











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






“极简主义机器学习”算法可从极小数据中分析图像
2018年02月22日 由 nanan 发表
849569
0
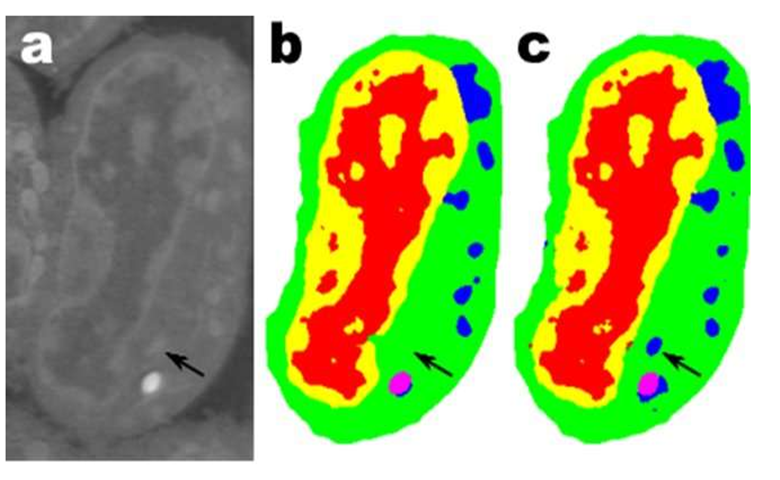
一片小鼠淋巴细胞样的图像: a是原始数据,b是相应的手动分段,c是具有100层的MS-D网络的输出。
美国能源部劳伦斯伯克利国家实验室(伯克利实验室)的数学家们开发了一种新的机器学习方法,旨在实验成像数据。这种新方法不是依靠典型机器学习方法所使用的数十或数十万个图像,而是“更快地学习”,并且极少所需的图像。
伯克利实验室能源研究应用高级数学中心(CAMERA)的DaniëlPelt和James Sethian通过开发他们称之为“混合尺度密集卷积神经网络(MS-D)”的方法,将平常的机器学习视角转变为头脑,比传统方法少得多的参数,快速收敛,并且能够从一个非常小的训练集“学习”。他们的方法已被用于从细胞中提取生物结构图像,并将提供一个重要的新计算工具来分析广泛的研究领域的数据。
当实验设施以更高的速度生成更高分辨率的图像时,科学家们就很难对得到的数据进行管理和分析,而这些数据通常是手工完成的。2014年,Sethian在伯克利实验室建立了CAMERA,作为一个综合性的跨学科中心,开发和提供基本的新数学,以利用美国能源部科学办公室的用户设施的实验调查。CAMERA是实验室计算研究部门的一部分。
“在许多科学应用中,需要大量的体力劳动来注释和标记图像——需要几周的时间才能制作出几个精心描绘的图像,”Sethian说,他也是加州大学伯克利分校的数学教授。“我们的目标是开发一种从非常小的数据集学习的技术。”
该算法的信息于2017年12月26日在《美国国家科学院院刊》上发表。
“这一突破源自于认识到在不同图像尺度下通常的缩放和放大拍摄功能可以被处理多个尺度的数学卷积所取代,”Pelt说,他也是Centrum计算成像组的成员。Wiskunde&Informatica,荷兰数学和计算机科学国家研究机构。
为了使该算法能够被广泛的研究人员所接受,由Olivia Jain和Simon Mo领导的伯克利团队建立了一个门户网站“分段标记图像数据引擎(SlideCAM)”,作为美国能源部实验设施的CAMERA工具套件的一部分。
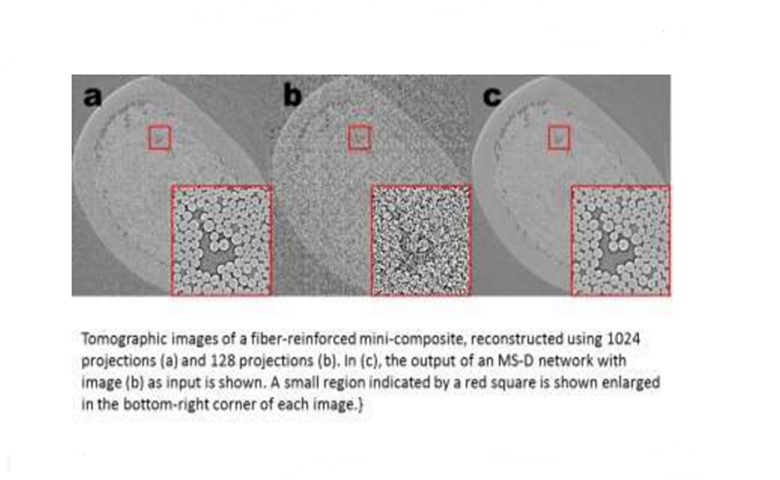
使用1024个投影(a)和120个投影(b)重建的纤维增强微型复合材料的断层图像。在(c)中,显示了具有图像(b)作为输入的MS-D网络的输出。在每幅图像的右下角放大显示由红色方块指示的小区域。
一个有前途的应用是理解生物细胞的内部结构,以及Pelt和Sethian的MS-D方法只需要来自7个细胞的数据来确定细胞结构的项目。
“在我们的实验室,我们正在研究细胞结构和形态如何影响或控制细胞的行为。”美国国家x射线断层扫描中心主任、加州大学旧金山分校医学院的教授Carolyn Larabell说:“我们花了大量的时间来手工分割细胞,以提取结构,并识别出健康与患病细胞之间的差异。”“这种新方法有可能从根本上改变我们理解疾病的能力,并且是我们新的Chan-Zuckerberg赞助的建立Human Cell Atlas项目的关键工具,该项目是一项全球合作项目,用于绘制健康人体中所有细胞身体。”
从更少的数据中获取更多的科学
图像无处不在。智能手机和传感器已经产生了一批珍贵的图片,其中很多都带有相关的信息。使用这个交叉参考图像的庞大数据库,卷积神经网络和其他机器学习方法已经彻底改变了我们快速识别那些看起来像之前看到和被分类的自然图像的能力。
这些方法通过调整一组惊人的隐藏内部参数来“学习”,这些隐藏的内部参数由数以百万计的被标记的图像引导,并且需要大量的超级计算机时间。但是如果你没有那么多的标记图像呢?在许多领域,这样的数据库是无法实现的奢侈品。生物学家记录下了细胞的图像,并煞费苦心地用手勾勒出边界和结构:一个人花数周时间想出一个完全三维的图像是很正常的。材料科学家利用断层重建技术来观察岩石和材料,然后卷起他们的袖子来标记不同的区域,用手识别裂缝和空隙。不同但重要的结构之间的对比往往非常小,数据中的“噪音”可以掩盖特征,混淆了最佳算法。
这些珍贵的手工制作的图像在传统的机器学习方法中还远远不够。为了迎接这一挑战,CAMERA的数学家们从非常有限的数据中攻克了机器学习的问题。他们试图用更少的方法做“更多”,他们的目标是找出如何建立一套高效的数学“运算符”,这样可以大大减少参数的数量。这些数学运算符可能会自然地结合关键约束来帮助识别,例如,包括对科学合理形状和模式的要求。
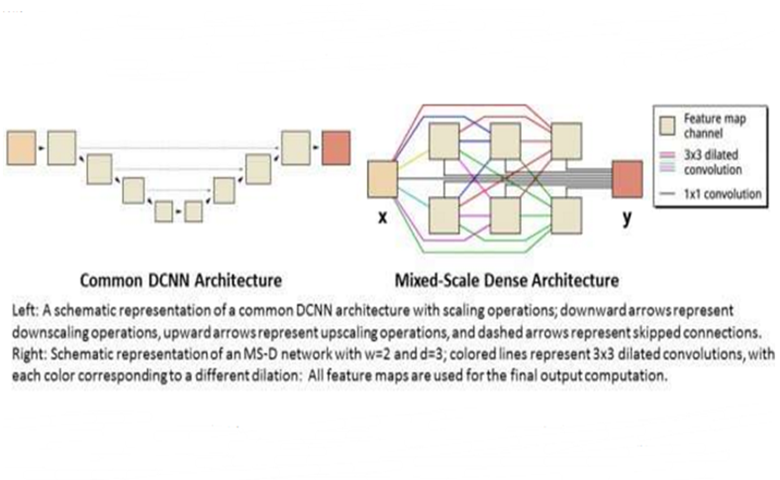
左图:具有缩放操作的常见DCNN体系结构的示意图; 向下箭头表示缩小操作,向上箭头表示放大操作,而虚线箭头表示跳过连接。右图:w = 2和d = 3的MS-D网络的示意图; 彩色线代表3x3扩张卷积,每种颜色对应不同的膨胀:所有特征图用于最终输出计算。
混合尺度密集卷积神经网络
机器学习在成像问题上的许多应用都使用深度卷积神经网络(DCNN),其中输入图像和中间图像在大量的连续层中进行卷积,使得网络能够学习高度非线性的特征。为了在困难的图像处理问题上获得准确的结果,DCNN通常依赖于额外的操作和连接的组合,例如,缩小和放大操作以捕获各种图像尺度的特征。为了训练更深层和更强大的网络,通常需要额外的图层类型和连接。最后,DCNN通常使用大量的中间图像和可训练的参数(通常超过1亿),以达到解决难题的结果。
取而代之的是,新的“混合比例密集”网络结构避免了许多这样的复杂性,并将扩张的卷积计算为缩放操作的替代,以捕获各种空间范围的特征,在单个层中使用多个尺度,并将所有中间图像紧密地连接起来。新的算法获得精确的结果,中间的图像和参数很少,同时消除了需要调整超参数和附加的图层或连接以支持训练。
从低分辨率数据获取高分辨率科学
另一个挑战是从低分辨率输入产生高分辨率图像。任何试图放大一张小照片的人都会发现,随着它越来越大,它变得越来越糟,这听起来几乎是不可能的。但是用混合密度密集网络处理的一小部分训练图像可以提供真正的进展。举个例子,想象一下,试着去对纤维增强的微型复合材料的层析重建。在本文描述的实验中,使用1024个获得的X射线投影来重建图像以获得具有相对低噪声量的图像。然后通过使用128个投影重建来获得同一对象的噪声图像。训练输入是嘈杂的图像,相应的无噪声图像用作训练期间的目标输出。经过训练的网络能够有效地获取噪声输入数据并重构更高分辨率的图像。
新应用程序
Pelt和Sethian正在将他们的方法应用到许多新领域,例如快速实时分析来自同步加速器光源的图像以及生物重建中的重建问题,例如细胞和脑图。
Pelt说:“这些新方法非常令人兴奋,因为它们将使机器学习的应用范围变得比目前可能出现的多种成像问题多得多,”“通过减少所需训练图像的数量,增加可以处理的图像的大小,新的体系结构可以用来回答许多研究领域的重要问题。”

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消