











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






还记得谷歌之前发现的两颗行星吗?今天谷歌对此披露了重要技术细节
2018年03月09日 由 yining 发表
576366
0
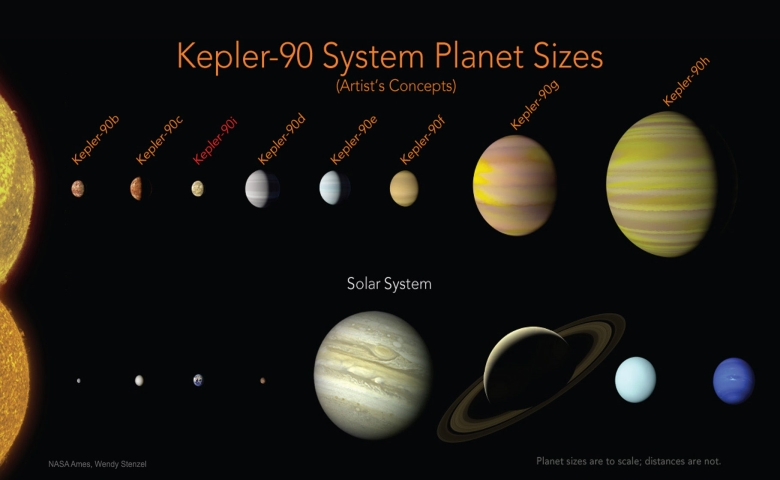
前一阵,谷歌通过训练一个神经网络来分析来自NASA的开普勒太空望远镜的数据,并准确地识别出最有希望的行星信号,从而发现了两颗新行星。虽然这只是对700颗恒星的初步分析,但谷歌认为这是一个成功的概念证明,它利用机器学习来发现系外行星,更普遍地说,这是利用机器学习在各种科学学科(如医疗保健、量子化学和核聚变研究)中取得有意义的进展的另一个例子。
今天,谷歌对此披露了重要的技术细节,以下是谷歌发布的相关信息:
今天,我们很高兴发布我们的代码来处理开普勒数据,从而训练我们的神经网络模型,并预测新的候选信号。我们希望这次发布将是为其他NASA任务开发类似模型的一个有用的起点,比如K2(开普勒的第二次任务)和即将到来的凌日系外行星探测卫星(Transiting Exoplanet Survey Satellite,简称TESS)任务。除了宣布我们的代码的发布,我们还希望借此机会让大家深入了解我们的模型是如何工作的。
行星搜寻引物
首先,让我们考虑一下开普勒望远镜收集的数据是如何被用来探测行星的存在的。下面的图称为光变曲线,它显示了恒星的亮度(根据开普勒的光度计所测量)。当一颗行星在恒星前面经过时,它会暂时挡住一些光线,使测量的亮度下降,然后在不久之后又增加,导致在光变曲线上会呈“U形”下降。
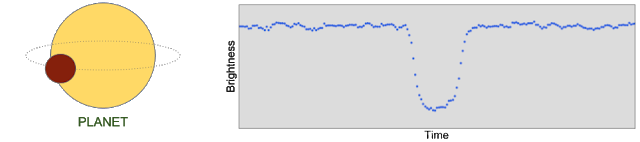
开普勒太空望远镜的一束光变曲线,以“U形”下降,表示一颗凌日系外行星。
然而,其他天文现象和仪器现象也会导致恒星的测量亮度降低,包括联星系统,星斑,宇宙线对开普勒的光度计和仪器噪音的影响。
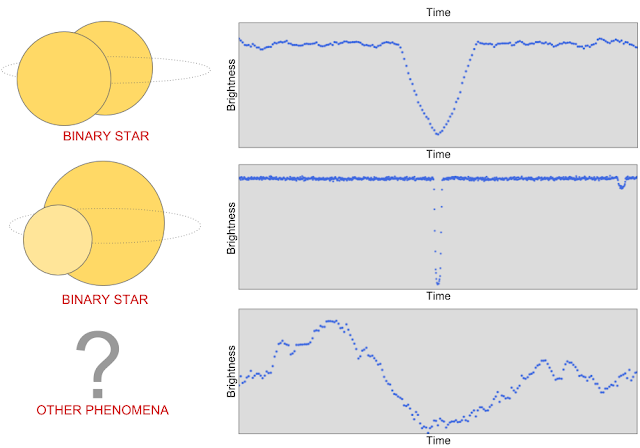
第一个光变曲线呈一个“V形”的图案,它告诉我们,在开普勒观测到的恒星前,有一个非常大的物体(即另一个恒星)穿过。第二个光变曲线包含两个亮度下降的地方,这表示一个联星系统有一个明亮的和一个暗淡的恒星:较大的下降是由在明亮的恒星前面经过的暗淡的恒星造成的,反之亦然。第三个光变曲线是许多其他非行星信号的一个例子,在这些信号中,恒星的亮度似乎会降低。
为了在开普勒数据中寻找行星,科学家们使用自动化软件(如开普勒数据处理管道)来探测可能由行星引起的信号,然后手动跟踪,以确定每个信号是否是行星。为了避免被更多的信号所干扰,科学家们在自动探测中应用了一个截止点:那些在一个固定阈值以上的信噪比(signal-to-noise ratio)被认为是值得进行后续分析的,而所有在阈值以下的探测都被丢弃。即使这样,探测的数量仍然是令人难以接受的:到目前为止,已经有超过3万个开普勒信号探测被人工检测,其中大约2500个已经被证实是真实的行星!
也许你在想:信噪比是否会导致一些真实的行星信号被错过?答案是,是的!然而,如果天文学家需要手动跟踪每一项探测,那么降低阈值是不值得的,因为当阈值降低时,错误判断探测的速度会迅速增加,而实际的行星探测也变得越来越稀有。然而,有一个诱人的动机:可能存在一些潜在的宜居行星,如地球,相对较小,围绕着相对较暗的恒星运行,可能隐藏在传统的探测阈值之下——也许还有隐藏在开普勒数据中未被发现的“宝石”!
机器学习的方法
谷歌大脑团队将机器学习应用于各种各样的数据,从人类基因组到草图,再到正式的数学逻辑。考虑到开普勒望远镜收集到的大量数据,我们想知道如果我们用机器学习来分析一些之前未被探索过的开普勒数据,我们会发现什么。为了找到答案,我们与德州大学奥斯汀分校的安德鲁·万德伯格合作,开发了一个神经网络,帮助行星搜索低信噪比探测。
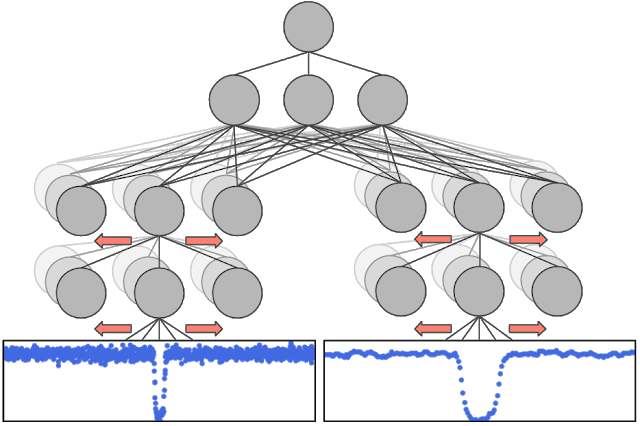
我们训练了一个卷积神经网络(CNN)来预测一个给定的开普勒信号是由行星引起的。我们选择卷积神经网络是因为它们在空间和/或时间结构方面非常成功,比如音频生成和图像分类。
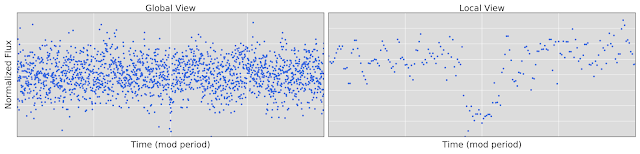
幸运的是,我们有3万个开普勒信号,这些信号已经被人类手动检测和分类了。我们使用了大约1.5万个这样的信号的子集,其中大约有3500个是经过验证的行星或者是强有力的行星候选,来训练我们的神经网络从而区分行星。输入到我们的网络是有着相同的光变曲线的两个不同视图:一个广角视图允许模型检查在光变曲线上的信号(如二次信号引起的联星),另一个放大视图使得模型能够仔细检测信号的形状(例如,区分形状相似的“U型”和“V型”信号)。
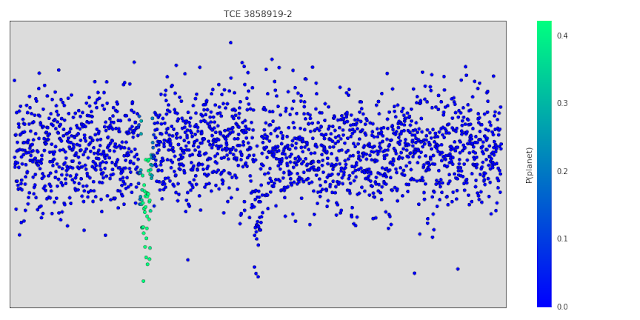
一旦我们训练了我们的模型,我们就会研究它在光变曲线上的特征,看看它们是否符合我们的期望。我们使用的一种技术(论文《可视化和理解卷积性网络》中提到)系统地对输入光变曲线的小区域进行封闭,以观察模型的输出是否发生了变化。对模型决策特别重要的区域如果被遮挡,将会改变输出预测,但对不重要区域的遮挡将不会产生显著影响。下图显示的是来自联星系统的光变曲线(我们的模型正确预测出不是行星)。在绿色中突出显示的点是当被遮挡时大多数改变模型输出预测的点,它们对应的是二进制系统的二次“下降”指示。当这些点被遮挡的时候,模型的输出预测一个行星的概率从0变成了的40%。因此,这些点是模型拒绝这条光变曲线的部分原因,但是模型也使用了其他的证明——例如,在中心放大后发现的下降主要是呈“V型”的,这也表明了它是一个联星系统。
- 论文《可视化和理解卷积性网络》:https://arxiv.org/abs/1311.2901
寻找新的行星
一旦我们对我们的模型预测有信心,那么我们可以通过在一个小类别的670颗恒星上寻找新行星来测试其有效性。我们选择这些恒星,因为它们已经有了多个轨道的行星,我们相信这些恒星可能宿主其他还没有被发现的行星。重要的是,我们允许我们的搜索,包括信号低于天文学家曾考虑过的信噪比阈值。正如预期的那样,我们的神经网络拒绝这些虚假的探测信号,但为数不多的、有前途的候选信号上升到顶部,包括我们两个新发现的行星:开普勒90i和开普勒80g。
找到你自己的行星
今天发布的代码可以帮助我们(重新)发现开普勒90i行星。第一步是训练模型遵循代码主页的指令。尽管这个过程需要一段时间从开普勒望远镜中下载和处理数据,但是一旦完成的话,它相对会加快训练模型的速度,使其预测新的信号。发现新的信号来显示模型的一种方法是使用一个叫做“箱最小二乘法(Box Least Squares,简称BLS)”的算法,其中搜索周期在亮处呈“箱型”下降(见下图)。BLS算法将探测“U型”行星信号,还有“V型”的联星信号和许多其他类型的错误信号来显示模型。有各种各样的免费BLS算法的软件实现,包括VARTOOLS和LcTools。
- BLS算法:https://arxiv.org/abs/astro-ph/0206099
- VARTOOLS:https://www.astro.princeton.edu/~jhartman/vartools.html
- LcTools:https://sites.google.com/a/lctools.net/lctools/lctools-product-description
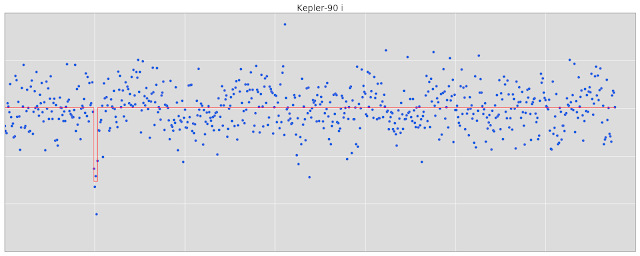
在由BLS算法探测到的开普勒90恒星的光变曲线中,一个低的信噪比探测。探测的时间为14.44912天,持续时间为2.70408个小时(0.11267天),从2009年1月1日(开普勒望远镜发射的那一年)的12点开始。
要运行这个我们已经训练过模型的探测信号,只需执行以下命令:
python predict.py --kepler_id=11442793 --period=14.44912 --t0=2.2
--duration=0.11267 --kepler_data_dir=$HOME/astronet/kepler
--output_image_file=$HOME/astronet/kepler-90i.png
--model_dir=$HOME/astronet/model
这个命令的输出预测等于0.94,这意味着这个模型是94%确定这个信号是一个真实的行星。当然,这只是发现和验证外行星的整个过程中的一个小步骤:模型的预测并不是一种证明或另一种方式。确认这一信号为真正的系外行星的过程需要一位专业天文学家进行大量的后续工作——请参阅我们的论文(如下)中6.3章节和6.4章节的完整细节。在这个特殊的例子中,我们的后续分析证实了这个信号是一个真正的系外行星,它就是开普勒90i!
我们的工作还远未完成。我们只在开普勒观测到的20万颗恒星中找到了670颗恒星——当我们把我们的技术转到整个数据集时,谁知道我们会发现什么。在此之前,我们想要对模型做一些改进。正如我们在论文中所讨论的那样,我们的模型还没有像一些成熟的计算机启发式那样,在排斥联星和仪器误报方面做得更好。所以我们正在努力改进我们的模型,并且现在它是开源的,我们希望其他人也能做同样的事!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消