


















应赛技巧,教你如何在Kaggle比赛中排在前1%
最近,我参加了Kaggle比赛。虽然这是我第一次参赛,但我的成绩相当不错。我想和大家分享我的方法和从比赛中学到的东西。

Statoil/C-CORE Iceberg分类器挑战是我选择的题目。在这次比赛中,选手们使用卫星拍摄的雷达图像来对船只和冰山进行分类。inc_angle作为附加信息给出。更多的细节可以在比赛的页面上看到。
Statoil/C-CORE Iceberg分类器挑战地址:https://www.kaggle.com/c/statoil-iceberg-classifier-challenge/
下面是我的方法和总结。
成功的方法
- 堆叠,混合。
- Bagging。
- 手动特征提取。
- 测试基本模型。
- 分集(Diversity)。
- 具有不同架构的多种DNN。
- 输入的不同比例。
- 是否使用扩展。
- 伪标签。
成功的方法,但我并没有使用。
- 有效的漏洞利用(leak utilization)。
时间主要用在:
- 学习堆叠和混合。
- 构建堆叠和混合的源代码。
- 训练多个DNN。
- 在堆叠的第二阶段尝试一些分类器。
我和其他顶级参赛选手之间的主要区别是有效漏洞的利用。这意味着我应该更仔细地研究数据,但我却并没有这样做。虽然这种技术听起来有点棘手,但探索性数据分析技术使它成为可能,并且它是我们最重要的技术之一。
因为这是我的第一个挑战,我花了相当多的时间写代码。我在Github上公开了我的代码。
我的ml项目的初学者工具包。
工具包地址:https://github.com/akirasosa/ml-starter
让我们来看看更多的细节。
成功的方法
在我参加这次比赛之前,我并不太熟悉这些技术,比如堆叠和混合。幸运的是,我在比赛的前收到了Coursera的邮件。这是《如何赢得数据科学竞赛:从顶端开始学习》课程的邀请。这对我有很大的帮助,尤其是Marios第4周的课程,对我非常有帮助。我看了很多遍。
堆叠的最终架构
堆叠的多样性
堆叠的重要意义在于多样性。我使用的基本模型是简单的CNN,有4层。通过使用CNN,我做出了6种预测模式。
- CNN-4L没有强化训练,没有辅助输入。
- CNN-4L没有强化训练,MinMax缩放辅助输入。
- CNN-4L没有强化训练,标准缩放辅助输入。
- CNN-4L经过强化训练,没有辅助输入。
- CNN-4L经过强化训练,MinMax缩放辅助输入。
- CNN-4L经过强化训练,标准缩放辅助输入。
我这里使用的辅助输入来自于下面的内核。
内核地址:https://www.kaggle.com/cttsai/ensembling-gbms-lb-203
在这个内核中,它提取图像的统计信息。我用不同的缩放比例将它们输入到CNN。而且,我从线性缩放图像中提取了更多的统计数据(原始图像是Decibel,所以是对数缩放)。
在验证这些效果之后,我训练了一些更不同的架构。
- CNN-4L
- WRN (Wide Residual Net)
- VGG16
- Inception V3
- MobileNets
- VGG16 + MobileNets
因此,我可以得到36(= 6 * 6)的模型模式。其中一些模式在没有数据强化的情况下不能很好地融合,所以我最后从36个模式里选择了24个。
基本模型
我意识到在早期找到一个基本模型是很重要的。CNN 4L是这个案例的基础模型。
基本模型必须在短时间内进行训练。通过使用基本模型,我可以对几种实验进行检验,如伪标记、线性缩放图像、强化、辅助输入等。
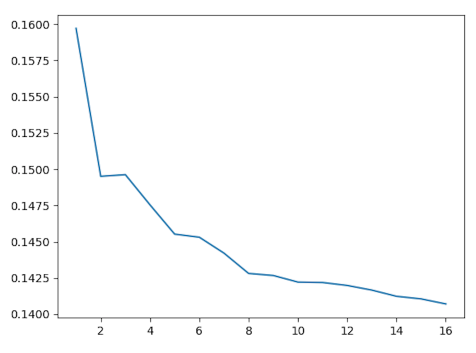
Bagging
结果表明,bagging对DNN模型的泛化能力是相当有效的。这是其中一个模型Bagging的结果。
Bag的数量和对数损失
虽然我确信更多的bagging会带来更多的收益,但是我没有足够的计算资源。
堆叠的第二阶段
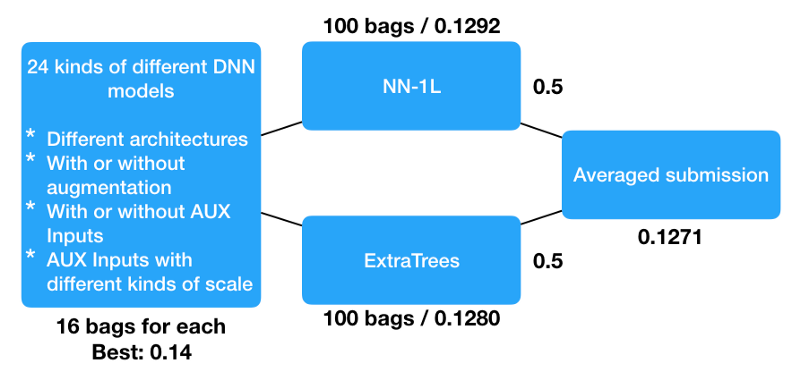
当我在第一阶段成功地获得了24种预测模式时,我尝试在第二阶段将它们输入到几个分类器中。我最后选择了两个分类器。
- NN-1L (100 bags)
- ExtraTreesClassifier (100 bags)
NN-1L在公共/私人排行榜上的对数损失分别为0.1321 / 0.1292。ExtraTreesClassifier的对数损失为0.1316 / 0.1280。由于小数据的原因,公共排行榜看起来不那么可靠。
我只是用相同的权值0.5和0.5来求均值。该平均提交的最终对数损失为0.1306 / 0.1271。
我尝试了一些基于梯度树的分类器,比如XGBoost和LightGBM。他们非常适合训练数据。虽然他们在计算机视觉上的表现很好,但在公共LB上却不是很好,我猜可能是用错误的方法解读了inc_angle的漏洞。
没有采用的成功的方法
现在,让我们来看看其他顶级的选手的方法。他们的解决方案给我留下了深刻的印象。
解决方案地址:https://www.kaggle.com/c/statoil-iceberg-classifier-challenge/discussion/48207
正如你所看到的,他开始的步骤和我的差不多。但是他不使用inc_angle来训练模型。而是选择了另一种方法,用inc_angle来计算另一种预测。因此,他得到了两种独立的概率。
然后,他将它们按照公式混合。
p = p1 * p2 / (p1 * p2 + (1 - p1) * (1 - p2))
第一名的解决方案概况
解决方案地址:https://www.kaggle.com/c/statoil-iceberg-classifier-challenge/discussion/48241
这些方法在顶级选手中很常见,他们会仔细查看数据。第一名的解决方案的可视化是非常清晰的。
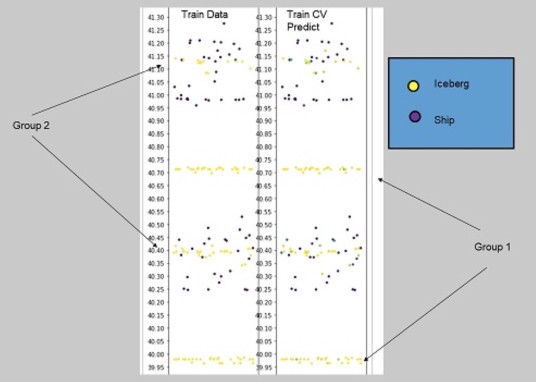
第一名的解决方案:可视化漏洞
>>为什么在group2训练样本中重新训练100+模型而不使用group1或两者?
>因为我们认为这些group2的样本分布与group1不同。对group2的训练只会消除group1所导致的“偏差”,group1中的数据全部是冰山,从而提高了group2预测的准确性,即使是在较少图像(约400次)的低成本中也能提高精度。
解决方案地址:https://www.kaggle.com/c/statoil-iceberg-classifier-challenge/discussion/48294
他调整CV,以防止他的模型利用inc_angle漏洞。
我希望进一步探索的:
- 探索性数据分析。
- 概率方法。
- 一些无监督技术。









