toolbox.register('population', tools.initRepeat, list , toolbox.individual)
toolbox.register('mate', tools.cxOrdered)
toolbox.register('mutate', tools.mutShuffleIndexes, indpb = 0.6)
toolbox.register('select', tools.selRoulette)
toolbox.register('evaluate', train_evaluate)
population = toolbox.population(n = population_size)
r = algorithms.eaSimple(population, toolbox, cxpb = 0.4, mutpb = 0.1,
ngen = num_generations, verbose = False)
通过使用 tools.selBest(population,k = 1),可以很容易地通过遗传算法找到的K最佳解决方案。之后,最优配置可以用来训练完整的训练集,并在holdout测试集上进行测试。
# Print top N solutions - (1st only, for now)
best_individuals = tools.selBest(population,k = 1)
best_window_size = None
best_num_units = None
for bi in best_individuals:
window_size_bits = BitArray(bi[0:6])
num_units_bits = BitArray(bi[6:])
best_window_size = window_size_bits.uint
best_num_units = num_units_bits.uint
print('\nWindow Size: ', best_window_size, ', Num of Units: ', best_num_units)
# Train the model using best configuration on complete training set
#and make predictions on the test set
X_train,y_train = prepare_dataset(train_data,best_window_size)
X_test, y_test = prepare_dataset(test_data,best_window_size)
inputs = Input(shape=(best_window_size,1))
x = LSTM(best_num_units, input_shape=(best_window_size,1))(inputs)
predictions = Dense(1, activation='linear')(x)
model = Model(inputs = inputs, outputs = predictions)
model.compile(optimizer='adam',loss='mean_squared_error')
model.fit(X_train, y_train, epochs=5, batch_size=10,shuffle=True)
y_pred = model.predict(X_test)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print('Test RMSE: ', rmse)
在本文中,我们了解了如何使用遗传算法自动找到最佳窗口大小以及在RNN中使用的一些单元。为了进一步学习,我建议尝试使用不同的遗传算法参数配置,扩展遗传表达式,以包含更多的参数。









