


















一文搞懂自编码器及其用途(含代码示例)
- 编码器:将输入压缩为潜在空间表示。可以用编码函数h = f(x)表示。
- 解码器:这部分旨在重构来自隐藏空间表示的输入。可以用解码函数r = g(h)表示。
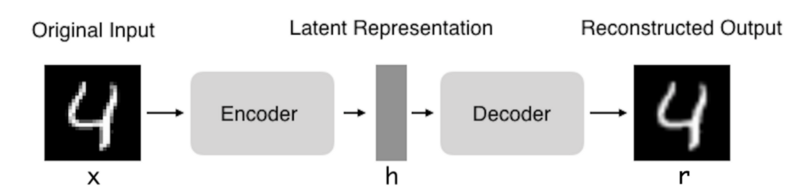
自编码器架构
因此自编码器的整体可以用函数g(f(x))= r来描述,其中我们想要得到的r与原始输入x相近。
为什么要将输入复制给输出?
很明显,如果自编码器的只是单纯的将输入复制到输出中,那么它没有用处。所以实际上,我们希望通过训练自编码器将输入复制到输出中,使隐藏表示的h拥有有用的属性。
通过在复制任务上创建约束条件来实现这点。想要从自编码器中获得有用特征,一种方法是约束h的维度小于x,在这种情况下,自编码器被称为欠完备(undercomplete)。通过训练不完整的表示,我们迫使自编码器学习训练数据的最有代表性(显著的)的特征。如果给自编码器的容量过大,则它可以学习执行复制任务而不去提取关于数据分布的有用信息。如果隐藏表示的维度与输入相同,并且处于过完备的情况下潜在表示的维度大于输入。在这些情况下,即使线性编码器和线性解码器也可以学习将输入复制到输出,而无需学习有关数据分布的有用信息。理论上,可以成功地训练任何自编码器架构,根据要分配的复杂度来选择编码器和解码器的代码维数和容量然后建模。
自编码器的用途
如今,数据可视化的数据降噪和降维被认为是自编码器的两个主要的实际应用。使用适当的维度和稀疏性约束,自编码器可以得到比PCA或其他类似技术更好的数据投影。
自编码器通过数据示例自动学习。这意味着很容易训练在特定类型的输入中表现良好的算法的特定实例,并且不需要任何新的结构,只需适当的训练数据即可。
但是,自编码器在图像压缩方面做得并不好。由于自编码器是在给定的一组数据上进行训练的,因此它将得到与所用训练集数据相似的压缩结果,但对通用的图像压缩器来说效果并不好。至少不如像JPEG这样的压缩技术。
自编码器被训练成,可以在输入通过编码器和解码器后保留尽可能多的信息,但也会被训练成,使新的表示具有各种不错的属性。不同类型的自编码器旨在实现不同类型的属性。我们将重点介绍四种类型的自编码器。
自编码器的类型
在本文中,将介绍以下四种类型的自编码器:
- 普通的自编码器
- 多层自编码器
- 卷积自编码器
- 正则化自编码器
为了说明不同类型的自编码器,我们使用Keras框架和MNIST数据集创建了每个类型的示例。
示例链接:https://github.com/Yaka12/Autoencoders
普通的自编码器
这是最简单的自编码器,它有三层网络,只有神经网络的隐藏层只有一个。输入和输出是相同的,我们需要学习如何重构输入,例如使用adam优化器和均方误差损失函数。
接下来我会展示一个不完备的自编码器,隐藏层维度(64)小于输入(784)。这个约束将使我们的神经网络学习一个压缩的数据表示。
input_size = 784
hidden_size = 64
output_size = 784
x = Input(shape=(input_size,))
# Encoder
h = Dense(hidden_size, activation='relu')(x)
# Decoder
r = Dense(output_size, activation='sigmoid')(h)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
多层自编码器
如果一个隐藏层不够用,我们显然可以为自编码器建立更多的隐藏层。
现在我们的实现使用3个隐藏层。任何隐藏层都可以作为特征表示,但为了使网络对称我们使用最中间的层。
input_size = 784
hidden_size = 128
code_size = 64
x = Input(shape=(input_size,))
# Encoder
hidden_1 = Dense(hidden_size, activation='relu')(x)
h = Dense(code_size, activation='relu')(hidden_1)
# Decoder
hidden_2 = Dense(hidden_size, activation='relu')(h)
r = Dense(input_size, activation='sigmoid')(hidden_2)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
卷积自编码器
那么,自编码器可以用卷积代替完全连接层吗?
答案当然是肯定的,原理是一样的,但是使用象征(3维的向量)代替一维矢量。对输入的象征进行降采样以提供较小维度潜在表示,并强制自编码器学习象征的压缩版本。
x = Input(shape=(28, 28,1))
# Encoder
conv1_1 = Conv2D(16, (3, 3), activation='relu', padding='same')(x)
pool1 = MaxPooling2D((2, 2), padding='same')(conv1_1)
conv1_2 = Conv2D(8, (3, 3), activation='relu', padding='same')(pool1)
pool2 = MaxPooling2D((2, 2), padding='same')(conv1_2)
conv1_3 = Conv2D(8, (3, 3), activation='relu', padding='same')(pool2)
h = MaxPooling2D((2, 2), padding='same')(conv1_3)
# Decoder
conv2_1 = Conv2D(8, (3, 3), activation='relu', padding='same')(h)
up1 = UpSampling2D((2, 2))(conv2_1)
conv2_2 = Conv2D(8, (3, 3), activation='relu', padding='same')(up1)
up2 = UpSampling2D((2, 2))(conv2_2)
conv2_3 = Conv2D(16, (3, 3), activation='relu')(up2)
up3 = UpSampling2D((2, 2))(conv2_3)
r = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(up3)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
正则化的自编码器
除强加一个比输入更低维度的隐藏层外,还有其他一些方法可以限制自编码器的重构。正则化自编码器不需要通过保持编码器和解码器的浅层和程序的小体量来限制模型容量,而是使用损失函数来鼓励模型取得除了将输入复制到其输出之外的其他属性。在实践中,我们通常会使用两种正则化自编码器:稀疏自编码器和降噪自编码器。
稀疏自编码器:稀疏自编码器通常用于学习诸如分类等任务的特征。已被正则化为稀疏的自编码器必须响应训练后数据集的唯一统计特征,而不仅仅是作为标识函数。通过这种方式,训练执行带有稀疏惩罚的复制任务可以产生一个学习有用特征作为副产(byproduct)的模型。
我们可以限制自编码器重构的另一种方式是对其损失施加约束。例如,我们可以在损失函数中添加一个正则化项。这样做可以会使我们的自编码器学习数据的稀疏表示。
注意在的隐藏层中,我们添加了一个l1激活值正则化矩阵(activity regularizer),它将在优化阶段对损失函数施加一个惩罚,与普通的自编码器相比,现在的表示方式更加稀疏。
input_size = 784
hidden_size = 64
output_size = 784
x = Input(shape=(input_size,))
# Encoder
h = Dense(hidden_size, activation='relu', activity_regularizer=regularizers.l1(10e-5))(x)
# Decoder
r = Dense(output_size, activation='sigmoid')(h)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
降噪自编码器:我们可以不对对损失函数添加惩罚,而是通过改变损失函数的重构误差项,得到一个可以学习一些有用的东西的自编码器。这可以通过给输入象征添加一些噪声并使自编码器学会删除它来实现。通过这种方式,编码器将提取最重要的特征并学习数据更具鲁棒性的表示。
x = Input(shape=(28, 28, 1))
# Encoder
conv1_1 = Conv2D(32, (3, 3), activation='relu', padding='same')(x)
pool1 = MaxPooling2D((2, 2), padding='same')(conv1_1)
conv1_2 = Conv2D(32, (3, 3), activation='relu', padding='same')(pool1)
h = MaxPooling2D((2, 2), padding='same')(conv1_2)
# Decoder
conv2_1 = Conv2D(32, (3, 3), activation='relu', padding='same')(h)
up1 = UpSampling2D((2, 2))(conv2_1)
conv2_2 = Conv2D(32, (3, 3), activation='relu', padding='same')(up1)
up2 = UpSampling2D((2, 2))(conv2_2)
r = Conv2D(1, (3, 3), activation='sigmoid', padding='same')(up2)
autoencoder = Model(input=x, output=r)
autoencoder.compile(optimizer='adam', loss='mse')
总结
在本文中,我们介绍了自编码器的基本架构。我们还研究了许多不同类型的自编码器。这些自编码器根据不同的约束,有着不同的属性。









