


















LSTM神经网络介绍,附情感分析应用

长短期记忆网络,通常称为“LSTM”(Long Short Term Memory network,由Schmidhuber和Hochreiterfa提出)。LSTM已经被广泛用于语音识别,语言建模,情感分析和文本预测。在深入研究LSTM之前,我们首先应该了解LSTM的要求,它可以用实际使用递归神经网络(RNN)的缺点来解释。所以,我们要从RNN讲起。
递归神经网络(RNN)
对于人类来说,当我们看电影时,我们在理解任何事件时不会每次都要从头开始思考。我们依靠电影中最近的经历并向他们学习。但是,传统的神经网络无法从之前的事件中学习,因为信息不会从一个时间步传递到另一个时间步。而RNN从前一步学习信息。
例如,电影中如果有某人在篮球场上的场景。我们将在未来的框架中即兴创造篮球运动:一个跑或者跳的人的形象可能被贴上“打篮球”的标签,而一个坐着看的人的形象可能被打上“观众”的标签。

一个经典的RNN
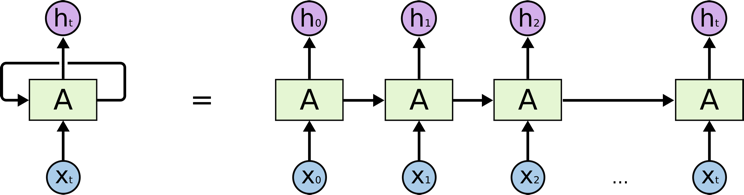
一个典型的RNN如上图所示 - 其中X(t)代表输入,h(t)是输出,而A代表从循环中的前一步获得信息的神经网络。一个单元的输出进入下一个单元并且传递信息。
但是,有时我们并不需要我们的网络仅仅通过过去的信息来学习。假设我们想要预测文中的空白字“大卫,一个36岁,住在旧金山的老男人。他有一个女性朋友玛丽亚。玛丽亚在纽约一家著名的餐厅当厨师,最近他在学校的校友会上碰面。玛丽亚告诉他,她总是对_________充满热情。”在这里,我们希望我们的网络从依赖“厨师”中学习以预测空白词为“烹饪”。我们想要预测的东西和我们想要它去得到预测的位置之间的间隙,被称为长期依赖。我们假设,任何大于三个单词的东西都属于长期依赖。可惜,RNN在这种情况下无法发挥作用。
为什么RNN在这里不起作用
在RNN训练期间,信息不断地循环往复,神经网络模型权重的更新非常大。因为在更新过程中累积了错误梯度,会导致网络不稳定。极端情况下,权重的值可能变得大到溢出并导致NaN值。爆炸通过拥有大于1的值的网络层反复累积梯度导致指数增长产生,如果值小于1就会出现消失。
长短期记忆网络
RNN的上述缺点促使科学家开发了一种新的RNN模型变体,名为长短期记忆网络(Long Short Term Memory)。由于LSTM使用门来控制记忆过程,它可以解决这个问题。
下面让我们了解一下LSTM的架构,并将其与RNN的架构进行比较:
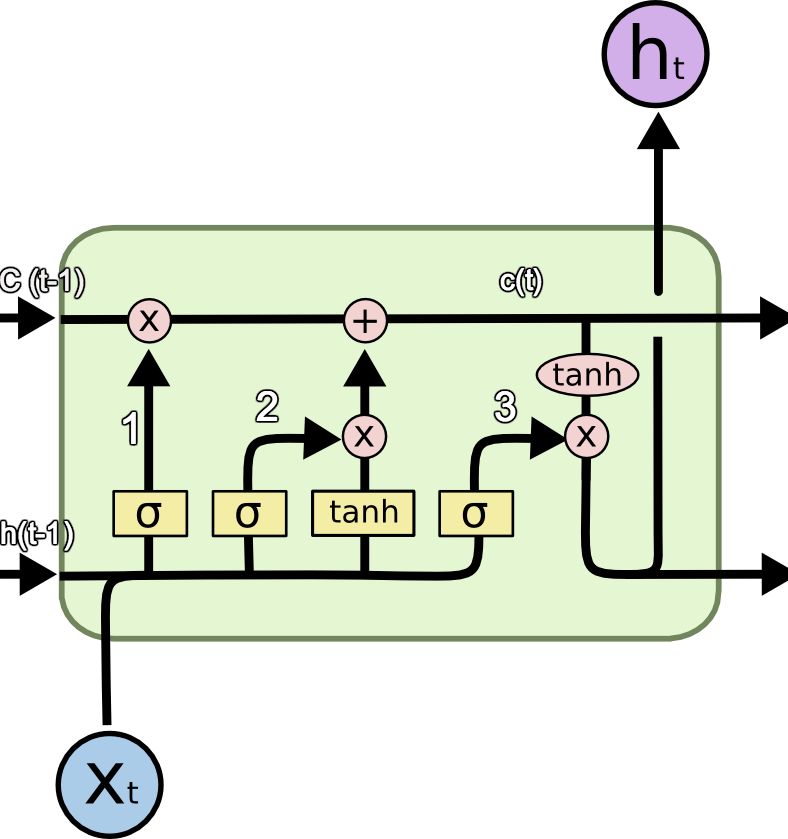
一个LSTM单位
这里使用的符号具有以下含义:
a)X:缩放的信息
b)+:添加的信息
c)σ:Sigmoid层
d)tanh:tanh层
e)h(t-1):上一个LSTM单元的输出
f)c(t-1):上一个LSTM单元的记忆
g)X(t):输入
h)c(t):最新的记忆
i)h(t):输出
为什么使用tanh?
为了克服梯度消失问题,我们需要一个二阶导数在趋近零点之前能维持很长距离的函数。tanh是具有这种属性的合适的函数。
为什么要使用Sigmoid?
由于Sigmoid函数可以输出0或1,它可以用来决定忘记或记住信息。
信息通过很多这样的LSTM单元。图中标记的LSTM单元有三个主要部分:
- LSTM有一个特殊的架构,它可以让它忘记不必要的信息。Sigmoid层取得输入X(t)和h(t-1),并决定从旧输出中删除哪些部分(通过输出0实现)。在我们的例子中,当输入是“他有一个女性朋友玛丽亚”时,“大卫”的性别可以被遗忘,因为主题已经变成了玛丽亚。这个门被称为遗忘门f(t)。这个门的输出是f(t)* c(t-1)。
- 下一步是决定并存储记忆单元新输入X(t)的信息。Sigmoid层决定应该更新或忽略哪些新信息。tanh层根据新的输入创建所有可能的值的向量。将它们相乘以更新这个新的记忆单元。然后将这个新的记忆添加到旧记忆c(t-1)中,以给出c(t)。在我们的例子中,对于新的输入,他有一个女性朋友玛丽亚,玛丽亚的性别将被更新。当输入的信息是,“玛丽亚在纽约一家著名的餐馆当厨师,最近他们在学校的校友会上碰面。”时,像“著名”、“校友会”这样的词可以忽略,像“厨师”、“餐厅”和“纽约”这样的词将被更新。
- 最后,我们需要决定我们要输出的内容。Sigmoid层决定我们要输出的记忆单元的哪些部分。然后,我们把记忆单元通过tanh生成所有可能的值乘以Sigmoid门的输出,以便我们只输出我们决定的部分。在我们的例子中,我们想要预测空白的单词,我们的模型知道它是一个与它记忆中的“厨师”相关的名词,它可以很容易的回答为“烹饪”。我们的模型没有从直接依赖中学习这个答案,而是从长期依赖中学习它。
我们刚刚看到经典RNN和LSTM的架构存在很大差异。在LSTM中,我们的模型学习要在长期记忆中存储哪些信息以及要忽略哪些信息。
使用LSTM快速实现情感分析
在这里,我使用基于keras的LSTM对Yelp开放数据集的评论数据进行情感分析。
下面是我的数据集。

数据集
我使用Tokenizer对文本进行了矢量化处理,并在限制tokenizer仅使用最常见的2500个单词后将其转换为整数序列。我使用pad_sequences将序列转换为二维numpy数组。
#I have considered a rating above 3 as positive and less than or equal to 3 as negative.
data['sentiment'] = ['pos' if (x>3) else 'neg' for x in data['stars']]
data['text'] = data['text'].apply((lambda x: re.sub('[^a-zA-z0-9\s]','',x)))
for idx,row in data.iterrows():
row[0] = row[0].replace('rt',' ')
data['text'] = [x.encode('ascii') for x in data['text']]
tokenizer = Tokenizer(nb_words=2500, lower=True,split=' ')
tokenizer.fit_on_texts(data['text'].values)
#print(tokenizer.word_index) # To see the dicstionary
X = tokenizer.texts_to_sequences(data['text'].values)
X = pad_sequences(X)
然后,我构建自己的LSTM网络。几个超参数如下:
- embed_dim:嵌入层将输入序列编码为维度为embed_dim的密集向量序列。
- lstm_out:LSTM将矢量序列转换为大小为lstm_out的单个矢量,其中包含有关整个序列的信息。
其他超参数,如dropout,batch_size与CNN中类似。
我使用softmax作为激活函数。

embed_dim = 128
lstm_out = 200
batch_size = 32
model = Sequential()
model.add(Embedding(2500, embed_dim,input_length = X.shape[1], dropout = 0.2))
model.add(LSTM(lstm_out, dropout_U = 0.2, dropout_W = 0.2))
model.add(Dense(2,activation='softmax'))
model.compile(loss = 'categorical_crossentropy', optimizer='adam',metrics = ['accuracy'])
print(model.summary())

现在,我将我的模型放在训练集上,并检查验证集的准确性。
Y = pd.get_dummies(data['sentiment']).values
X_train, X_valid, Y_train, Y_valid = train_test_split(X,Y, test_size = 0.20, random_state = 36)
#Here we train the Network.
model.fit(X_train, Y_train, batch_size =batch_size, nb_epoch = 1, verbose = 5)


在一个包含所有业务的小数据集上运行时,我在仅仅迭代一次就获得了86%的验证精度。
未来的改进方向:
- 我们可以筛选餐馆等特定业务,然后使用LSTM进行情感分析。
- 我们可以使用具有更大的数据集进行更多次的迭代来提高准确性。
- 可以使用更多隐藏的密集层来提高准确性。也可以调整其他超参数。
结论
当我们希望我们的模型从长期依赖中学习时,LSTM要强于其他模型。LSTM遗忘,记忆和更新信息的能力使其比经典的RNN更为先进。









