











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






为回归问题选择最佳机器学习算法
2018年03月08日 由 xiaoshan.xiang 发表
746090
0
任何类型的机器学习(ML)问题,都有许多不同的算法可供选择。在机器学习中,有一种叫做“无免费午餐(No Free Lunch)”的定理,意思是没有任何一种ML算法对所有问题都是最适合的。不同ML算法的性能在很大程度上取决于数据的大小和结构。因此,除非我们直接通过简单的试验和错误来测试我们的算法,否则我们往往不清楚是否正确选择了算法。
但是,我们需要了解每个ML算法的优点和缺点。尽管一种算法并不总是优于另一种算法,但是我们可以通过了解每种算法的一些特征来快速选择正确的算法并调整超参数。我们将研究一些关于回归问题的比较重要的机器学习算法,并根据它们的优缺点来决定使用它们的准则。
缺点:
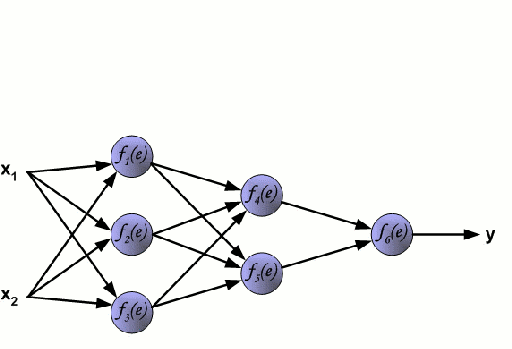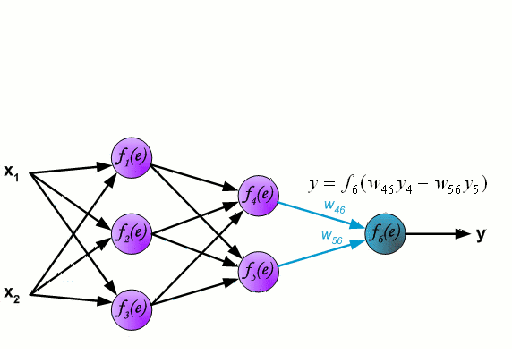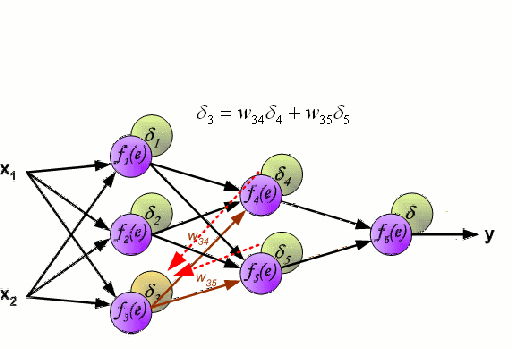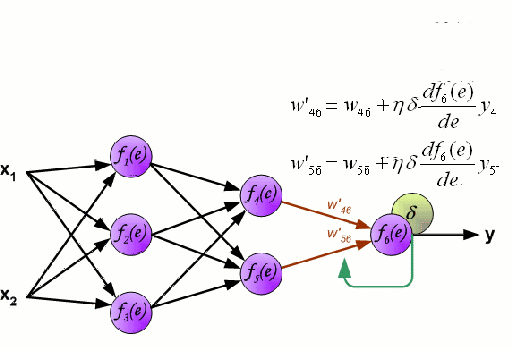
神经网络由一组相互连接的节点(称为神经元)组成。来自数据的输入特征变量作为多变量线性组合被传递给这些神经元,其中乘以每个特征变量的值被称为权重。然后将非线性应用于该线性组合,使神经网络能够建模复杂的非线性关系。神经网络可以有多层,其中一层的输出以相同的方式传递给下一层。在输出端,通常不会施加非线性。神经网络使用随机梯度下降(SGD)和反向传播算法(均显示在上面的GIF中)进行训练。
优点:
缺点:
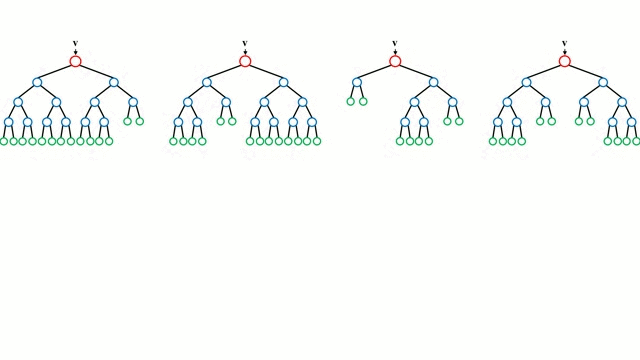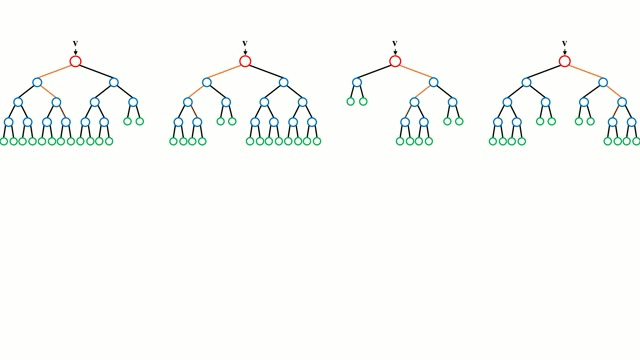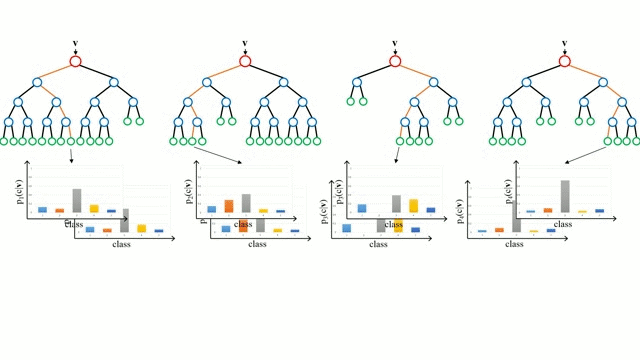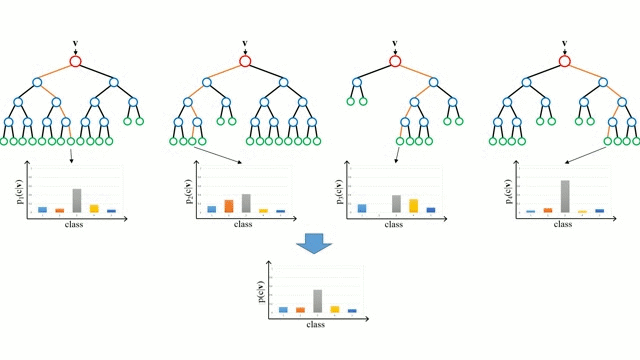
从基本情况开始,决策树是一种直观的模型,该模型通过遍历树的分支与节点的决策选择下一个分支下降。树归纳法是将一组训练实例作为输入,确定哪些属性最适合分割,分割数据集,并在产生的分割数据集上重复出现,直到所有训练实例被分类。在构建树时,目标是在可能创建的最纯粹的子节点属性上进行分割,为了对数据集中的所有实例进行分类,需要对其进行最少的分割。纯度是通过信息增益的概念来衡量的,这涉及到需要对一个未被发现的实例进行多少了解,才能使其正确分类。在实践中,这通过比较熵或者是将当前数据集分区的单个实例进行分类所需的信息量,如果当前的数据集分区要在给定的属性上进一步划分,则需要对单个实例进行分类。
随机森林只是决策树的集合。输入向量通过多个决策树运行。对于回归,所有树的输出值是平均的;对于分类,使用投票方案来确定最终的类别。
优点:
缺点:
但是,我们需要了解每个ML算法的优点和缺点。尽管一种算法并不总是优于另一种算法,但是我们可以通过了解每种算法的一些特征来快速选择正确的算法并调整超参数。我们将研究一些关于回归问题的比较重要的机器学习算法,并根据它们的优缺点来决定使用它们的准则。
线性和多项式回归
线性回归
简单来说,单变量线性回归是一种利用线性模型(如一条线)对单个输入自变量(特征变量)和输出因变量之间的关系进行建模的技术。比较一般的情况是多变量线性回归,为多个独立输入变量(特征变量)和一个输出因变量之间的关系创建模型。模型保持线性,因为输出是输入变量的线性组合。
第三个最常见的例子叫做多项式回归模型,该模型现在变成了特征变量(如指数变量,正弦和余弦等)的非线性组合。但这需要知道数据与输出的关系。回归模型可以使用随机梯度下降(SGD)进行训练。
优点:
- 当建模关系不是非常复杂并且没有太多数据时,建模快速且特别有用。
- 线性回归很容易理解,这对商业决策可能非常有价值。
缺点:
- 对于非线性数据,多项式回归对于设计来说可能相当具有挑战性,因为必须具有关于数据结构和特征变量之间关系的一些信息。
- 由于上述原因,当涉及到高度复杂的数据时,这些模型不如其他模型。
神经网络
神经网络
神经网络由一组相互连接的节点(称为神经元)组成。来自数据的输入特征变量作为多变量线性组合被传递给这些神经元,其中乘以每个特征变量的值被称为权重。然后将非线性应用于该线性组合,使神经网络能够建模复杂的非线性关系。神经网络可以有多层,其中一层的输出以相同的方式传递给下一层。在输出端,通常不会施加非线性。神经网络使用随机梯度下降(SGD)和反向传播算法(均显示在上面的GIF中)进行训练。
优点:
- 由于神经网络可以具有许多非线性层(从而具有参数),所以它们在建模非常复杂的非线性关系时非常有效。
- 我们通常不必担心神经网络中的数据结构,它在学习几乎任何类型的特征变量关系时都非常灵活。
- 研究一直表明,仅仅为神经网络提供更多的训练数据,无论是全新的还是增加原始数据集,都会使网络性能受益。
缺点:
- 由于这些模型的复杂性,它们不容易解释和理解。
- 对于训练来说,它们可能非常具有挑战性和计算密集性,需要仔细调整超参数并设置学习速率时间表。
- 它们需要大量数据才能实现高性能,并且在“小数据”情况下通常会受到其他ML算法的影响。
回归树和随机森林
随机森林
从基本情况开始,决策树是一种直观的模型,该模型通过遍历树的分支与节点的决策选择下一个分支下降。树归纳法是将一组训练实例作为输入,确定哪些属性最适合分割,分割数据集,并在产生的分割数据集上重复出现,直到所有训练实例被分类。在构建树时,目标是在可能创建的最纯粹的子节点属性上进行分割,为了对数据集中的所有实例进行分类,需要对其进行最少的分割。纯度是通过信息增益的概念来衡量的,这涉及到需要对一个未被发现的实例进行多少了解,才能使其正确分类。在实践中,这通过比较熵或者是将当前数据集分区的单个实例进行分类所需的信息量,如果当前的数据集分区要在给定的属性上进一步划分,则需要对单个实例进行分类。
随机森林只是决策树的集合。输入向量通过多个决策树运行。对于回归,所有树的输出值是平均的;对于分类,使用投票方案来确定最终的类别。
优点:
- 擅长学习复杂的高度非线性关系。它们通常可以实现相当高的性能,优于多项式回归,并且性能通常与神经网络的相当。
- 非常容易解释和理解。虽然最终的训练模型可以学习复杂的关系,但是在训练过程中建立的决策边界很容易理解,也很实用。
缺点:
- 由于训练决策树的原因,他们可能容易出现严重的过度拟合。完整的决策树模型可能过于复杂并且包含不必要的结构。虽然有时可以通过适当的结构树修剪和较大的随机森林集合来缓解这种情况。
- 使用较大的随机森林集合来实现更高的性能会带来速度变慢和需要更多内存的缺点。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消