如何在神经网络中选择正确的激活函数
n5 = (n1 * w1) + (n2 * w2) + (n3 * w3) + (n4 * w4)
n6 = (n1 * w5) + (n2 * w6) + (n3 * w7) + (n4 * w8)
n7 = (n1 * w9) + (n2 * w10) + (n3 * w11) + (n4 * w12)
每个神经元的值都需要被最小化,因为原始的输入数据可能是非常多样化的,而且可能是不成比例的。在进一步前馈前,必须激活n5,n6,n7。简单地说,你可以使用一系列函数来作为到达神经元的值的线性或非线性阈值(比如n5、n6和n7)。
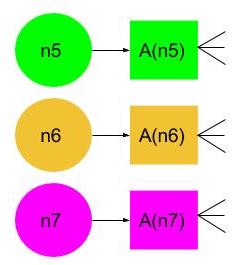
A()是激活函数,通常用来将它的输入压缩为更符合的比例值(取决于你选择的函数)。它通常是0到1之间的小数值。但是,如何才能做到压缩输入,并且应该使用什么样的函数来完成这个任务呢?
步骤函数是最简单的。它指出静态阈值通常为0.5(但也可能为0),并根据输入值大于或小于阈值来决定输出1或0。要记住,输入值几乎总是在0到1之间(或者可能是-1,1),因为权值总是像第一层的神经元一样。
def step(input): return 1 if (input > 0.5) else 0
这本质上是一种二进制的方法,当输入数据为二进制分类问题时,可以使用这种方法,在训练模型或者函数的例子中:
0,1 = 1
1,0 = 1
0,0 = 0
1,1 = 0
该模型将有两个输入神经元,隐藏层层大约四个神经元,输出层有一个神经元。在每一层上,由于问题是二进制的,步骤函数都是激活所需的全部。
最常用的激活函数是sigmoid函数(蓝色),与步骤函数(橙色)相比,它在图上是这样的:
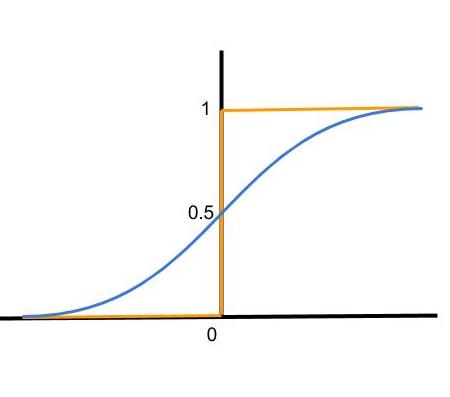
无论输入值高或低,它都将被压缩成0到1之间的比例值。它被认为是一种将值转化为概率的方法,它反映了神经元的权值或置信度。这就解释了模型的非线性特征,使它能够更深入地学习观察结果。默认情况下,你可以使用这个sigmoid函数来解决任何问题,并可以得到一些结果。
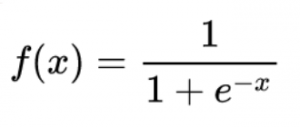
输出永远不可能是1,因为1是上水平渐近线。同样地,对于0,输出也总是趋向于它而不到达它。当然,在程序中,将会有一个点,输出是四舍五入的。
这里有一些示例的输入和输出,你可以准确地看到正在发生的事情:
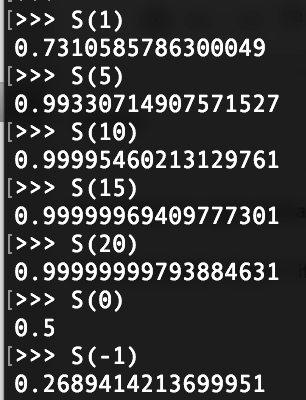
显然,S()是sigmoid函数。当反向传播时,需要在单个权值中找到误差范围,并且需要通过它的推导来返回Sigmoid函数:
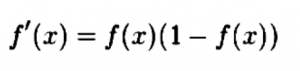
Tanh函数与sigmoid函数非常相似。然而,它的范围更大。它不返回0和1之间的值,而是给出-1和1的范围。这强调了观察结果,更加具体。因此,它适用于分类不同且门槛较低的更复杂的问题。如果你的数据相对简单,这会导致过度学习。正如你所看到的,TanH的方程与Sigmoid非常相似。
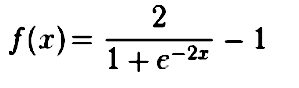
TanH函数的推导是:
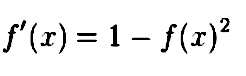
ReLU激活函数是深度学习中最常用且最成功的函数。乍一看,这似乎有些令人惊讶,因为迄今为止,非线性函数似乎更有效。ReLU的好处在反向传播中得以体现。有一种常见的经验法则是,神经网络上的层越多,就会更容易成功,然而这产生了一个著名的问题:消失梯度下降(vanishing gradient descent),许多非线性激活技术,如Sigmoid和Tanh。它单独地破坏了深度学习(有许多层)提供的巨大机会。
如果我们看一下一个小的神经网络的水平切片,也许只有一个隐藏层,消失梯度下降不会是太大的问题:
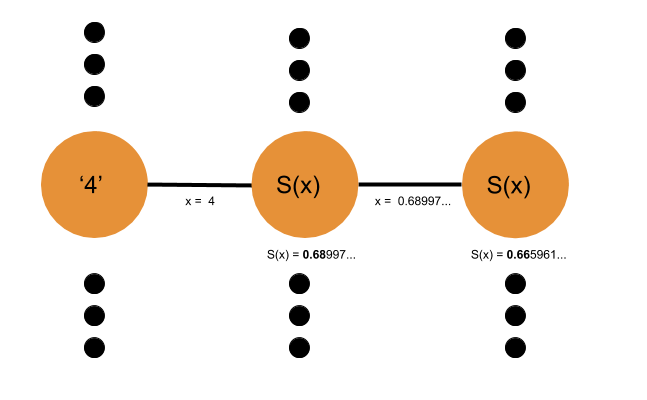
正如你所看到的,在每个神经元上,S()被再次调用。也就是S(S(x)),你一次又一次地压缩这个值。请记住,为了简单,我忽略了与其他神经元权值相乘的过程。层次越多,结果就越糟糕。现在,从0.68997到0.665961可能没问题,但请想象一下:

S(S(S(S(S(S(S(S(S(S(S(x)))))))))))
…你会得到一个意义与完整性已经消失了的值,此时igmoid函数推导过程为:

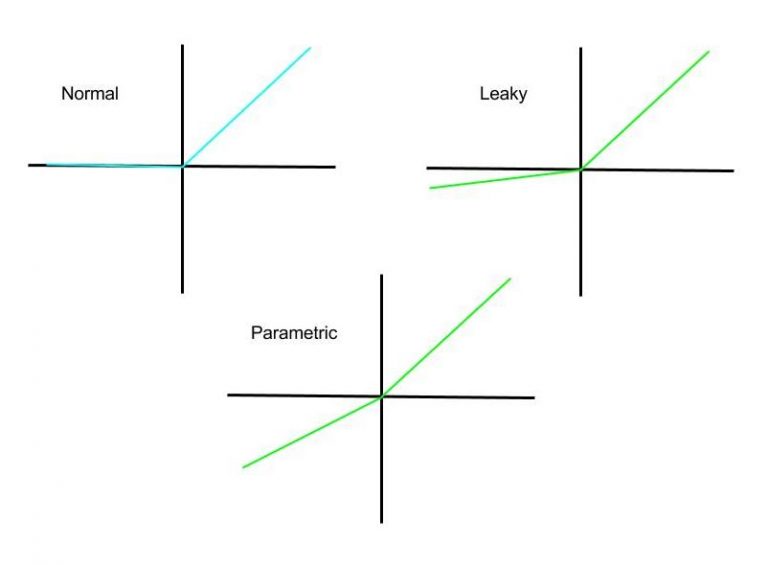
ReLU的优点是它不会压缩数值,因为它使用一种非常简单的静态方法:
R(x)= max(0,x)
它只是将任何负值映射为零,同时保留所有的正值。这就是为什么ReLU被用于更复杂的神经网络,如深度卷积网络。ReLU没有层限制。然而,ReLU失去了压缩数值的优势,但是避免了超限或放大问题。换句话说,它不能处理非常大的值,因为它不能压缩它们。ReLU的另一个问题是,在一些更极端的情况下,它可以消灭一个神经元。想象一下,在多次反向传播之后,一个特定的权值会随着时间的推移而调整为一个非常大的负值。反过来,这个值会乘以之前的神经元,并不断地产生一个负数作为下一个神经元的输入。因此,R(x)每次都会输出0,这是一个即将消失的神经元(注意,从技术上讲,它还有恢复的机会,它不是一个消失的神经元)。因此,有更有见解的ReLU版本,如参数化和漏型的直线单元(Leaky Rectified Linear Unit),(或PReLU和LReLU),它们都不只是将任何负值映射到0,而是(绿色):