











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






一文带你了解深度学习中的视觉问答(VQA)技术
2018年03月07日 由 yining 发表
818316
0
本文将带你了解深度学习中的视觉问答(VQA)技术。
从某些角度上来看,建立一个能够回答自然语言问题的系统一直被认为是一个非常有野心的目标。根据下面给出的图像,想象一个可以回答这些问题的系统:

那么,图像中有多少球员呢? 我们数了一下,总共有11名球员。因为我们足够聪明,在数的过程中知道将裁判排除。
尽管作为人类,我们通常可以在没有重大不便的情况下完成这项任务,但系统并非如此。通常来说,一些具备完成人类任务的系统似乎总被认为是在科幻小说中才能出现的,而不会马上想到人工智能(AI)。然而,随着深度学习(DL)的出现,我们在视觉问答(VQA)方面已经取得了巨大的研究进展,这样的系统能够回答这些问题,并带来了有希望的结果。
在本文中,我将简要地介绍VQA中用到的一些数据集、方法和评估指标,以及如何将这个具有挑战性的任务应用到实际生活用例中。
自然语言处理问答系统通常会:
在分析了问题之后,系统构建了某种查询,并依赖于知识库来获得答案。这绝非一件容易的事,因为在美国至少有22个城市叫“巴黎(Paris)”。
VQA的主要区别在于,搜索和推理部分必须在图像的内容上执行。因此,为了回答在某处是否有人类这样的问题,这个系统必须能够探测到物体。如果想要回答是否下雨这样的问题,系统就需要对一个场景进行分类。回到我们之前提到的问题,要回答出哪个球员在踢球,那么常识性推理以及可能的知识推理是必要的。这些任务中许多(包括对象识别、对象检测、场景分类等)已经在计算机视觉(CV)领域得到了解决,在过去的几年中取得了令人瞩目的成果。
因此,正如我们所看到的,一个好的VQA系统必须能够解决典型的自然语言处理和计算机视觉任务的问题,以及关于图像内容的推理。这显然是一个多学科的人工智能研究问题,涉及到计算机视觉、自然语言处理和知识表示(KR)等领域。
VQA领域非常复杂,一个好的数据集应该足够大,大到能够在真实的场景中捕捉问题和图像内容的各种可能性。许多数据集中的图像都来自微软的COCO数据集,这个数据集包含了32.8万张图像,91个对象类型,250万个标记的实例。这些对象可以很容易被一个4岁的儿童识别。

COCO数据集可以简化和加速构建VQA数据集的过程。然而,这并不是一件容易的事。例如,收集各种各样的、方便的、不引起歧义的问题是一个巨大的挑战。除了多样性和精度问题之外,良好的数据集还必须避免可能被利用的偏见。例如,给定一个只有“是/不是”答案的数据集,其中90%的答案是“是”,一个平凡的、最常见的分类策略将获得90%的精度,而不需要用VQA来解决任何问题。
为了深入了解VQA的复杂性,让我们看看一些最重要的数据集。
DAQUAR数据集
第一个重要的VQA数据集是DAQUAR((The DAtaset for QUestion Answering on Real-world images))数据集。它包含6794个用于训练和5674个用于测试的question-answer pairs,基于NYU-Depth V2数据集中的图像。这意味着平均每幅图像有9个pairs。
虽然这个数据集是一项伟大的创举,但NYU的数据集只包含室内场景。关于在室外的问题就很难回答出来。对人类的评估,NYU数据集显示了50.2%的准确率。

DAQUAR数据集的另一个缺点是它的大小使它不适合用于训练和评估复杂模型。
COCO-QA数据集
COCO-QA数据集比DAQUAR大得多。它包含123,287张来自可可数据集的图片,78,736个训练和38,948个测试question-answer pairs。为了创建如此大量的question-answer pairs,一篇叫做《对图像问答探索模型和数据》(Exploring Models and Data for Image Question Answering)的论文的作者使用了自然语言处理算法来自动从COCO图像标注(image caption)中生成它们。例如,对于一个给定的标注,比如“房间里的两把椅子”,它们会产生一个如“有多少椅子?”的问题,必须注意的是,所有的答案都是一个单一的词。
虽然这种做法很聪明,但这里存在的问题是,这些问题都具有自然语言处理的限制,所以它们有时会被奇怪地表述出来,或者有语法错误。在某些情况下,它们的表达是难以理解的:

另一个不便之处是,数据集只有四种问题,分布也不均匀:对象(69.84%)、颜色(16.59%)、计数(7.47%)和位置(6.10%)。
VQA数据集
与其他数据集相比,VQA数据集比较大。除了来自COCO数据集的204,721张图片外,它还包含5万个抽象的卡通图片。每个图像对应三个问题,每个问题有十个答案。由此可以得出VQA数据集有超过76万个问题,大约有1000万个答案。为了实现这一目标,亚马逊土耳其机器人((Amazon Mechanical Turk))的一个团队提出了问题,另一个团队则给出了答案。
一个有趣的观点是,对于测试,他们提出了两种类型的回答模式:开放式的和多项选择的。对于第一种模式,他们提出以下的度量标准:
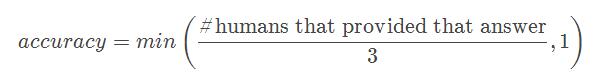
这意味着,如果至少有3个人提供了准确的答案,那么答案就被认为是100%准确的。对于多项选择模式,他们会创建18个候选答案(正确和不正确):
尽管在数据集的设计中采取了预防措施(例如,包含普遍的答案使得从一组答案中推断出问题的类型更加困难),我们可以观察到一些问题。也许最值得注意的问题的是有些问题太主观了,没有一个正确的答案。有时候,就像下面的图片一样,一个最有可能的答案是可以给出的。

我们不能保证上图这个人有孩子,但毫无疑问,这是最有可能的答案。
最后要说的是,一个主要的缺点是我们可以称之为琐碎的问题,这些问题通常不需要图像就能得到一个好的(或可能的)答案。例如:“狗有几条腿?”或者“这些树是什么颜色的?”虽然不总是正确的,但4和绿色是最常见和最明显的答案。
当前的方法
一般来说,我们可以在VQA中概述这些方法:
对于文本特征,可以使用诸如“词袋模型(BOW)”或“LSTM”编码器之类的技术。在结合图像特征(image features)的情况下,在ImageNet上预先训练的卷积神经网络(CNN)是最常见的选择。对于问题的生成,方法通常将问题建模为分类任务。
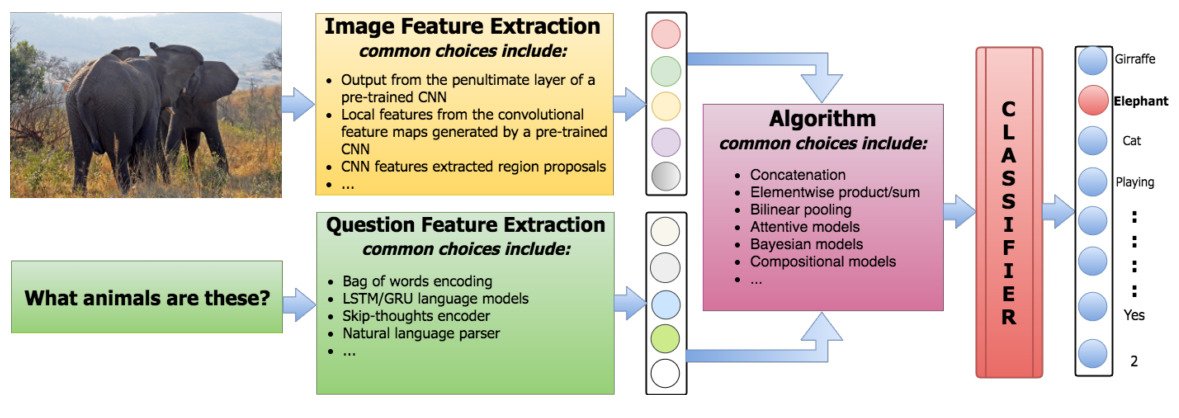
因此,几种方法的主要区别在于它们如何结合文本和图像特征。例如,它们可以简单地将它们组合起来使用连接,然后馈送一个线性分类器。或者它们可以使用贝叶斯模型来推断出问题的特征分布,图像和答案之间的潜在关系。
基线
对于许多分类问题,一个看似微不足道的基线总是给出最常见的问题答案。另一个微不足道的基线则取一个随机的答案。例如,安托尔等人在2016的一篇研究中显示,总是从VQA数据集中选择最普通的答案(答案是“是”),结果得到了29.72%的准确率。除了这可能与不期望的数据集偏差有关,这样的结果说明了拥有良好基线的重要性:它们决定了可接受的最低性能水平,并且还可以提示关于任务和/或数据集的内在复杂性。
一个更复杂的基线,在VQA中广泛使用,包括训练一个线性分类器或一个多层感知器,使用向量将一个特征组合作为输入。这个组合可以是一个简单的连接,或者是一个特征的element wise sum或element wise product。
例如,前面提到的工作经验有两个模型:
1. 一个多层感知器(MLP)神经网络分类器,它有2个隐藏层和1000个隐藏单元(dropout 0.5),每一层都有tanh非线性函数。
2. 一个LSTM模型后面是一个softmax层,用来来生成答案。
在第一种情况下,对于文本特征,它们使用了一个词袋模型的方法,各在问题中和标注中使用了1000个最受欢迎的词来计算它们。对于图像特征,它们使用了VGGNet的最后一个隐藏层。对于LSTM模型,它们使用一种叫做独热编码的方式来回答问题,同样的图像特征与上面的相同,然后是一个线性变换,将图像的特征转换为1024大小的维度,以匹配问题的LSTM编码。问题和图像编码通过element-wise-multiplication进行组合。
这些基线的性能非常有趣。例如,如果这些模型只对文本特征进行训练,那么精确度是48.09%,而如果它们只接受视觉特征的训练,精确度则下降到28.13%。它们当中最好的模型是LSTM,在这两种特性上都进行了训练,准确率达到了53.74%。一般来说,多项选择的结果比开放式的结果要好,而且正如预期的那样,所有的方法都比人类的表现差得多。
这个框架的许多变体可以被执行,从而能够获得不同的基线。
基于注意力(attention)集中的方法
基于注意力集中的方法的目标是将算法的焦点集中在输入的最相关的部分上。例如,如果问题是“球是什么颜色的?”那么需要更加集中球所包含的图像区域。同样,在问题中,需要集中“颜色”和“球”这两个词,因为它们比其他的词更具信息性。
VQA中最常见的选择是利用空间注意(spatial attention)的办法来生成特定区域的特征,从而用来训练卷积神经网络。有两种常用的方法来获得图像的空间区域(spatial region)。首先,在图像上投射一个网格。
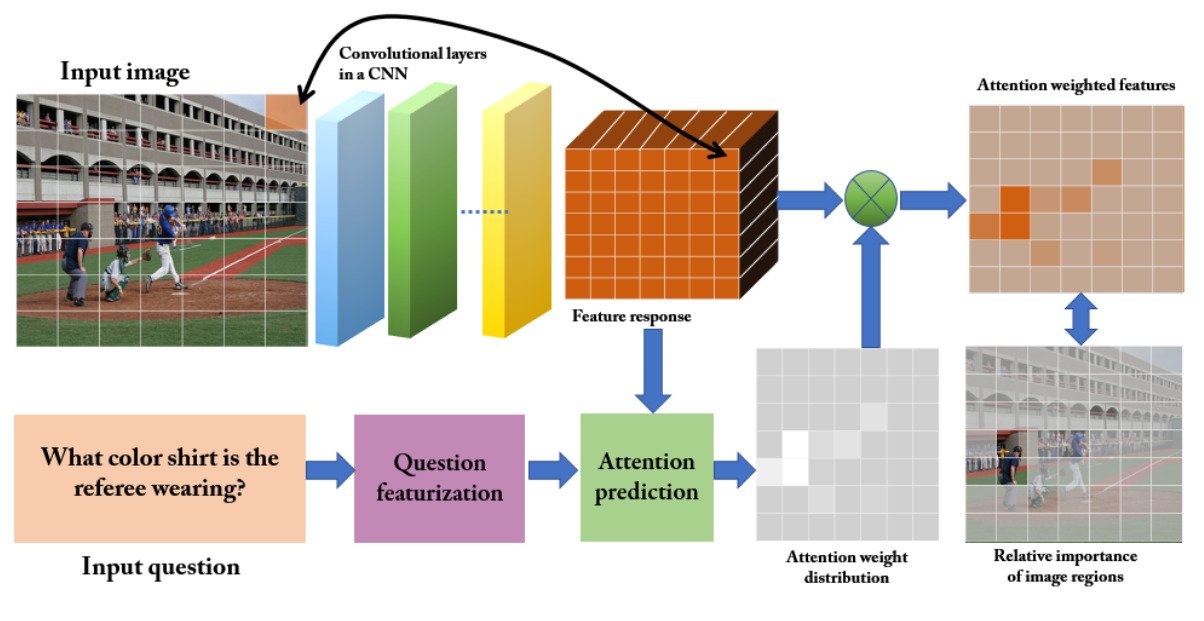
在网格被应用之后,每个区域的相关性由特定的问题决定。另一种方法是提出自动生成的边界框。

在给定的区域中,我们可以使用这个问题来确定每个特征的相关性,并且只选择那些有必要回答问题的部分。这些仅仅是将注意力集中到VQA系统上的两种技术,并且在文献中可以找到更多的技术。
贝叶斯方法
贝叶斯方法的思想是将问题和图像特征共同出现的统计数据建模为一种推断问题和图像之间关系的方法。例如,在Kafle和Kanan在2016年写的一篇叫做《对视觉问答的答案类型做预测》(Answer-Type Prediction for Visual Question Answering )的论文中,作者们根据问题的特征和答案的类型,对图像特征的概率进行建模。他们这样做是因为他们观察到,在给定一个问题的情况下,答案的类型经常可以被预测。例如,“在图像中有多少玩家?”这是一个“多少”的问题,需要一个数字作为答案。为了对概率进行建模,他们将贝叶斯模型与一种辨别模型(discriminative model)相结合。对于这些特征,他们对图像使用ResNet模型,并且对文本使用skip-thought vectors模型。
评估指标
任何系统的性能依赖于它所评估的度量标准。在VQA中,我们可以使用的最直接的度量标准是精确性。虽然对于多项选择式的答案系统来说,这是一个合理的选择,但当涉及到开放式的答案时,它往往会受到惩罚。比如说,如果问题是“什么动物出现在图像中?”这张图片显示的是狗、猫和兔子,那么回答“猫和狗”这样的答案是不正确的吗?
这些都是非常复杂的问题,必须加以解决,以便尽可能准确地评估不同的方法。
手动评估
另一种处理评估阶段的方法是使用人类审判官来评估答案。当然,这是一种极其昂贵的方法。此外,必须建立明确的准则,以便审判官能够正确地评估答案。某些类型的训练应该被预知,预知的内容主要针对于评估的质量和审判官之间的协议。
现实生活中VQA应用
VQA有许多潜在的应用程序。最直接的可能是那些帮助盲人和视觉受损用户的应用。VQA系统可以在网络或任何社交媒体上提供关于图像的信息。另一个明显的应用是将VQA集成到图像检索系统中。这可能会对社交媒体或电子商务产生巨大影响。同时,VQA也可以用于教育或娱乐用途。
VQA是一个最近才衍生的领域,由于深度学习技术正在显著改善自然语言处理和计算机视觉的结果,我们可以预计VQA在未来几年将会变得越来越准确。
从某些角度上来看,建立一个能够回答自然语言问题的系统一直被认为是一个非常有野心的目标。根据下面给出的图像,想象一个可以回答这些问题的系统:
- 图像中有什么?
- 图像中有人类吗?
- 什么运动正在进行?
- 谁在踢球?
- 在图像中有多少球员?
- 参赛者都有谁?
- 在下雨吗?
阿根廷对战英格兰(1986)
那么,图像中有多少球员呢? 我们数了一下,总共有11名球员。因为我们足够聪明,在数的过程中知道将裁判排除。
尽管作为人类,我们通常可以在没有重大不便的情况下完成这项任务,但系统并非如此。通常来说,一些具备完成人类任务的系统似乎总被认为是在科幻小说中才能出现的,而不会马上想到人工智能(AI)。然而,随着深度学习(DL)的出现,我们在视觉问答(VQA)方面已经取得了巨大的研究进展,这样的系统能够回答这些问题,并带来了有希望的结果。
在本文中,我将简要地介绍VQA中用到的一些数据集、方法和评估指标,以及如何将这个具有挑战性的任务应用到实际生活用例中。
一个多学科领域的问题
一般来说,VQA系统需要将图片和问题作为输入,结合这两部分信息,产生一条人类语言作为输出。针对一张特定的图片,如果想要机器以自然语言处理(NLP)来回答关于该图片的某一个特定问题,我们需要让机器对图片的内容、问题的含义和意图以及相关的常识有一定的理解。就其本性而言,这是一个多学科研究问题。举个例子,关于前面提到的图像的问题,我们需要自然语言处理至少有两个原因:理解这个问题并产生答案。这些都是在基于文本的问答中的常见问题,在自然语言处理中是一个很好的研究问题。看下面的这个句子:
在巴黎总共有多少座桥?
自然语言处理问答系统通常会:
- 对问题进行分类:这是一个“有多少”的问题,因此回答必须是一个数字。
- 提取的计数对象:桥。
- 提取必须执行计数的上下文:在本例中是巴黎这座城市。
在分析了问题之后,系统构建了某种查询,并依赖于知识库来获得答案。这绝非一件容易的事,因为在美国至少有22个城市叫“巴黎(Paris)”。
VQA的主要区别在于,搜索和推理部分必须在图像的内容上执行。因此,为了回答在某处是否有人类这样的问题,这个系统必须能够探测到物体。如果想要回答是否下雨这样的问题,系统就需要对一个场景进行分类。回到我们之前提到的问题,要回答出哪个球员在踢球,那么常识性推理以及可能的知识推理是必要的。这些任务中许多(包括对象识别、对象检测、场景分类等)已经在计算机视觉(CV)领域得到了解决,在过去的几年中取得了令人瞩目的成果。
因此,正如我们所看到的,一个好的VQA系统必须能够解决典型的自然语言处理和计算机视觉任务的问题,以及关于图像内容的推理。这显然是一个多学科的人工智能研究问题,涉及到计算机视觉、自然语言处理和知识表示(KR)等领域。
可用的数据集
与自然语言处理或计算机视觉中的许多问题一样,例如机器翻译、图像标注(Image Captioning)或命名实体识别(Named Entities Recognition),数据集的可用性是一个关键问题。它们允许在结合良好定义的度量标准(参见下面的“评估指标”一节)的情况下,以比较不同的方法将它们与人类决策进行比较,并以绝对的方式度量它们的执行情况,也就是说,确定最先进的经验限制。
VQA领域非常复杂,一个好的数据集应该足够大,大到能够在真实的场景中捕捉问题和图像内容的各种可能性。许多数据集中的图像都来自微软的COCO数据集,这个数据集包含了32.8万张图像,91个对象类型,250万个标记的实例。这些对象可以很容易被一个4岁的儿童识别。
- COCO数据集:http://cocodataset.org/#home
来自COCO数据集的注释图像示例
COCO数据集可以简化和加速构建VQA数据集的过程。然而,这并不是一件容易的事。例如,收集各种各样的、方便的、不引起歧义的问题是一个巨大的挑战。除了多样性和精度问题之外,良好的数据集还必须避免可能被利用的偏见。例如,给定一个只有“是/不是”答案的数据集,其中90%的答案是“是”,一个平凡的、最常见的分类策略将获得90%的精度,而不需要用VQA来解决任何问题。
为了深入了解VQA的复杂性,让我们看看一些最重要的数据集。
DAQUAR数据集
第一个重要的VQA数据集是DAQUAR((The DAtaset for QUestion Answering on Real-world images))数据集。它包含6794个用于训练和5674个用于测试的question-answer pairs,基于NYU-Depth V2数据集中的图像。这意味着平均每幅图像有9个pairs。
- DAQUAR数据集:https://www.mpi-inf.mpg.de/departments/computer-vision-and-multimodal-computing/research/vision-and-language/visual-turing-challenge/
- NYU-Depth V2数据集:https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
虽然这个数据集是一项伟大的创举,但NYU的数据集只包含室内场景。关于在室外的问题就很难回答出来。对人类的评估,NYU数据集显示了50.2%的准确率。
对图像中人类生成的question-answer pairs的例子
DAQUAR数据集的另一个缺点是它的大小使它不适合用于训练和评估复杂模型。
COCO-QA数据集
COCO-QA数据集比DAQUAR大得多。它包含123,287张来自可可数据集的图片,78,736个训练和38,948个测试question-answer pairs。为了创建如此大量的question-answer pairs,一篇叫做《对图像问答探索模型和数据》(Exploring Models and Data for Image Question Answering)的论文的作者使用了自然语言处理算法来自动从COCO图像标注(image caption)中生成它们。例如,对于一个给定的标注,比如“房间里的两把椅子”,它们会产生一个如“有多少椅子?”的问题,必须注意的是,所有的答案都是一个单一的词。
虽然这种做法很聪明,但这里存在的问题是,这些问题都具有自然语言处理的限制,所以它们有时会被奇怪地表述出来,或者有语法错误。在某些情况下,它们的表达是难以理解的:
在这个问题中语法错误的例子
另一个不便之处是,数据集只有四种问题,分布也不均匀:对象(69.84%)、颜色(16.59%)、计数(7.47%)和位置(6.10%)。
VQA数据集
与其他数据集相比,VQA数据集比较大。除了来自COCO数据集的204,721张图片外,它还包含5万个抽象的卡通图片。每个图像对应三个问题,每个问题有十个答案。由此可以得出VQA数据集有超过76万个问题,大约有1000万个答案。为了实现这一目标,亚马逊土耳其机器人((Amazon Mechanical Turk))的一个团队提出了问题,另一个团队则给出了答案。
一个有趣的观点是,对于测试,他们提出了两种类型的回答模式:开放式的和多项选择的。对于第一种模式,他们提出以下的度量标准:
这意味着,如果至少有3个人提供了准确的答案,那么答案就被认为是100%准确的。对于多项选择模式,他们会创建18个候选答案(正确和不正确):
- 正确答案:10个注释者(annotator)给出的最常见的答案。
- 貌似可信的答案:在不去看图像的情况下,从注释者那里收集三个答案。
- 最普遍的答案是:在数据集中最普遍的10个答案(如“是”、“不是”、“2”、“1”、“白色”、“3”、“红色”、“蓝色”、“4”、“绿色”等)。
- 随机答案:对其他问题随机选择正确答案。
尽管在数据集的设计中采取了预防措施(例如,包含普遍的答案使得从一组答案中推断出问题的类型更加困难),我们可以观察到一些问题。也许最值得注意的问题的是有些问题太主观了,没有一个正确的答案。有时候,就像下面的图片一样,一个最有可能的答案是可以给出的。
一个棘手的问题的例子。绿色是当看到图像时给出的答案。蓝色是那些不看图像随便给出答案的人。
我们不能保证上图这个人有孩子,但毫无疑问,这是最有可能的答案。
最后要说的是,一个主要的缺点是我们可以称之为琐碎的问题,这些问题通常不需要图像就能得到一个好的(或可能的)答案。例如:“狗有几条腿?”或者“这些树是什么颜色的?”虽然不总是正确的,但4和绿色是最常见和最明显的答案。
当前的方法
一般来说,我们可以在VQA中概述这些方法:
- 从问题中提取特征。
- 从图像中提取特征。
- 结合这些特征来生成一个答案。
对于文本特征,可以使用诸如“词袋模型(BOW)”或“LSTM”编码器之类的技术。在结合图像特征(image features)的情况下,在ImageNet上预先训练的卷积神经网络(CNN)是最常见的选择。对于问题的生成,方法通常将问题建模为分类任务。
VQA方法的简化方案
因此,几种方法的主要区别在于它们如何结合文本和图像特征。例如,它们可以简单地将它们组合起来使用连接,然后馈送一个线性分类器。或者它们可以使用贝叶斯模型来推断出问题的特征分布,图像和答案之间的潜在关系。
基线
对于许多分类问题,一个看似微不足道的基线总是给出最常见的问题答案。另一个微不足道的基线则取一个随机的答案。例如,安托尔等人在2016的一篇研究中显示,总是从VQA数据集中选择最普通的答案(答案是“是”),结果得到了29.72%的准确率。除了这可能与不期望的数据集偏差有关,这样的结果说明了拥有良好基线的重要性:它们决定了可接受的最低性能水平,并且还可以提示关于任务和/或数据集的内在复杂性。
一个更复杂的基线,在VQA中广泛使用,包括训练一个线性分类器或一个多层感知器,使用向量将一个特征组合作为输入。这个组合可以是一个简单的连接,或者是一个特征的element wise sum或element wise product。
例如,前面提到的工作经验有两个模型:
1. 一个多层感知器(MLP)神经网络分类器,它有2个隐藏层和1000个隐藏单元(dropout 0.5),每一层都有tanh非线性函数。
2. 一个LSTM模型后面是一个softmax层,用来来生成答案。
在第一种情况下,对于文本特征,它们使用了一个词袋模型的方法,各在问题中和标注中使用了1000个最受欢迎的词来计算它们。对于图像特征,它们使用了VGGNet的最后一个隐藏层。对于LSTM模型,它们使用一种叫做独热编码的方式来回答问题,同样的图像特征与上面的相同,然后是一个线性变换,将图像的特征转换为1024大小的维度,以匹配问题的LSTM编码。问题和图像编码通过element-wise-multiplication进行组合。
这些基线的性能非常有趣。例如,如果这些模型只对文本特征进行训练,那么精确度是48.09%,而如果它们只接受视觉特征的训练,精确度则下降到28.13%。它们当中最好的模型是LSTM,在这两种特性上都进行了训练,准确率达到了53.74%。一般来说,多项选择的结果比开放式的结果要好,而且正如预期的那样,所有的方法都比人类的表现差得多。
这个框架的许多变体可以被执行,从而能够获得不同的基线。
基于注意力(attention)集中的方法
基于注意力集中的方法的目标是将算法的焦点集中在输入的最相关的部分上。例如,如果问题是“球是什么颜色的?”那么需要更加集中球所包含的图像区域。同样,在问题中,需要集中“颜色”和“球”这两个词,因为它们比其他的词更具信息性。
VQA中最常见的选择是利用空间注意(spatial attention)的办法来生成特定区域的特征,从而用来训练卷积神经网络。有两种常用的方法来获得图像的空间区域(spatial region)。首先,在图像上投射一个网格。
使用一个网格将注意力集中到一起
在网格被应用之后,每个区域的相关性由特定的问题决定。另一种方法是提出自动生成的边界框。
使用边界框将重点区域包围的例子
在给定的区域中,我们可以使用这个问题来确定每个特征的相关性,并且只选择那些有必要回答问题的部分。这些仅仅是将注意力集中到VQA系统上的两种技术,并且在文献中可以找到更多的技术。
贝叶斯方法
贝叶斯方法的思想是将问题和图像特征共同出现的统计数据建模为一种推断问题和图像之间关系的方法。例如,在Kafle和Kanan在2016年写的一篇叫做《对视觉问答的答案类型做预测》(Answer-Type Prediction for Visual Question Answering )的论文中,作者们根据问题的特征和答案的类型,对图像特征的概率进行建模。他们这样做是因为他们观察到,在给定一个问题的情况下,答案的类型经常可以被预测。例如,“在图像中有多少玩家?”这是一个“多少”的问题,需要一个数字作为答案。为了对概率进行建模,他们将贝叶斯模型与一种辨别模型(discriminative model)相结合。对于这些特征,他们对图像使用ResNet模型,并且对文本使用skip-thought vectors模型。
评估指标
任何系统的性能依赖于它所评估的度量标准。在VQA中,我们可以使用的最直接的度量标准是精确性。虽然对于多项选择式的答案系统来说,这是一个合理的选择,但当涉及到开放式的答案时,它往往会受到惩罚。比如说,如果问题是“什么动物出现在图像中?”这张图片显示的是狗、猫和兔子,那么回答“猫和狗”这样的答案是不正确的吗?
这些都是非常复杂的问题,必须加以解决,以便尽可能准确地评估不同的方法。
手动评估
另一种处理评估阶段的方法是使用人类审判官来评估答案。当然,这是一种极其昂贵的方法。此外,必须建立明确的准则,以便审判官能够正确地评估答案。某些类型的训练应该被预知,预知的内容主要针对于评估的质量和审判官之间的协议。
现实生活中VQA应用
VQA有许多潜在的应用程序。最直接的可能是那些帮助盲人和视觉受损用户的应用。VQA系统可以在网络或任何社交媒体上提供关于图像的信息。另一个明显的应用是将VQA集成到图像检索系统中。这可能会对社交媒体或电子商务产生巨大影响。同时,VQA也可以用于教育或娱乐用途。
VQA是一个最近才衍生的领域,由于深度学习技术正在显著改善自然语言处理和计算机视觉的结果,我们可以预计VQA在未来几年将会变得越来越准确。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消