


















如何在15分钟内建立一个深度学习模型?
我们正在开源Lore框架,这个框架可供机器学习研究人员使用。
Lore地址:https://github.com/instacart/lore
机器学习常常给人一种这样的感觉:

论文没有告诉我该如何工作......
常见问题
- 当你在Python或SQL等编写定制代码时,性能瓶颈很容易受到影响。
- 代码复杂性增长的原因在于有价值的模型是多次迭代变化的结果,因此随着代码以非结构化方式演变,使得个人洞察更难以维护和沟通。
- 随着数据和库依赖性不断变化,可重复性受到影响。
- 信息过载使得在尝试试验最新论文,软件包,特征,修改错误时,很容易错过最新可用的轻松实现目标的方法...对于刚进入该领域的人来说,情况更糟糕。
为了解决这些问题,我们将Lore中的机器学习标准化。在Instacart,我们三个团队使用Lore进行所有新的机器学习开发,目前我们正在运行十几种Lore模型。
TLDR
如果你想要一个超级快速的在没有上下文的情况下进行预测的演示服务,你可以从github复制can my_app。如果你想要了解整个过程,请跳至概要(即15分钟概要)。
ip3 install lore
$ git clone https://github.com/montanalow/my_app.git
$ cd my_app
$ lore install # caching all dependencies locally takes a few minutes the first time
$ lore server &
$ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Banana&department=produce"
特征参数
了解这些优势的最好方法是在15分钟内将自己的深度学习项目投入生产。如果你想在查看终端与开始编写代码之前查看特征参数,请阅读以下简要概述:
- 模型支持使用数据Pipeline对估计器进行超参数搜索。他们将有效地利用带有两种不同策略的多个GPU(如果可用),并且水平可伸缩性可以保存和分发。
- 支持来自多个软件包的估计器:Keras,XGBoost和SciKit Learn。它们都可以通过build, fit 或 predict覆盖来进行分类,以完全自定义你的算法和架构,同时还可以从其他任何方面受益。
- Pipeline可以避免训练和测试集之间的信息泄漏,一条Pipeline可以用许多不同的估计器进行实验。如果超过了机器的可用RAM,则可使用基于磁盘的Pipeline。
- 变压器标准化先进的特征工程。例如,使用美国人口普查数据将名字转换为其统计年龄或性别。从自由形式的电话号码字符串中提取地理区号。常见的日期,时间和字符串操作通过pandas得到有效支持。
- 编码器为估计器提供强大的输入,并避免常见的缺失和长尾值问题。它们经过了充分测试,可以帮助你将垃圾排除出去。
- 对于流行的(无)sql数据库,通过应用程序以标准方式配置和连接IO连接,对批量数据进行事务管理和读写优化,而不是典型的ORM单行操作。连接共享一个可配置的查询缓存,除了用于分发模型和数据集的加密的S3存储器之外。
- 开发中每个应用程序的依赖管理,可以100%复制到生产环境中。没有打破python的手动激活,魔法环境变量或隐藏的文件。不需要venv,pyenv,pyvenv,virtualenv,virtualenvwrapper,pipenv,conda的知识。
- 模型测试可以在持续集成环境中运行,允许持续部署进行代码和训练更新,而无需增加基础架构团队的工作量。
- 工作流支持你是否喜欢命令行,Python控制台,jupyter notebook或IDE。每个环境都可以为生产和开发配置可读的日志和时序语句。
15分钟概要
基本的python知识是必需的。如果你的机器拒绝学习,你可以在接下来的一年里探索错综复杂的机器学习。
- 创建一个新的应用程序 (3分钟)
- 设计一个模型 (1分钟)
- 生成一个支架(2分钟)
- 实现一个Pipeline5分钟)
- 测试代码(1分钟)
- 训练模型(1分钟)
- 部署到生产环境(2分钟)
1)创建一个新的应用程序
Lore独立管理每个项目的依赖关系,以避免与系统python或其他项目发生冲突。将Lore安装作为标准pip软件包:
# On Linux
$ pip install lore
# On OS X use homebrew python 2 or 3
$ brew install python3 && pip3 install lore
当你不能复制别人的工作环境时,很难重复别人的工作。Lore保留你的操作系统喜欢的系统python方式,以防止依赖性错误和项目冲突。每个Lore应用程序都有它自己的目录,有自己的python安装,只需将它的依赖关系锁定到
runtime.txt 和 requirements.txt的指定版本中。 这使得分享Lore应用程序的效率更高,并使我们向机器学习项目迈进了一步。通过安装Lore,你可以创建一个新的深度学习项目应用程序。Lore默认是模块化和小变更(slim),因此我们需要指定
--keras 来安装此项目的深度学习依赖项。$ lore init my_app --python-version=3.6.4 --keras
2)设计一个模型
对于demo,我们将建立一个模型,以预测Instacart网站上的产品仅基于其名称和我们的参与将会产生多大的受欢迎程度。世界各地的制造商用各个不同的焦点小组测试产品名称,同时零售商优化其产品以最大限度地提高吸引力。我们的简单人工智能将提供相同的服务,因此零售商和制造商可以更好地了解商品在新市场中的销售。
机器学习最难的部分之一就是获取优质数据。幸运的是,Instacart已经发布了300万份匿名杂货订单,我们将重新调整这项任务。然后,我们可以将我们的问题形成一个监督学习回归模型,该模型根据2个特征预测年销售量:产品名称和部门。
请注意,我们将建立的模型仅用于说明目的 - 事实上,它很糟糕。
3)生成一个支架
$ cd my_app
$ lore generate scaffold product_popularity --keras --regression --holdout
每个lore模型都包含一个用来装载和编码数据的Pipeline,以及实现特定机器学习算法的估计器。模型中有趣的部分是生成类的实现细节。
Pipeline从左侧的原始数据开始,并将其编码到右边的期望型式中。然后使用编码的数据对估计器进行训练,在验证集中进行早期停止,并在测试集上进行评估。所有的东西都可以序列化到模型存储中,然后再加载一个liner进行部署。
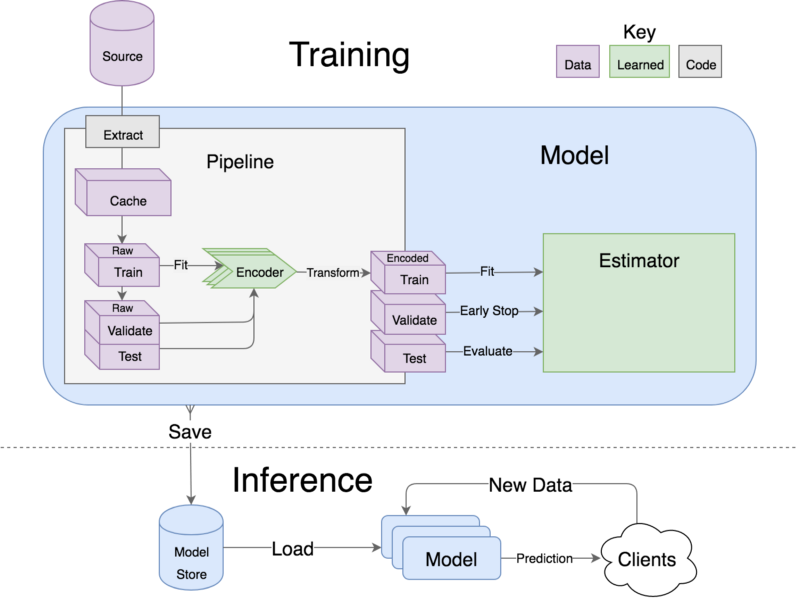
通过它的生命周期剖析一个模型
4)实施Pipeline
非常适合机器学习算法的原始数据很少见。通常我们从数据库加载它或下载一个CSV文件,对算法进行适当的编码,然后将其分解为训练集和测试集。
lore.pipelines中的基本类别将此逻辑封装在标准工作流程中。lore.pipelines.holdout.Base将我们的数据分割成训练,验证和测试集,并对我们的机器学习算法进行编码。我们的子类将负责定义3个方法: methods: get_data, get_encoders, 和 get_output_encoder。Instacart发布的数据分布在多个csv文件中,如数据库表。
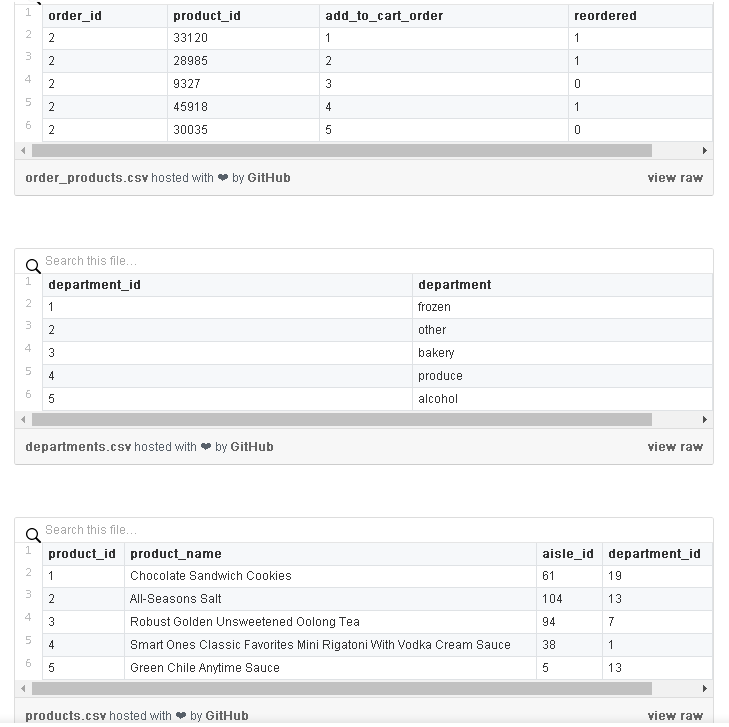
我们Pipeline的
get_data将下载原始Instacart数据,并使用pandas将其加入到具有以总单位为特征(product_name, department)和响应(sales)的DataFrame中,例如: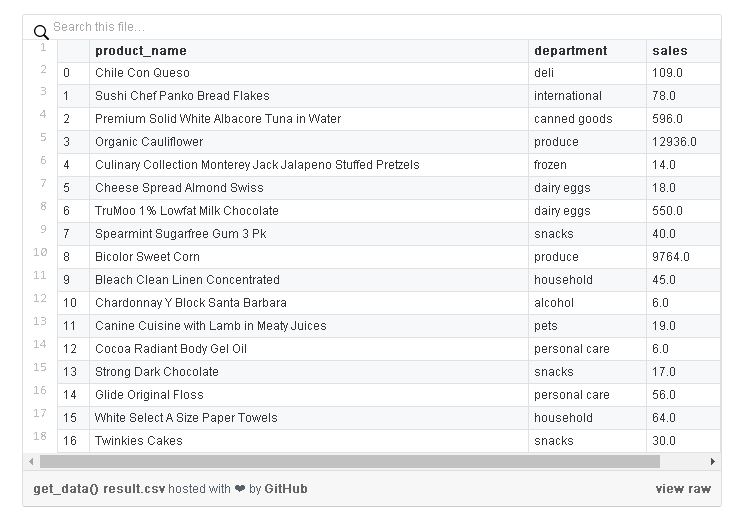
下面是
get_data的实现:# my_app/pipelines/product_popularity.py part 1
import os
from lore.encoders import Token, Unique, Norm
import lore.io
import lore.pipelines
import lore.env
import pandas
class Holdout(lore.pipelines.holdout.Base):
# You can inspect the source data csv's yourself from the command line with:
# $ wget https://s3.amazonaws.com/instacart-datasets/instacart_online_grocery_shopping_2017_05_01.tar.gz
# $ tar -xzvf instacart_online_grocery_shopping_2017_05_01.tar.gz
def get_data(self):
url = 'https://s3.amazonaws.com/instacart-datasets/instacart_online_grocery_shopping_2017_05_01.tar.gz'
# Lore will extract and cache files in lore.env.data_dir by default
lore.io.download(url, cache=True, extract=True)
# Defined to DRY up paths to 3rd party file hierarchy
def read_csv(name):
path = os.path.join(
lore.env.data_dir,
'instacart_2017_05_01',
name + '.csv')
return pandas.read_csv(path, encoding='utf8')
# Published order data was split into irrelevant prior/train
# sets, so we will combine them to re-purpose all the data.
orders = read_csv('order_products__prior')
orders = orders.append(read_csv('order_products__train'))
# count how many times each product_id was ordered
data = orders.groupby('product_id').size().to_frame('sales')
# add product names and department ids to ordered product ids
products = read_csv('products').set_index('product_id')
data = data.join(products)
# add department names to the department ids
departments = read_csv('departments').set_index('department_id')
data = data.set_index('department_id').join(departments)
# Only return the columns we need for training
data = data.reset_index()
return data[['product_name', 'department', 'sales']]
接下来,我们需要为每列指定一个编码器。计算机科学家可能会认为编码器是有效机器学习的一种类型注释的形式。有些产品的名字长得可笑,所以我们会将它们截断为前15个单词。
# my_app/pipelines/product_popularity.py part 2
def get_encoders(self):
return (
# An encoder to tokenize product names into max 15 tokens that
# occur in the corpus at least 10 times. We also want the
# estimator to spend 5x as many resources on name vs department
# since there are so many more words in english than there are
# grocery store departments.
Token('product_name', sequence_length=15, minimum_occurrences=10, embed_scale=5),
# An encoder to translate department names into unique
# identifiers that occur at least 50 times
Unique('department', minimum_occurrences=50)
)
def get_output_encoder(self):
# Sales is floating point which we could Pass encode directly to the
# estimator, but Norm will bring it to small values around 0,
# which are more amenable to deep learning.
return Norm('sales')
这是Pipeline的问题。我们的开始估计器将是
lore.estimators.keras.Regression 的一个简单的子类,它实现一个值典型的带有合理默认的深度学习架构。# my_app/estimators/product_popularity.py
import lore.estimators.keras
class Keras(lore.estimators.keras.Regression):
pass
最后,我们的模型通过将它们委托给估计器,指定了深度学习体系结构的高级属性,并从我们创建的Pipeline中提取数据。
# my_app/models/product_popularity.py
import lore.models.keras
import my_app.pipelines.product_popularity
import my_app.estimators.product_popularity
class Keras(lore.models.keras.Base):
def __init__(self, pipeline=None, estimator=None):
super(Keras, self).__init__(
my_app.pipelines.product_popularity.Holdout(),
my_app.estimators.product_popularity.Keras(
hidden_layers=2,
embed_size=4,
hidden_width=256,
batch_size=1024,
sequence_embedding='lstm',
)
)
5)测试代码
当你生成过渡支架时,会自动为该模型创建一个烟雾测试。第一次运行需要一些时间来下载200MB的测试数据集。一个好的做法是减少./tests/data中的缓存的文件,并在你的repo中检查它们,以删除网络依赖项并加速测试运行。
$ lore test tests.unit.test_product_popularity
6) 训练模型
训练一个模型将在./data中缓存数据,并在 ./models中保存文件。
$ lore fit my_app.models.product_popularity.Keras --test --score
跟踪第二个终端的日志,看看Lore是如何利用它的。
$ tail -f logs/development.log
尝试添加更多的隐藏层,看看这是否有助于你的模型的
score。你可以编辑模型文件,或者通过命令行调用来直接传递属性,例如: --hidden_layers=5。使用缓存的数据集大约需要30秒。
检查模型的特性
你可以在lore环境中运行jupyter notebooks。Lore将会安装一个定制的jupyter内核,它将会为你的lore notebook和lore console,引用你的应用程序的虚拟环境。
$ lore notebook
浏览到
notebooks/product_popularity/features.ipynb 并且“运行所有”可以看到模型最后一个拟合的一些可视化效果。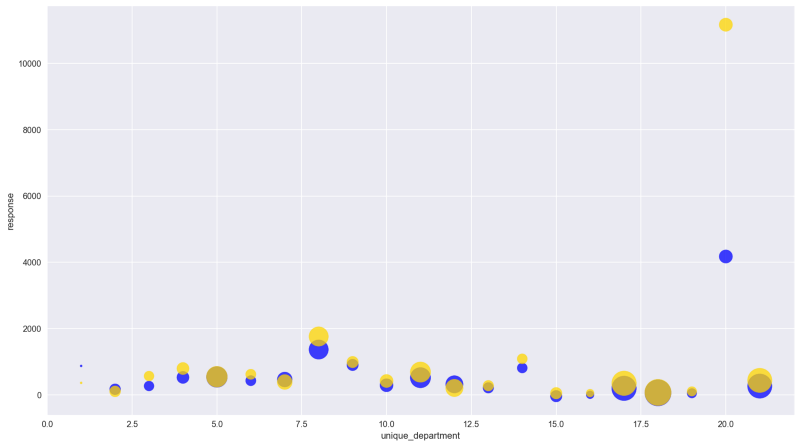
“生产”部门编码为“20”
你可以看到模型的预测(蓝色)是如何跟踪测试集(金色)的,并对特定的特征进行聚合。在这种情况下,有21个部门有相当好的重叠,除了“生产”,模型没有完全解释异常值是多少。
你还可以看到笔记本电脑上运行笔记本产生的深度学习架构notebooks/product_popularity/architecture.ipynb。

媒体不支持svg,所以这是不可读的,但notebooks可以
在左边的LSTM中,有15个标记化的部分,而department name被输入到右侧的嵌入中,然后通过隐藏的层。
服务你的模型
Lore应用程序可以作为一个HTTP API在本地运行。默认情况下,模型将通过HTTP GET端点公开他们的“预测”方法。
$ lore server &
$ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Banana&department=produce"
$ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Organic%20Banana&department=produce"
$ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Green%20Banana&department=produce"
$ curl "http://localhost:5000/product_popularity.Keras/predict.json?product_name=Brown%20Banana&department=produce"
我的结果表明,将“有机”添加到“香蕉”后,我们的“农产品”部门将销售两倍以上的水果。“绿色香蕉”预计会比“褐色香蕉”卖得更差。
7)部署到生产
Lore应用程序可以通过任何支持Heroku buildpack的基础架构进行部署。Buildpacks将runtime.txt和requirements.txt中的规范安装部署在容器中。如果你想在云中进行横向扩展,你可以按照heroku的入门指南进行操作。
你可以看到每次在i
./models/my_app.models.product_popularity/Keras/中发布lore fit 命令的结果。该目录和./data/默认位于.gitignore中,因为你的代码始终可以重新创建它们。一个简单的部署策略是检查将要发布的模型版本。$ git init .
$ git add .
$ git add -f models/my_app.models.product_popularity/Keras/1 # or your preferred fitting number to deploy
$ git commit -m "My first lore app!"
Heroku可以很容易地发布一个应用程序。查看他们的入门指南。
- 指南地址:https://devcenter.heroku.com/articles/getting-started-with-python#introduction
以下是TLDR:
$ heroku login
$ heroku create
$ heroku config:set LORE_PROJECT=my_app
$ heroku config:set LORE_ENV=production
$ git push heroku master
$ heroku open
$ curl “`heroku info -s | grep web_url | cut -d= -f2`product_popularity.Keras/predict.json?product_name=Banana&department=produce”
现在你可以用你的heroku应用程序名称替换http://localhost:5000/,然后你可以从任何地方访问你的预测!
*或者,你可以和我的heroku应用互动。
- 应用地址:https://myloreapp.herokuapp.com/product_popularity.Keras/predict.json?product_name=Banana&department=produce
下一个步骤
我们认为0.5版本是与社区一起构建为1.0的坚实基础。修补程序版本将避免重大更改,但次要版本可能会根据社区需求更改功能。我们将弃用并发布警告,以保持现有应用程序的清晰升级路径。
下面是我们想在1.0之前添加的一些特性:
- 用于模型/估计器/特性分析的可视化Web UI;
- 在模型训练和数据处理期间集成分布式计算支持,即job queuing;
- 测试不良数据或体系结构,而不仅仅是损坏的代码;
- 更多的文档,估计器,编码器和变压器;
- 完整的Windows支持。









