











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI发布8个模拟机器人环境以及一种HER实现,以训练实体机器人模型
2018年02月27日 由 yining 发表
658165
0
 OpenAI:我们将发布8个模拟的机器人环境,以及一种叫做“事后经验回顾”(Hindsight Experience Replay,简称HER)的一种Baselines实现,它允许从简单的、二元的奖励中学习,从而避免了对复杂的奖励工程的需求。所有这些都是为我们过去一年的研究而开发的。我们利用这些环境来训练在实体机器人上工作的模型,并且还发布了一组机器人研究的请求。
OpenAI:我们将发布8个模拟的机器人环境,以及一种叫做“事后经验回顾”(Hindsight Experience Replay,简称HER)的一种Baselines实现,它允许从简单的、二元的奖励中学习,从而避免了对复杂的奖励工程的需求。所有这些都是为我们过去一年的研究而开发的。我们利用这些环境来训练在实体机器人上工作的模型,并且还发布了一组机器人研究的请求。相关链接:
- 关于HER的相关论文:https://arxiv.org/abs/1707.01495
- 实体机器人:https://blog.openai.com/robots-that-learn/;https://blog.openai.com/generalizing-from-simulation/
- 机器人研究的请求:https://blog.openai.com/ingredients-for-robotics-research/#requestsforresearchheredition
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2018/02/videoplayback-1.mp4"][/video]
- Gym环境:https://gym.openai.com/envs/#robotics
- OpenAI Baselines是一组高质量的强化学习算法的实现。Github地址:https://github.com/openai/baselines
- 技术报告:https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/ingredients-for-robotics-research/technical-report.pdf
这次发布了包括四个使用Fetch科研平台的环境,以及使用ShadowHand机器人的四个环境。这些环境中所包含的操作任务要比目前在Gym使用的MuJoCo持续控制环境要困难得多,这些环境现在都可以使用像PPO这样的最近发布的算法来解决。此外,我们新发布的环境使用了真实的机器人模型,并要求agent解决实际任务。
环境
这次发布为Gym提供了8个机器人环境,使用了MuJoCo物理模拟器。环境如下:
Fetch

FetchReach-v0(抵达):Fetch必须将它的末端执行器(在机器人技术中,末端执行器是机器人手臂末端的装置,它是用来与环境进行交互的。这个装置的确切性质取决于机器人的应用。)移动到期望的目标位置。

Fetchslide-v0(滑动):Fetch必须在一个长桌上打击一个冰球,这样它就可以滑过,并在期待的目标上停下来。


FetchPickAndPlace-v0(捡起和放置):Fetch必须使用它的夹钳从一个桌子上捡起一个盒子(黑色),并将它移动到桌面上的一个期望的目标上。
ShadowHand(一种机械手臂)

HandReach-v0:ShadowHand必须用它的拇指和一个选定的手指来接触,直到它们在手掌上达到一个理想的目标位置。

HandManipulateBlock-v0(机械手操控一个块):ShadowHand必须操作一个块,直到它达到预期的目标位置并旋转。

HandManipulateEgg-v0(机械手操控一个蛋体):ShadowHand必须操控一个蛋体,直到它达到一个理想的目标位置并旋转。

HandManipulatePen-v0(机械手操控一支笔):ShadowHand必须操控一支笔,直到它达到理想的目标位置并旋转。
目标
所有的新任务都有一个“目标”的概念,例如在滑动任务中冰球的期望位置,或者在机械手操控块任务中的期望方向。如果期望的目标还没有达到,那么所有的环境默认使用的是-1的稀疏奖励。如果达到了(在一定的范围内),那么是0。这与被用于传统的Gym持续控制问题的成型的(shaped)奖励形成了鲜明的对比,例如,Walker2d-v2。
我们还包括一个对每个环境都有密集奖励的变体。然而,我们相信,在机器人应用程序中,稀疏的奖励更现实一些,我们鼓励每个人使用这种稀疏的奖励变体。
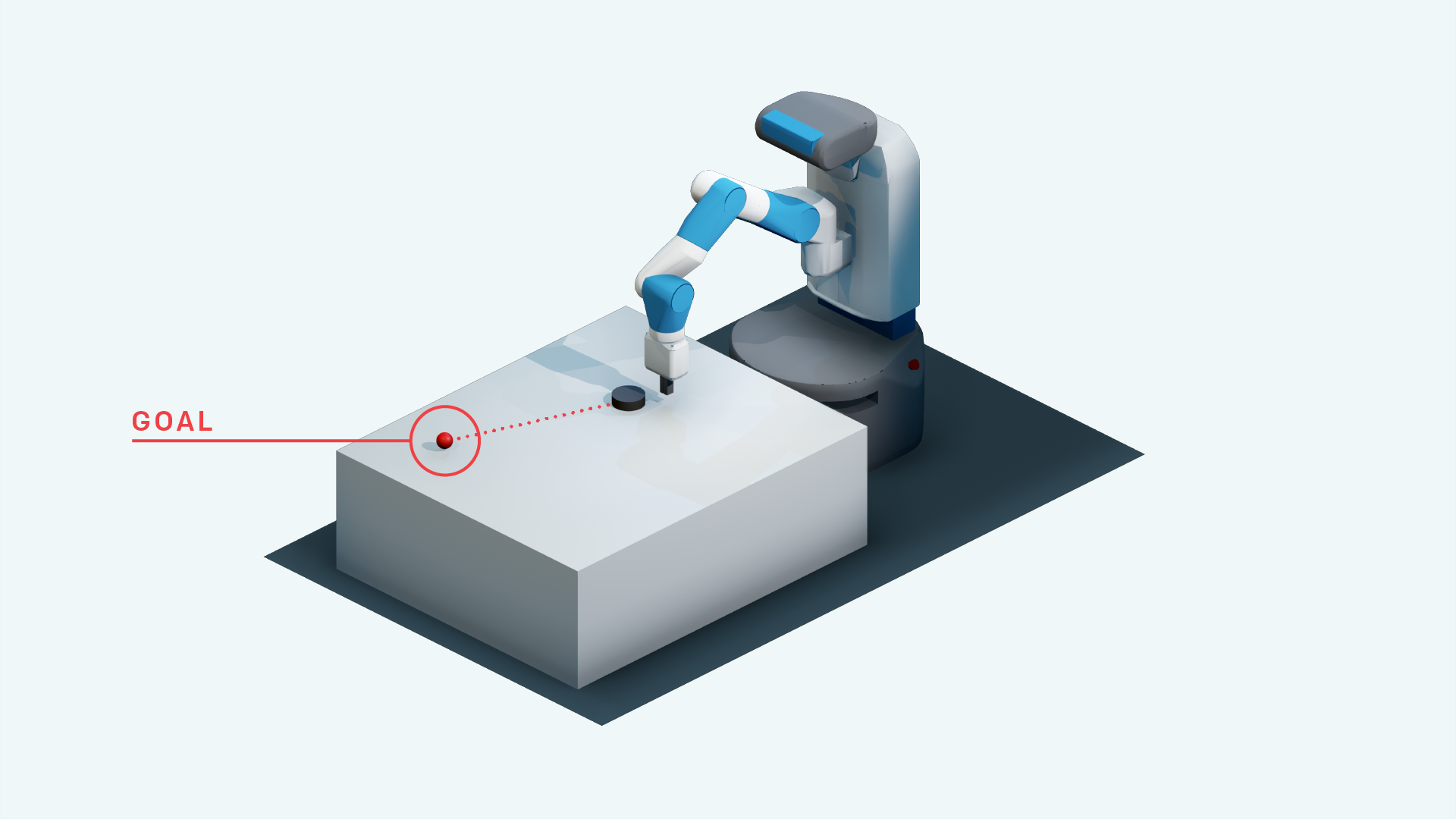
事后经验回顾
除了这些新的机器人环境,我们还发布了事后经验回顾(Hindsight Experience Replay,简称HER)的代码(如下),这是一种可以从失败中学习的强化学习算法。我们的研究结果表明,HER可以从很少的奖励中学习到大多数新的机器人问题的成功策略。在此基础上,我们还展示了未来研究的一些潜在方向,进一步提高了HER算法在这些任务中的性能。
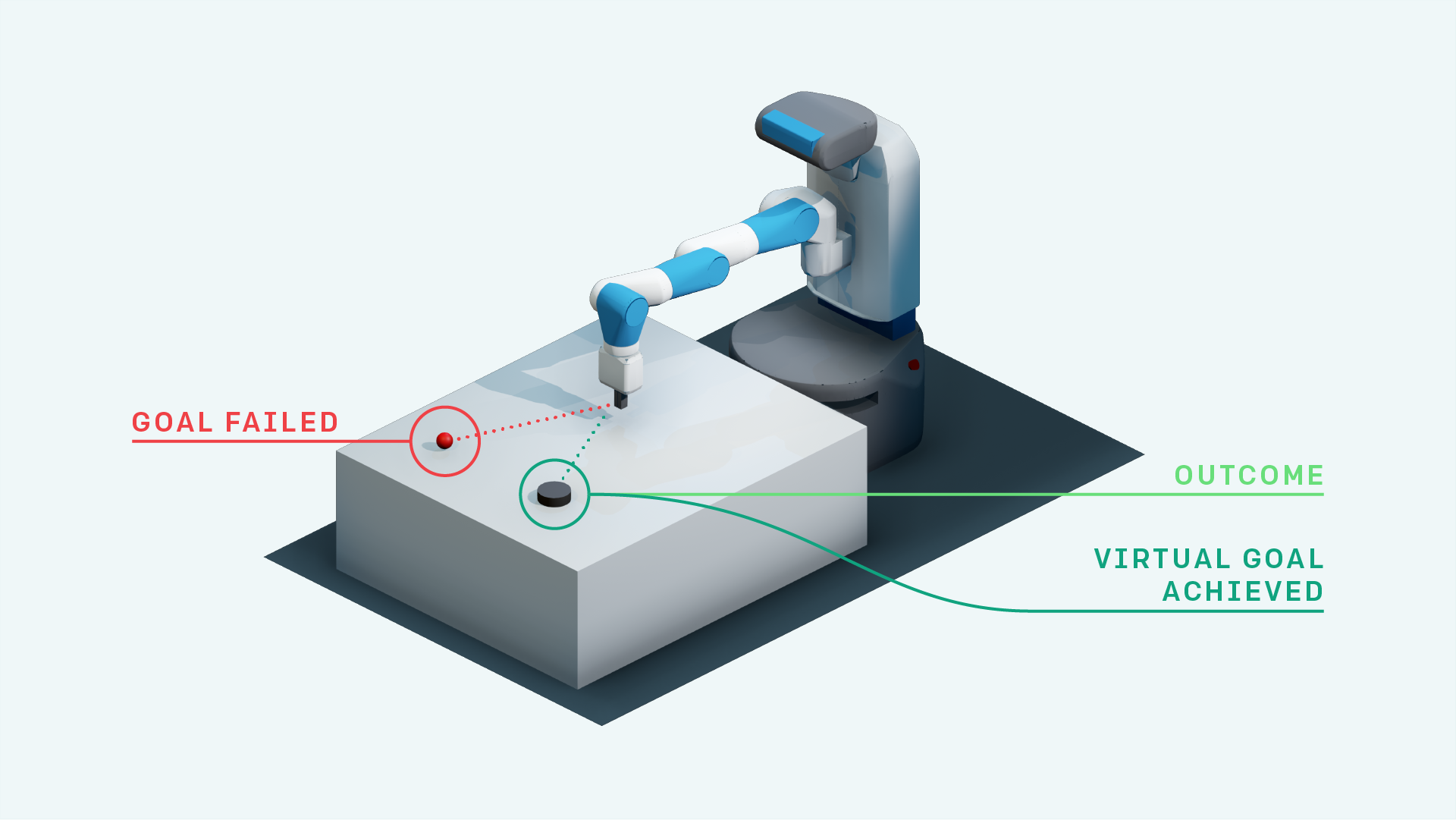
了解HER
为了了解HER的作用,让我们在FetchSlide(上文提到)的背景下看一看,我们需要学习将一个冰球滑过桌子并击中一个目标。我们的第一次尝试很可能不会成功。除非我们非常幸运,否则接下来的几次尝试也很可能不会成功。典型的强化学习算法不会从这种经验中学到任何东西,因为它们只获得一个不包含任何学习信号的恒定奖励(在这种情况下是-1)。
HER的正式观点是人类直觉上所做的:即使我们没有在一个特定的目标上取得成功,我们至少也取得了一个不同的目标。那么,为什么不只是假装我们想要开始实现这个目标,而不是我们最初想要实现的目标呢? 通过进行这种替换,强化学习算法可以获得一个学习信号,因为它已经达到了一定的目标;即使这不是我们最初想要达到的目标。如果我们重复这个过程,我们最终将学会如何实现任意的目标,包括我们真正想要实现的目标。
这种方法可以让我们学会如何在桌子上滑动一个冰球,尽管我们的奖励是非常稀疏的,即使我们可能从来没有真正达到我们想要的目标。我们将这种技术称为事后经验回顾(HER),因为在事件结束后,它回顾了目标经验(一种通常在DQN和DDPG等非策略的强化学习算法中使用的技术),这些目标经验都是事后选择的。因此,HER可以与任何偏离策略的强化学习算法相结合(例如,HER可以与DDPG算法结合使用,我们将其称为“DDPG+HER算法”)。
结果
我们发现HER在以目标为基础的环境中工作得非常好,而奖励却很稀疏。我们在新任务上比较了DDPG+HER算法和vanilla DDPG算法。这种比较包括每种环境的稀疏和密集版本的奖励。
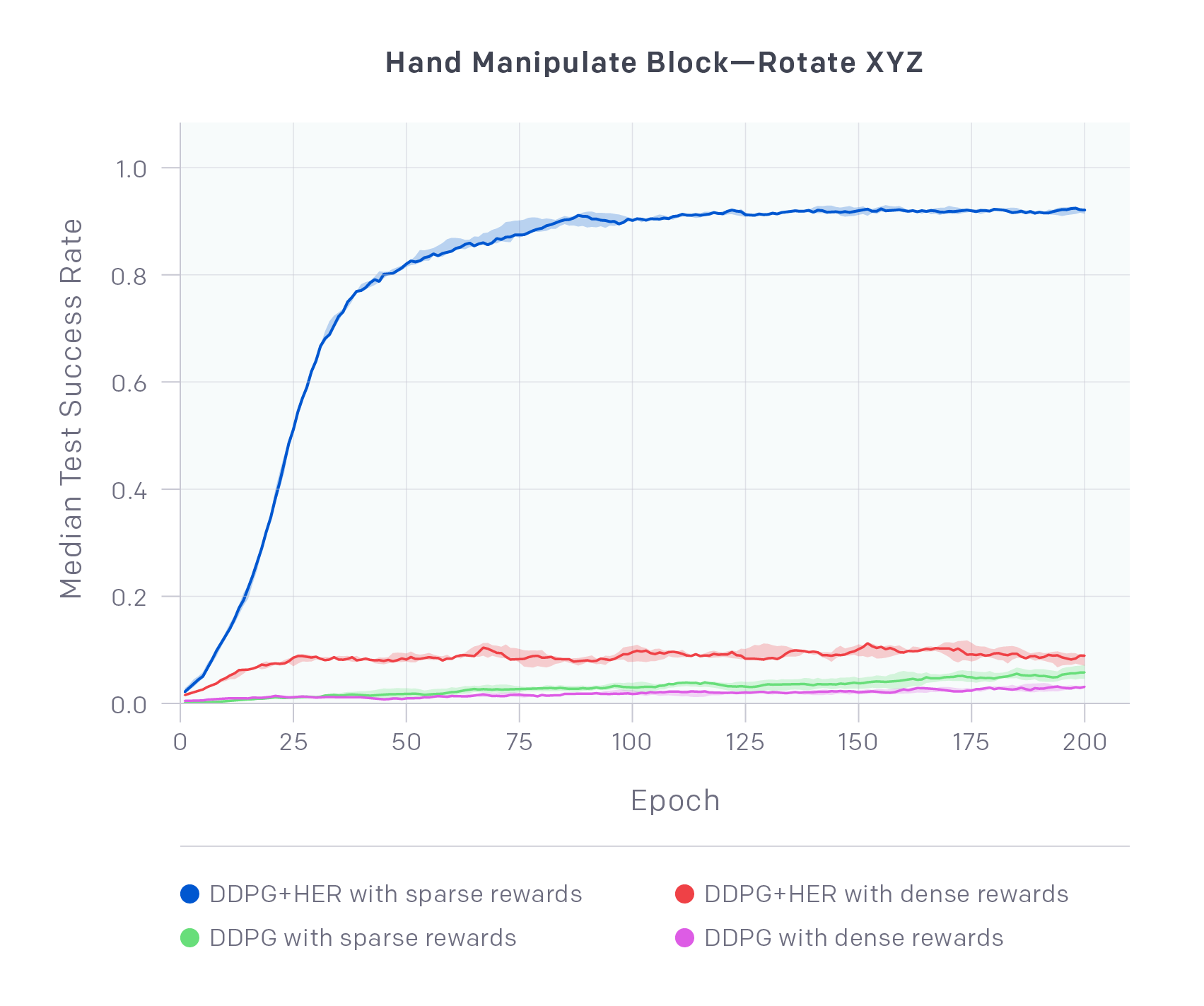 对于在
对于在HandManipulateBlockRotateXYZ-v0上的四个不同的配置的中位数检测成功率(线)和四分位距(阴影区域)。数据是在训练epoch上进行绘制的(plot),并总结了每个配置的5个不同的随机种子。DDPG+HER的稀疏奖励远远超过其他的配置,并且在这个具有挑战性的任务上学习了一个成功的策略,只有很稀疏的奖励。有趣的是,DDPG+HER的密集奖励可以学习,但成绩更差。在这两种情况下,Vanilla DDPG大多都无法学习。我们发现这种趋势在大多数环境中都是正确的,并且在我们的技术报告中包含了完整的结果。
研究请求:HER版本
虽然HER是一种很有前途的方法,可以通过我们在这里提出的机器人环境来学习复杂的基于目标的任务,但是仍然有很大的改进空间。与我们最近推出的研究请求2.0版本的要求相似,我们有一些关于如何改进HER的方法,以及强化学习的方法。
- 事后自动创建目标:我们现在有一个硬编码的策略来选择我们想要替代的事后目标。如果这一策略能被学会,那将是很有趣的。
- 无偏见的HER:以一种没有原则的方式,目标的替代改变了经验的分配。这种偏见在理论上会导致不稳定,尽管我们在实践中并没有发现这种偏见。尽管如此,推出一个没有偏见的版本还是很不错的,例如利用重要性采样(统计学中估计某一分布性质时使用的一种方法。该方法从与原分布不同的另一个分布中采样,而对原先分布的性质进行估计。来源:维基百科)。
- HER+HRL:将HER与分层强化学习(HRL)中的一个近期的想法结合起来将会很有趣。它不仅可以应用于目标,还可以应用于高级策略所生成的操作。例如,如果较高的水平要求较低的水平实现目标A,而目标B是实现的,我们可以假设更高的水平要求我们最初实现目标B。
- 更快的信息传播:大多数无策略的深层强化学习算法使用目标网络来稳定训练。然而,由于变化需要时间来传播,这将限制训练的速度,我们在实验中注意到,它往往是决定DDPG+HER学习速度的最重要因素。研究其它不引起这种减速的稳定训练的方法是很有趣的。
- HER+多步骤的返回:在HER上所使用的经验是非常没有策略的,因为我们可以替代目标。这使得在多步骤返回时很难使用它。但是,多步骤返回是可取的,因为它们允许更快地传播关于返回的信息。
- 有策略的HER:目前,HER只能在无策略的算法中使用,因为我们可以替代目标,使这种体验极度偏离策略。然而,最近像PPO这样的算法表现出了非常有吸引力的稳定性特征。研究HER是否能与这种有策略的算法结合在一起是很有趣的,例如重要性采样。在这个方向上已经有了一些初步的结果。
- 非常频繁的强化学习行动:当前的强化算法对采取行动的频率非常敏感,这就是为什么在Atari开发的游戏中使用跳帧技术的原因。在连续的控制域中,当动作的频率趋于无穷时,性能趋于零,这是由两个因素造成的:不一致的探索和引导程序(bootstrap)需要更多时间来传播关于及时返回的信息。如何设计一种简单高效的强化算法,即使当动作的频率趋于无穷时,它仍然能保持它的性能呢?
- 把HER和最近在强化学习上的进步结合起来:最近有大量的研究可以改善强化学习的不同方面。一开始,HER可以与优先化经验回顾、分布式强化学习、熵正则化强化学习或反向课程生成相结合。你可以在技术报告中找到关于这些建议和新Gym环境的附加信息和参考资料。
使用基于目标的环境
引入“目标”的概念需要对现有的Gym API进行一些向后兼容的改变:
- 所有基于目标的环境都使用一个gym.spaces.Dict。环境被期待包含一个期望的目标,agent应该尝试实现(
desired_goal),它当前实现的反而是(achieved_goal),以及实际的观察(observation),例如机器人的状态。 - 我们公开了一个环境的奖励功能,因此允许用改变的目标来重新计算一个奖励。这支持了HER方式的算法,这种算法可以替代目标。
这里有一个简单的例子,它与基于目标的环境进行交互,并执行目标替换:
import numpy as np
import gym
env = gym.make(′FetchReach-v0′)
obs = env.reset()
done = False
def policy(observation, desired_goal):
# Here you would implement your smarter policy. In this case,
# we just sample random actions.
return env.action_space.sample()
while not done:
action = policy(obs[′observation′], obs[′desired_goal′])
obs, reward, done, info = env.step(action)
# If we want, we can substitute a goal here and re-compute
# the reward. For instance, we can just pretend that the desired
# goal was what we achieved all along.
substitute_goal = obs[′achieved_goal′].copy()
substitute_reward = env.compute_reward(
obs[′achieved_goal′], substitute_goal, info)
print(′reward is {}, substitute_reward is {}′.format(
reward, substitute_reward))
新的基于目标的环境可以与现有的与Gym匹配的强化学习算法,比如Baseline一起使用。使用gym.wrappers.FlattenDictWrapper将基于dict的观察空间flatten为一个数组:
import numpy as np
import gym
env = gym.make(′FetchReach-v0′)
# Simply wrap the goal-based environment using FlattenDictWrapper
# and specify the keys that you would like to use.
env = gym.wrappers.FlattenDictWrapper(
env, dict_keys=[′observation′, ′desired_goal′])
# From now on, you can use the wrapper env as per usual:
ob = env.reset()
print(ob.shape) # is now just an np.array

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消