











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






2018年嵌入式处理器报告:神经网络加速器的崛起
2018年02月02日 由 yining 发表
152856
0

人工智能和机器学习应用程序代表了嵌入式处理器的下一个重大市场机遇。然而,传统的处理解决方案并不是为了计算神经网络的工作负载,这些工作负载为许多应用程序提供了动力,因此需要新的架构来满足我们对智能日益增长的需求。
随着数十亿联网传感器节点被部署到物联网领域,有一件事已经变得清晰起来:自动化无处不在。考虑到物联网系统的本质,其中许多具有严重的经济、生产力和安全影响,这一需求超越了简单规则引擎或编程阈值的使用。作为回应,行业转向了人工智能和机器学习。
如今的人工智能和机器学习应用程序依赖于人工神经网络。人工神经网络是一种算法,通过将其定义特征组织成一系列结构层来分析数据集的不同方面。这些网络最初是建立在高性能计算平台上的,这些平台教算法根据特定的参数做出决策或预测。然后,该算法可以进行优化,并将其移植到一个嵌入式目标中,在此基础上,根据该字段中接收到的输入数据进行推断。
使用不同的嵌入式处理解决方案来执行基于应用程序的神经网络算法,为人工智能和机器学习开发人员提供了多种选择。但是,正如著名研究机构The Linley Group的高级分析师麦克·戴姆勒所指出的那样,每一种处理器都在性能和成本方面有所权衡。
戴姆勒说:“没有一种嵌入式的人工智能处理器。神经网络引擎可能会使用CPU, DSP, GPU或专门的深度学习加速器,或者是它们的一种组合。”
“这一趋势无疑是向CPU, GPU和DSP添加加速器。原因是它们比其他的通用核心(core)有更大的面积和效率。像Caffe和TensorFlow这样的开放深度学习框架增加了使用标准,以及像GoogleNet和ResNet这样的开放源码网络,IP供应商更容易设计出具有专门用于运行各种神经网络层的硬件。这就是为什么很多加速器都在不断地添加越来越大的乘积累加器阵列,因为在神经网络中,大多数的计算都是乘积累加计算(MAC)。”
人工智能工作负载的新兴架构
IP供应商针对神经网络工作负载的一个主要关注点是“灵活性”,因为在不断发展地人工智能市场中,需求正在迅速变化。在CEVA最近发布的NeuPro AI处理器架构中可以找到这样的例子,它由一个完全可编程的向量排列单元(VPU)和专门的用于矩阵乘法和计算激活(activation)、池化(pooling)、卷积(convolutional)和完全连接的神经网络层(图1)的特殊引擎组成。
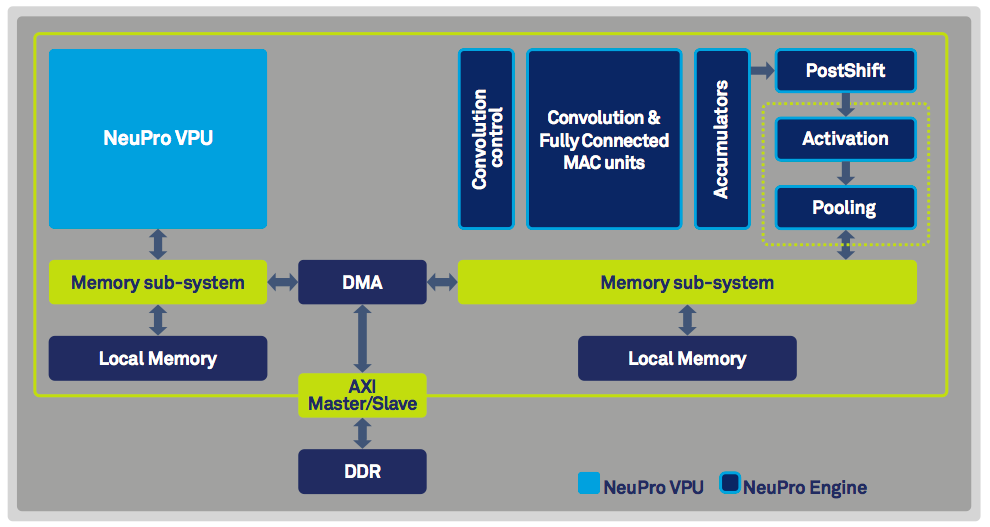
图1:CEVA的NeuPro架构支持高达4000 8x8的MAC,超过了90%的MAC利用率。
处理神经网络工作负载的一个常见挑战是需要将大数据集转移到内存中。为了克服这一点,NeuPro架构结合直接内存访问(DMA)控制器,从而提高了双倍数据速率(DDR)的带宽利用率。
架构的一个更有趣的特性是能够动态地扩展分辨率以适应各个网络层的精度要求。根据CEVA的成像和计算机视觉产品营销主管丽兰·巴尔的说法,这有助于最大程度地提高神经网络的准确性。
“并不是所有的层都需要同样的精度。事实上,许多商业化的神经网络需要16位的分辨率来保持较高的精确度,但同时,8位的分辨率对于某些层来说已经足够了。NeuPro预先决定了每8位个或16位分辨率的层的精度,以实现完整的灵活性。例如,在使用NP4000产品时,可以在运行时动态选择4000 8x8、2048 16x8或1024 16x16的MAC。”
类似的功能也可以使用Imagination Technologies发布的PowerVR Series2NX,这是一种神经网络加速器(NNA),它的原生支持可以将位深(bit depth)降低到4位。然而,PowerVR Series2NX将动态扩展到极致,在相同的核心支持4、5、6、7、8、10、12和16位的分辨率,从而实现更好的精度(图2)。
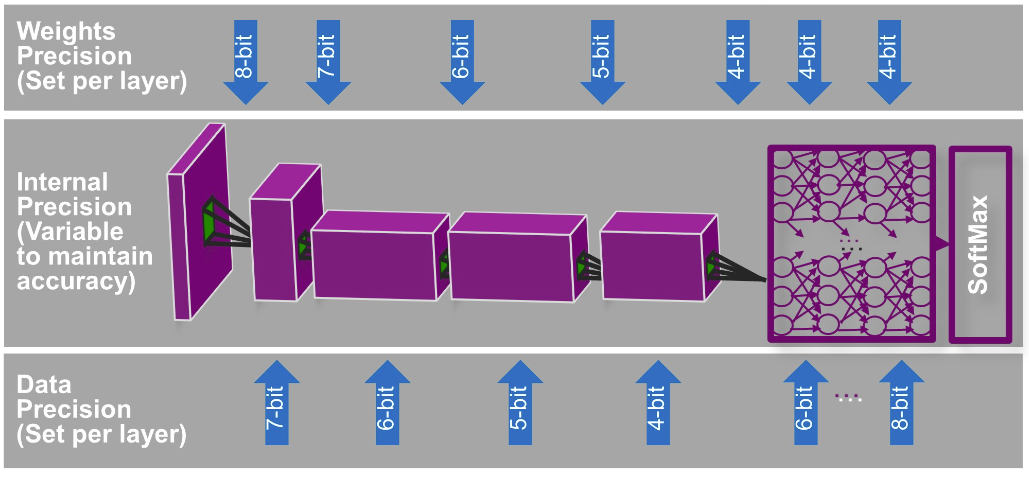
图2:PowerVR Series2NX是一种神经网络加速器(NNA),它可以运行现成的网络,如GoogLeNet Inception,每秒钟可以进行500次的推断(inference)。
“我们可以把NNA架构看作是一个张量处理管道,”Imagination Technologies的视觉和人工智能副总裁罗素·詹姆斯说道。“它有一个神经网络计算引擎,优化了对大张量(输入数据和权重)的快速卷积,并由其他单元执行元素和张量操作,如激活、池化和规格化。该体系结构还使用了优化的数据流,使操作可以被分组到传递中,从而最小化外部内存访问。”
PowerVR Series2NX的另一个独特功能是它能够将数据转换为内存中的交换格式,可以由CPU或GPU读取,这使得异构系统在神经网络处理中处于领先地位。Imagination提供了一个网络开发工具包(NDK)来评估核心,它包含了将神经网络映射到NNA的工具,优化网络模型,以及转换在诸如Caffe和TensorFlow等框架中开发的网络。
除了IP供应商之外,主要芯片制造商还在继续利用人工智能的工作负载。NVIDIA Tegra和Xavier SoCs将CPU、GPU和自定义深度学习加速器结合在了自动驾驶系统上,而高通则继续在其六边形DSP中构建机器学习特性。甚至Google也创建了一个TPU。
这些公司都采用不同的方法处理神经网络工作负载,每种架构处理的用例略有不同。但是,对于开发者来说,越多的选择,当然就越好。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消