











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






百度语音系统Deep Voice新突破 可在几秒内克隆你的声音
2018年02月23日 由 yining 发表
863746
0

百度的AI研究部门近日宣布,其文本到语音(TTS)系统“Deep Voice”已经学会了如何使用仅三秒钟的语音样本数据来模仿人类的声音。
这项技术被称为“语音克隆”,可以用来个性化虚拟助手,比如苹果的Siri、Google Assistant、Amazon Alexa;百度的DuerOS(对话式人工智能系统,在中国支持5000万部设备)。
在医疗保健领域,语音克隆技术帮助那些失去了声音的病人建立了一个复制品。在娱乐产业和社交媒体上,语音克隆甚至可能起到意想不到的作用。
百度研究人员实现了两种方法:说话者自适应(speaker adaption)和说话者编码(speaker encoding)。它们都能以最小的音频输入数据来实现良好的性能,并能在深度语音系统中集成到一个多扬声器生成模型中,而无需降低质量。
说话者自适应是基于多扬声器生成模型或仅适用于低维度的扬声器嵌入的基于反向传播的方法。与此同时,扬声器编码将多扬声器生成模型与另一个独立的模型结合在一起,生成一个从克隆音频中嵌入的新扬声器。这种方法缩短了克隆时间,只需要几秒钟,并且需要少量的参数来表示每个说话者,这使它有利于低资源部署。
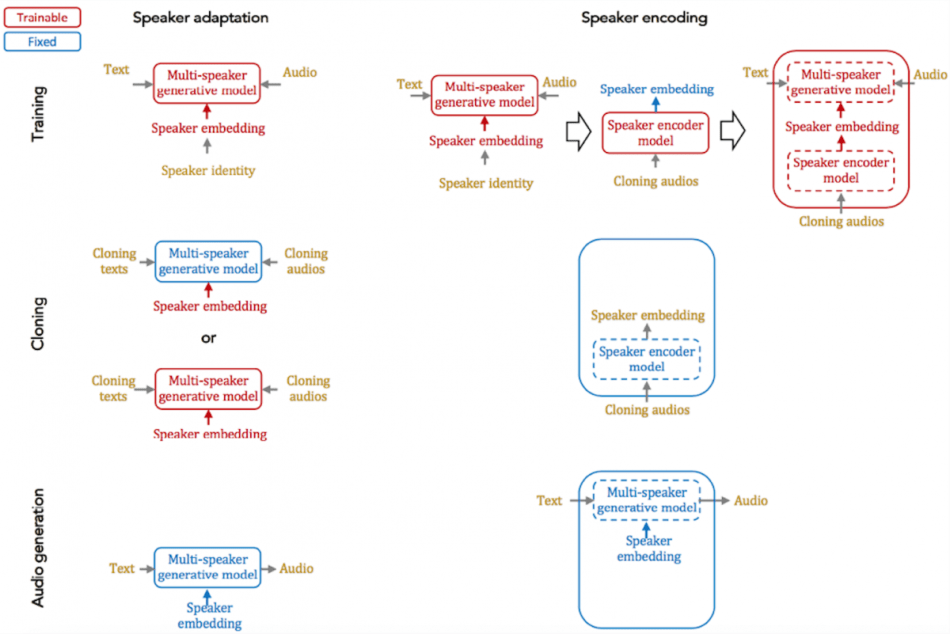
为训练、克隆和音频生成提供扬声器的适应和扬声器编码方法。由百度研究。
百度发布了多段三秒的克隆音频片段,追踪从原始声音到合成声音的过程,这些声音惊人地相似。
百度对语音克隆研究领域的可能性表示乐观。例如,元学习的进展,这是一种学习到学习(learn-to-learn)的系统方法,可以显著提高语音克隆的质量。
但是,百度并不是唯一一个利用人工智能模仿人类声音的机构。谷歌旗下的DeepMind在2016年推出了其TTS项目WaveNet,该系统模拟了来自真人声音的音频波形,并产生了令人信服的自然模拟。此外,Adobe还推出了一款名为Project VoCo的原型软件,该软件可以在20分钟内学会模仿声音。去年,蒙特利尔的创业公司Lyrebird将语音克隆技术推向了一个新的水平,该系统只需要一个60秒的音频样本输入,就能实现“一个听起来像你的声音的数字语音”。
最近,合成人类声音领域的突破也引起了人们的关注。人工智能可能会在现实生活或安全系统中降低语音识别的功能。例如,语音技术可以通过在他们的声音中制造虚假陈述来恶意地攻击公众人物。BBC记者与他的孪生兄弟进行的测试也证明了模仿语音系统的声音的能力。
百度的Deep Voice减少了训练时间,提高了语音克隆的发展,而且在医疗解决方案和其他领域的应用也取得了进展。
- 关于这项技术的详细内容请看:https://arxiv.org/pdf/1802.06006.pdf

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消