











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌开源视觉模型MobileNets,在移动设备上高效运行
2017年06月15日 由 Neo 发表
734964
0
谷歌于美国时间6月14日发布了MobileNets。MobileNets是一系列为移动设备设计、用在TensorFlow中的计算机视觉模型,它们的设计目标是在手持或者嵌入式设备有限的资源下高效地运行,提供尽可能高的准确率。MobileNets中的一系列模型都是小型、低延迟、低耗能的模型,它们为多种不同使用场景下的有限资源做了针对性的参数优化。开发者可以像用Inception这样的大型热门模型一样地用MobileNets中的模型进一步开发分类、识别、嵌入和细分功能。
移动和嵌入式设备视觉应用的高效卷积神经网络模型:MobileNets
论文地址:https://arxiv.org/abs/1704.04861
通过构建新的网络模型MobileNets,得到针对嵌入式系统的轻量级,低时延的神经网络模型。
对标准卷积层进行因式分解:factorized convolution
分解过程:将普通卷积层分解为:
极大减少计算量和模型大小。
备注:默认计算复杂度与输入、卷积核大小有关。
对比:
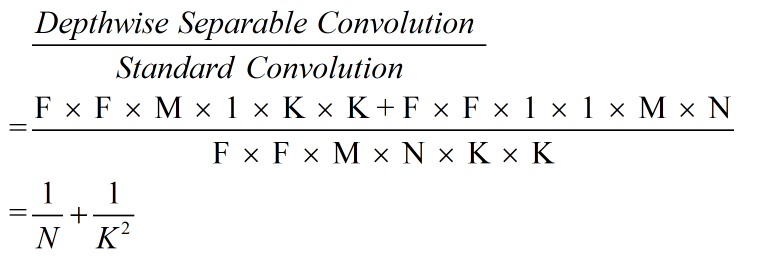
MobileNets使用3x3的深度可分离卷积比标准的卷积减少了8-9倍的计算复杂度。
(三)卷积结构的区别
引入参数使MobileNets占用空间更小、计算速度更快。
数据集:ImageNet
将MobileNets作为目标检测网络Faster R-CNN和SSD的基础网络,和其他模型在COCO数据集上进行了对比。
移动和嵌入式设备视觉应用的高效卷积神经网络模型:MobileNets
论文地址:https://arxiv.org/abs/1704.04861
引入
通过构建新的网络模型MobileNets,得到针对嵌入式系统的轻量级,低时延的神经网络模型。
整体压缩过程
- 运用了depthwise separable convolutions结构(包含两个卷积层),
降低计算量,减少模型参数。 - 在MobileNets网络结构中,引入两个全局超参数,在模型大小、计算速度与精度之间进行权衡。
网络结构
一. Depthwise Separable Convolution
(一)分解过程
对标准卷积层进行因式分解:factorized convolution
分解过程:将普通卷积层分解为:
- 深度卷积 Depthwise Convolutional Filters:将单个滤波器应用到每一个通道;
- 1 x 1卷积 Pointwise Convolution:用1x1卷积来组合通道卷积的输出。
(二)分解后组合
- 第一步:运用Depthwise Convolutional Filters;
- 第二步:运用Pointwise Convolution Filters。
(三)作用
极大减少计算量和模型大小。
(四)举例
- Standard Convolution 标准卷积
- 输入: F x F x M 特征图 (11 x 11 x 9)
- 卷积核:K x K x M x N (3 x 3 x 9 x 3)
padding: 1,stride: 1
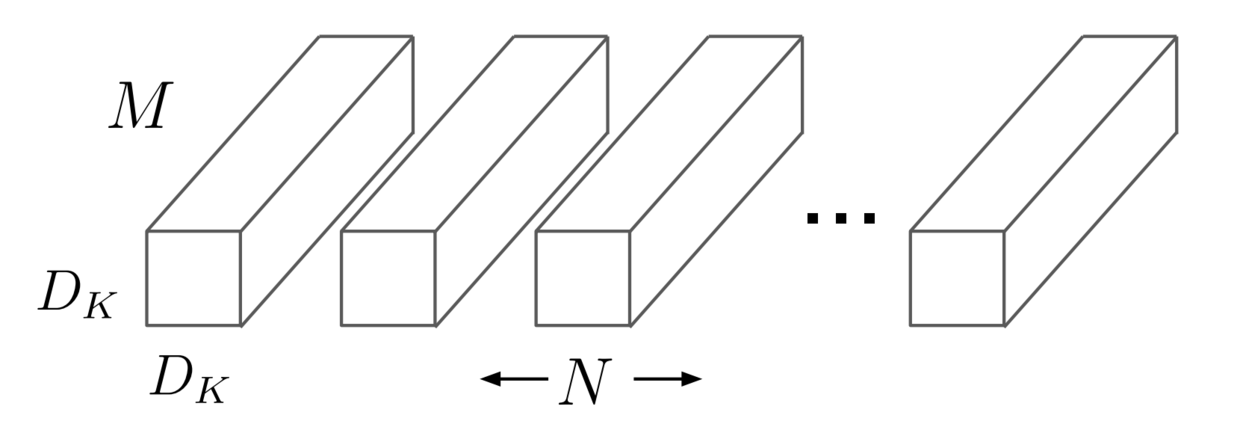
img1: Standard Convolution Filters
- 输出特征层: G x G x N (11 x 11 x 3)
- Depthwise Separable Convolution
- 输入: F x F x M 特征图 (11 x 11 x 9)
- a. Depthwise Convolutional Filters:K x K x 1 x M(3 x 3 x 1 x 9)
padding: 1,stride: 1
得到输出:11 x 11 x 9 x 1
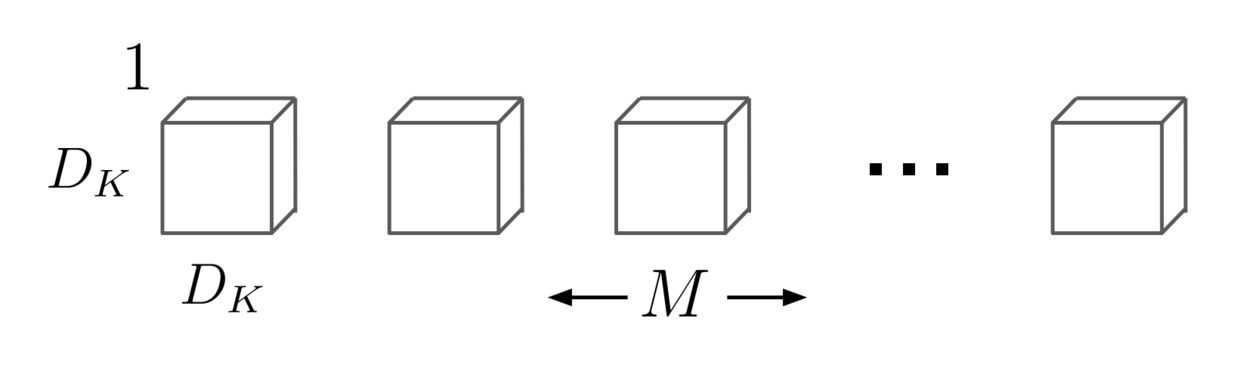
img2: Depthwise Convolutional Filters
- b. Pointwise Convolution Filters:1 x 1 x M x N(1 x 1 x 9 x 3)
padding: 0,stride: 1
得到输出:11 x 11 x 3
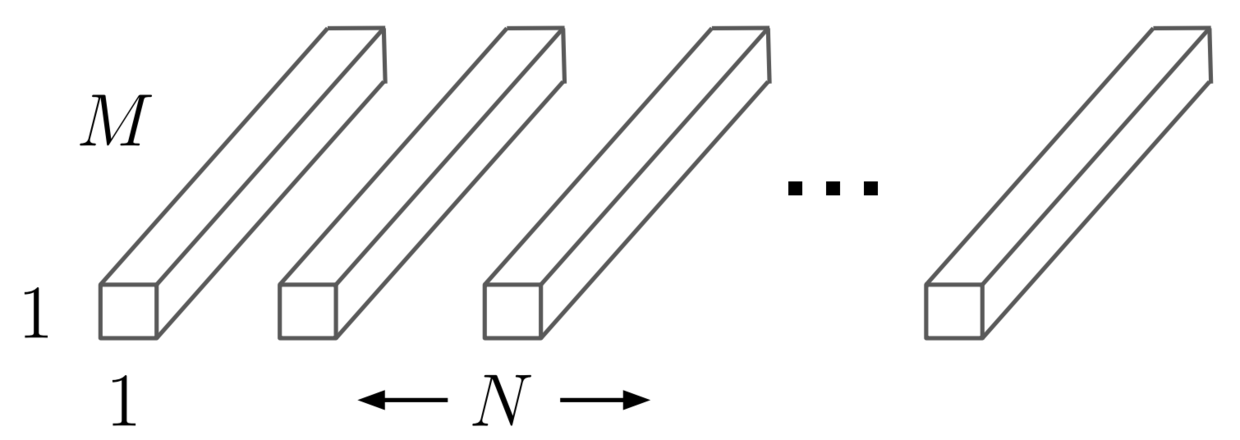
img3: Pointwise Convolution
- a. Depthwise Convolutional Filters:K x K x 1 x M(3 x 3 x 1 x 9)
- 最终输出: G x G x N (11 x 11 x 3)
- 输入: F x F x M 特征图 (11 x 11 x 9)
二. 标准卷积与 Depthwise Separable Convolution区别
(一) 卷积操作过程区别
- Standard Convolution:在一个步骤中,进行全部通道的卷积和组合,得到一组新的输出;
- Depthwise Separable Convolution:Depthwise Convolutional 进行单通道卷积,Pointwise Convolution 进行组合。
(二)计算复杂度的区别
备注:默认计算复杂度与输入、卷积核大小有关。
- Standard Convolution:F x Fx M x N x K x K
- Depthwise Separable Convolution:
F x F x M x 1 x K x K + F x F x 1 x 1 x M x N
对比:
img4: 计算量对比图
MobileNets使用3x3的深度可分离卷积比标准的卷积减少了8-9倍的计算复杂度。
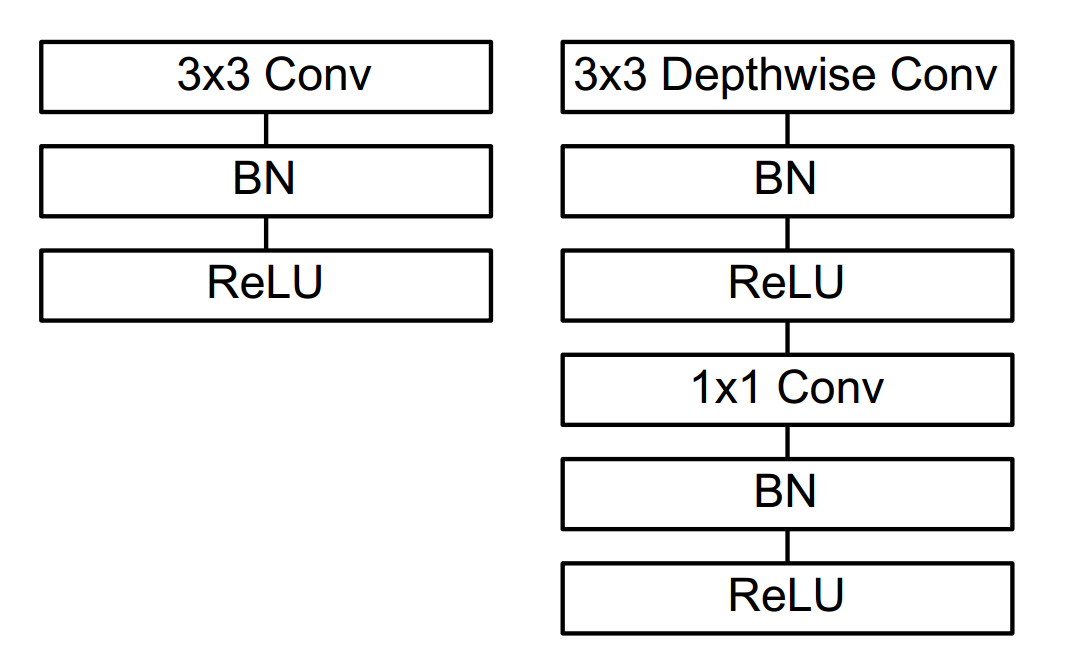
(三)卷积结构的区别
img5: 左为 Standard Convolution操作,右为Depthwise Separable Convolution操作
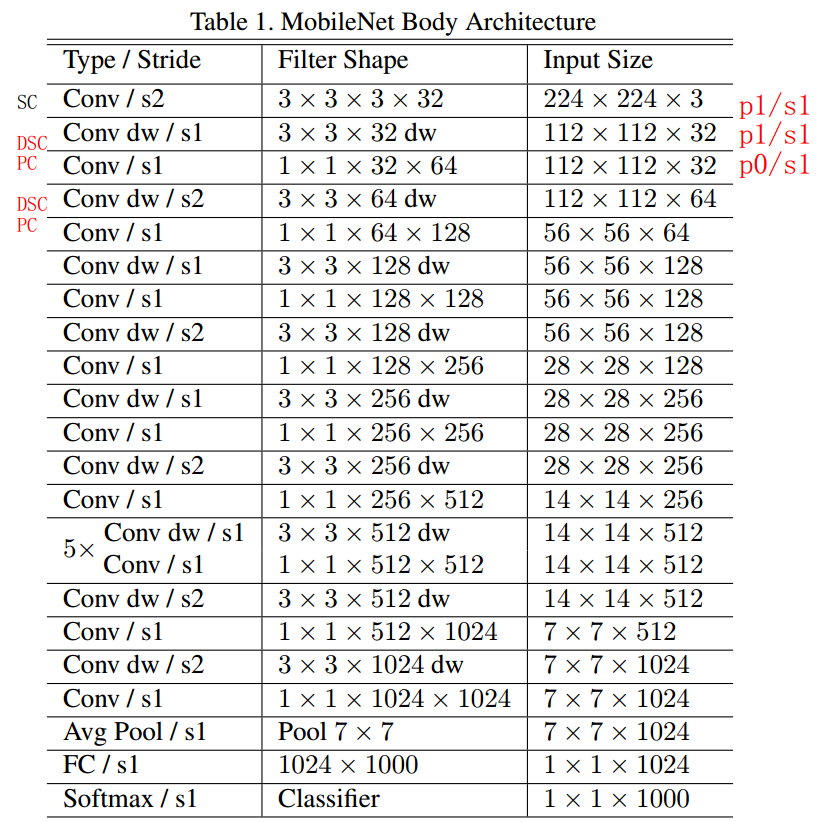
三. MobileNets网络结构
(一)MobileNets网络结构
img6:网络结构
- SC: Standard Convolution;
- DSC: Depthwise Convolutional;
- PC: Pointwise Convolution。
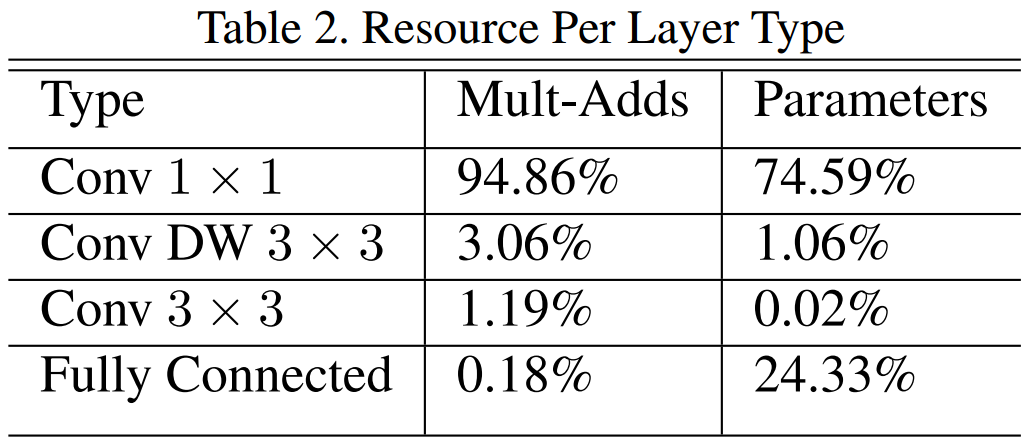
(二)结构分部
img7:每种结构的分布
(三)其他
- 异步梯度下降方法:RMSprop;
- 较少地使用正则化和数据增强技术(因为小模型不容易过拟合);
- 对于Depthwise Convolutional filters, 设置少量或者无weight decay(因为参数很少)。
四. 通过超参数调整MobileNets
引入参数使MobileNets占用空间更小、计算速度更快。
(一)Thinner MobileNets
- 名称:width multiplier
- 字母表示:α
- 作用:
每层均匀地减少网络宽度(对于给定的层和α)。
- 减少参数数量(网络参数大概减少 α x α):
- 输入通道的数量:从M变成αM;
- 输出通道的数量:从N变成αN。
- 减少计算复杂度(Depthwise Separable Convolution):
F x F x αM x 1 x K x K + F x F x 1 x 1 x αM x αN
- 减少参数数量(网络参数大概减少 α x α):
- 范围:
α∈(0,1],通常设为0.25,0.5,0.75,1.0。
- α=1 表示基准MobileNet;
- α<1 表示Thinner MobileNets。
(二)Reduced Computation MobileNets
- 名称:resolution multiplier;
- 字母表示:ρ
- 作用:
降低输入图像的分辨率。
- 减少参数数量;
- 减少计算复杂度(计算开销大概减少 ρ x ρ):
ρF x ρF x M x 1 x K x K + ρF x ρF x 1 x 1 x M x N
- 范围:
ρ∈(0,1],通常设置为 4/7,5/7,6/7,1(论文中,将网络的对应输入分辨率控制为:128,160,192,224);
- ρ = 1 表示基准MobileNets;
- ρ < 1 表示减少计算量的MobileNets。
(三)适用性
- 引入参数α与ρ,在网络的精度,速度和大小进行折中;
- 定义简化结构的MobileNets,可应用于任何模型结构;
- 需要重新训练网络。
实验
一. 目标识别
数据集:ImageNet
(一)将MobileNets与VGG、GoogleNet对比。
img8: 对比表格1.png
- 基准MobileNets 比 GoogleNet 精度略高的情况下, 小了1.6倍,快了2.7倍。
- 基准MobileNets 比 VGG16 精度少1%左右的情况下, 小了32倍,快了27倍。
(二)将Smaller MobileNets与Squeezenet、AlexNet对比
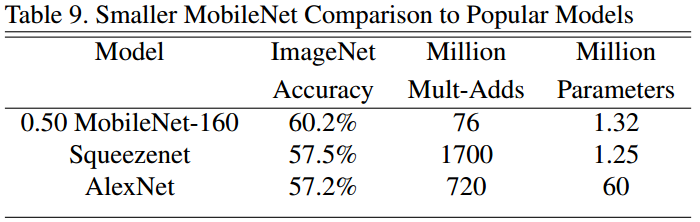
img9:对比表格2
- Smaller MobileNets 比 Squeezenet、AlexNet的精度高了3%;
- Smaller MobileNets 与 Squeezenet 大小相似,快了22倍;
- Smaller MobileNets 比 AlexNet 小了45倍,快了9.4倍。
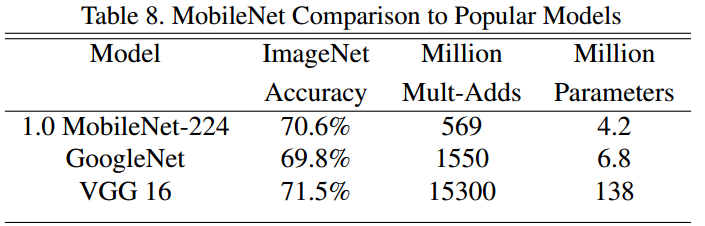
二. 目标检测
将MobileNets作为目标检测网络Faster R-CNN和SSD的基础网络,和其他模型在COCO数据集上进行了对比。
img10:对比表格3

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消