











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






国外人工智能研究:一种可以通过文本描述直接生成视频的AI模型
2018年02月24日 由 yuxiangyu 发表
91089
0
最近,一种新的方法可能会让电影编剧拒绝来自大型电影制片厂的巨额预算和强大资源 — 依靠文本进行视频生成(Video Generation from Text)。当然,从目前来看,生成的电影不可能去参选奥斯卡。但也许在未来,这样的技术可以在娱乐之外找到用途,比如帮助目击者重现车祸或犯罪现场等。
这个算法来自于最近的一篇论文(见下方链接)。它通过训练一个判别生成模型提取文本中静态和动态的信息。他是一个使用变分自编码器(VAE)和生成式对抗网络的混合框架(GAN)。
人工智能(AI)在识别图像的内容并提供标记的方面做的越来越好。这里的算法就是另一种从标签产生图像的方式。少数甚至可以从单个电影画面中预测下一个画面。但是从文本创建图像,并使它按照文本的描述运动,这样的方式还是第一次。
“据我所知,这是第一部看得过去的文本转视频作品。虽然并不完美,但至少他们看起来像是真正的视频。“比利时鲁汶大学的计算机科学家Tinne Tuytelaars表示,他自己也在做视频预测方面研究。
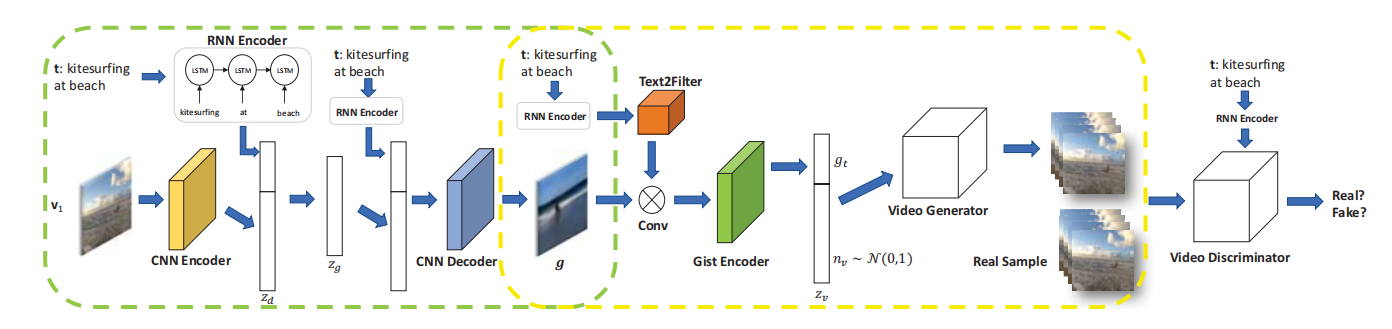
研究人员表示,该网络分两个阶段进行,旨在模仿人类创造艺术的方式。第一阶段使用文本创建视频的“gist”,一般是背景颜色和对象布局的模糊图像,主要动作发生在模糊的斑点上。第二阶段同时考虑到gist和文本,并产生一段短片。在训练时,第二个网络充当鉴别器。如果它看到生成的视频用于说明“海上航行”,那么它被训练选择“真实”海上航行的视频。当鉴别器变好后,它就会变得更加严格,为生成网络设置更高的标准。
研究人员对10种场景进行了算法训练,包括“在草地上打高尔夫球”和“在海上进行风筝冲浪”,然后粗糙的进行重制(画质极差)。一个简单的分类算法,猜测六种选择中的行为正确率大约有50%。(航海和风筝冲浪经常搞混)。此外,该网络还可以制造出一些不现实的视频,例如“ 在雪上航行 ”,以及“ 在游泳池打高尔夫球 ”等。



目前,这些视频只有32帧长约1秒,大小为64×64像素。论文的第一作者,杜克大学的计算机科学家Yitong Li表示,如果数据再大会降低准确性。并且目前的技术只能处理相对平滑的动态变化,无法对过快的动作或背景变化进行处理。他们计划在未来通过生成人类的姿态或骨骼特征构建更为强大的视频生成器,以解决这些障碍。
论文:http://www.aaai.org/GuideBook2018/16152-72279-GB.pdf
文件:http://www.cs.toronto.edu/pub/cuty/Text2VideoSupp/
这个算法来自于最近的一篇论文(见下方链接)。它通过训练一个判别生成模型提取文本中静态和动态的信息。他是一个使用变分自编码器(VAE)和生成式对抗网络的混合框架(GAN)。
框架图
人工智能(AI)在识别图像的内容并提供标记的方面做的越来越好。这里的算法就是另一种从标签产生图像的方式。少数甚至可以从单个电影画面中预测下一个画面。但是从文本创建图像,并使它按照文本的描述运动,这样的方式还是第一次。
“据我所知,这是第一部看得过去的文本转视频作品。虽然并不完美,但至少他们看起来像是真正的视频。“比利时鲁汶大学的计算机科学家Tinne Tuytelaars表示,他自己也在做视频预测方面研究。
研究人员表示,该网络分两个阶段进行,旨在模仿人类创造艺术的方式。第一阶段使用文本创建视频的“gist”,一般是背景颜色和对象布局的模糊图像,主要动作发生在模糊的斑点上。第二阶段同时考虑到gist和文本,并产生一段短片。在训练时,第二个网络充当鉴别器。如果它看到生成的视频用于说明“海上航行”,那么它被训练选择“真实”海上航行的视频。当鉴别器变好后,它就会变得更加严格,为生成网络设置更高的标准。
研究人员对10种场景进行了算法训练,包括“在草地上打高尔夫球”和“在海上进行风筝冲浪”,然后粗糙的进行重制(画质极差)。一个简单的分类算法,猜测六种选择中的行为正确率大约有50%。(航海和风筝冲浪经常搞混)。此外,该网络还可以制造出一些不现实的视频,例如“ 在雪上航行 ”,以及“ 在游泳池打高尔夫球 ”等。
文本的视频生成样本(红圈表示生成视频中行动的中心)
目前,这些视频只有32帧长约1秒,大小为64×64像素。论文的第一作者,杜克大学的计算机科学家Yitong Li表示,如果数据再大会降低准确性。并且目前的技术只能处理相对平滑的动态变化,无法对过快的动作或背景变化进行处理。他们计划在未来通过生成人类的姿态或骨骼特征构建更为强大的视频生成器,以解决这些障碍。
论文:http://www.aaai.org/GuideBook2018/16152-72279-GB.pdf
文件:http://www.cs.toronto.edu/pub/cuty/Text2VideoSupp/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消