











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






你真的适合学习AI吗?
2017年06月21日 由 yining 发表
995770
0

科技,尤其是软件开发,不仅仅是水平或垂直发展,而且也变得越来越专业。
因此,对于软件开发者来说学什么和学到怎样的程度是非常困难的。这篇文章会告诉你,作为一名初学者,哪种软件技术或是方法值得你花费时间去研究。在这之前,你需要问你自己以下几个问题:
- 现有的最令人激动的软件技术是什么?
- 它在我的职业轮廓中有多重要?
- 我怎样把它卖给我的客户?
- 它将怎样提高我的底线?
AI和机器学习是一个范式转移,并且将会变成IT史上最大的革命,但是目前仍有诸多挑战。
为什么使用人工智能?
有许多传统的编程不能解决的问题但机器学习却可以做到,数据科学家通过五个简单问题就可以将它们分类。Brandon Rohrer在他的文章中详细地描述了这五个问题是什么,这里做个总结:
- 哪种类别?– 分类(二进制,多类)
- 它奇怪吗?– 异常
- 预测有多少?– 回归
- 它怎样与数据结构相关?– 聚类,推荐系统
- 下一步做什么?– 强化学习
让我们详细地看一下。
- 分类
有时我们需要将事情分类,就像把患者分类为是否生病一样。
分类: 把数据库的记录映射到某一个特定的类别。
- 回归
另一个问题是预测问题的走向程度。例如:房子的价格取决于位置和面积,并且数值会连续变动。
回归:输出变量取连续值。
3. 异常
另一个算法类别被叫做异常探测器(亦称作孤立点检测)。它与一个预期模式或是在数据集的其他项目不符。代表性问题例如垃圾邮件,结构缺陷或是文本上的误差。
4. 聚集
将数据集基于相似点分散到不同的组(集群)。
- 推荐系统
考虑Netflix和Amazon是如何推荐你可能喜欢的电影或产品的。
- 强化学习
AlphaFGo是最典型的深度学习例子。
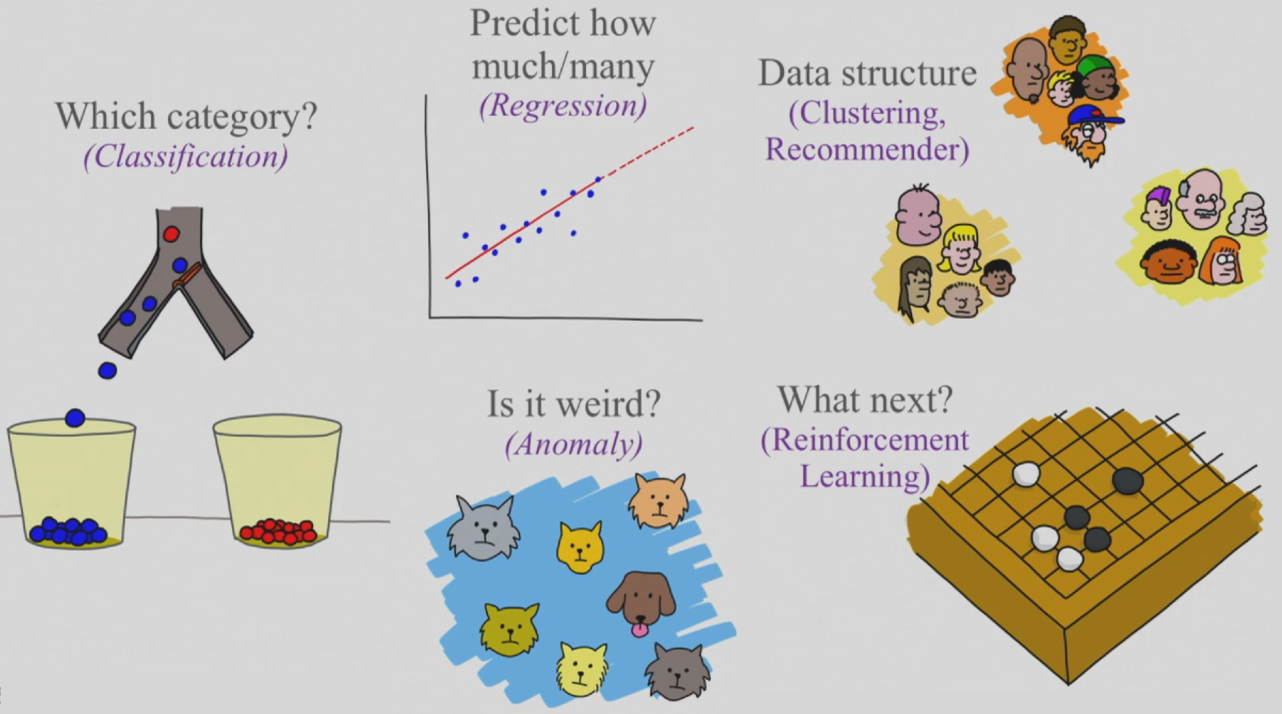
(数据科学家的五个问题)
数据科学是怎样工作的?
算法=食谱 你的数据=材料 计算机=搅拌机 你的答案=奶昔
为什么陷入AI?
上述五个问题展示了机器学习的力量,这是我们在传统计算机上所做不到的。例如,我们可以在Excel上做回归,但Excel不能做行星标量数据,这仅仅是因为没为它设计。因此,我们创造这些模块已经将所有相关部分的数据“蒸馏”从而将它运行为新的信息,这是非常有效率的。但是训练过程是非常昂贵和困难的。
为什么现在开始?
下图描述了AI,机器学习和人工神经网络(简称神经网络)的关系。
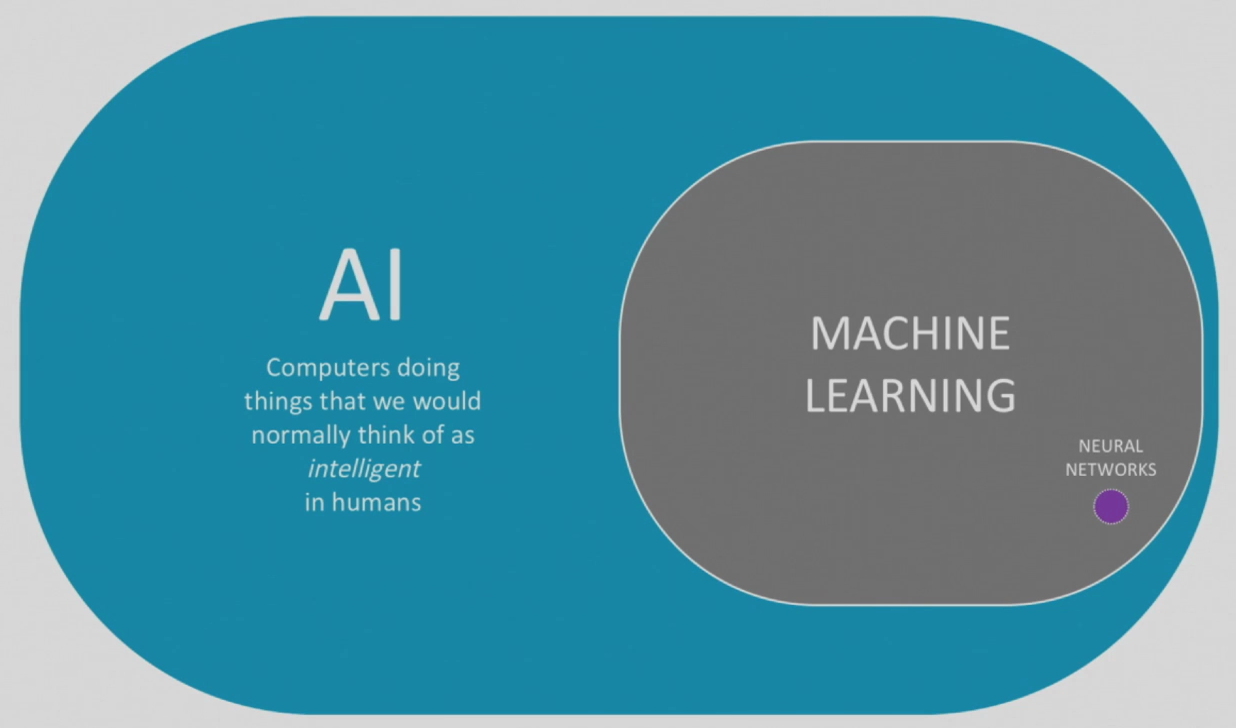
(AI层次)
学习策略
这有两种不同的方法去理解机器学习:
自顶向下
- 学习应用机器学习的高层次过程
- 找出怎样用工具就可以解决问题的方法
- 在数据集中实践
- 过渡到机器学习算法的细节和理论
自底向上
从理论开始
机器学习的两面性
—实用化的机器学习
活动内容是清理数据,查询数据库,变换数据,将算法和函数库粘合在一起。同时,你需要写自定义代码去从数据库中得到可靠的答案,从而从有挑战性或是不明确的问题中获得满足感。它很麻烦但是却很实在。
—理论上的机器学习
包括学术水平的数学,抽象,理想化的场景,限制。它非常干净简洁并且远离混乱的现实。
根据调查,激励,决心和目标是自底向上而上理论性的机器学习途径。这种途径比自顶向下实用性理论机器学习途径要难,但是通过理论,模型和过度参数的理解,它有着多得多的意义。同时也需要你投资大量的金钱与时间。
学习实用性数据清理,特征检测和理解不同的模型是一个迭代过程。在优化过程中你的学习直觉将会被开发出来。
一个新手不确定是否值得在研究机器学习上面花费精力,从而使自己在这领域变得精通。并且是否应该从自顶向下实用性机器学习路径开始入手。
那么,这两句出自百度首席科学家吴恩达的话用在这里是非常合适的;
“机器学习能力已经成熟到如果你上一节课的话你就可以非常容易地应用它了”
机器学习领域正在变得
“是在硅谷变得越来越吃香的技术之一”

(AI流行词)
上图有许多关于AI的流行词,你不需要孤注一掷地将它们突然都学完。大致了解一二就可以了。而现在,让我们讨论一下多方面的学习途径和数据科学浸入等级。
三种学习途径
- AI用户
它是一种自顶向下实用性机器学习途径。通过使用微软的“认知服务”(Cognitive Services) APIs,你可以变得擅长它。受过前期培训的模型使你建立apps时配合稳健算法并使用着少数几个代码。本质上来说你成为了“认知服务”的用户。在Build 2017中,微软表示他们开创了进一步发展的客户服务。下面是可用的服务截图:

(“认知服务”列表)
你可以通过在“认知服务”文档中看文件编制和教程来开始你的学习。此外,你也可以在Microsoft Virtual Academy与Azure Developer Workshop 观看视频学习课程。
- 数据科学家
数据科学家的职责包括创建多样的机器学习化工具或进程,比如推荐引擎或者自动化的引导评分系统。
开发者如何过渡到数据科学家?
在过去有着大量的数据科学和机器学习工具例如Matlab, Octave和Python等等。作为过程的一部分,数据科学家不得不精通数据分析。Matlab和Octave现在已经内嵌统计分析和绘图功能。而在Python中有大量可用的数据可视化程序包,比如numpy, matplotlib, Panda, Seaborn, Plotly 和 Cufflinks。
作为一名数据科学家,这有许多问题要问:
如何为机器学习组织数据?
- 如何清除数据?
- 如何处置丢失值?
- 特征工程如何工作?
- 怎样得到优质数据?
- 为什么要将数据可视化?
通过使用Azure Machine Learning Studio你可以做到上述所有步骤,并且尝到数据科学的甜头。
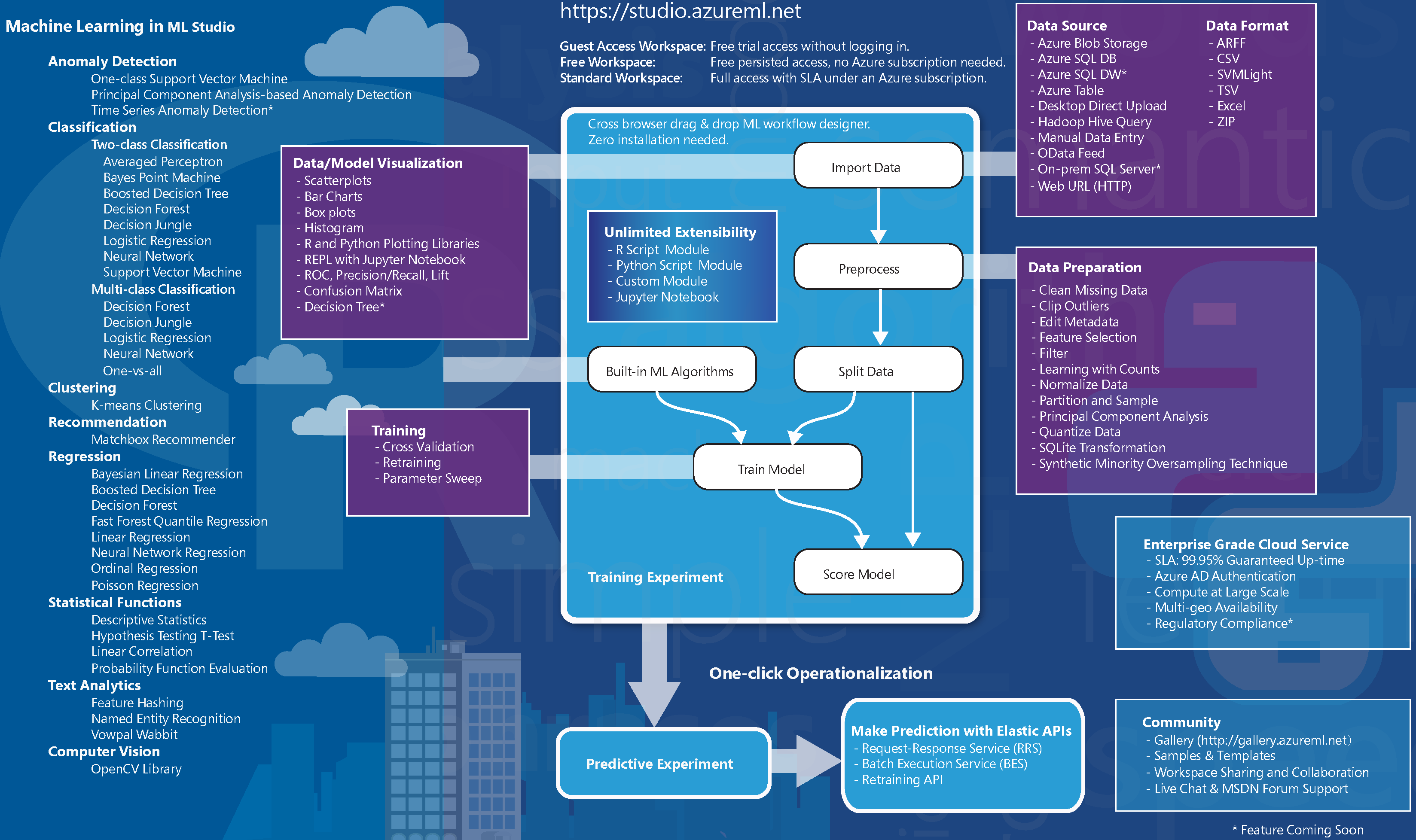 (ML Studio)
(ML Studio)
有许多可用的数据,教程和训练视频教你如何成为一名数据科学家。如果想以这个职业为目标的话,可以推荐你学习Microsoft Professional Program for Data Science的网课,里面的有大量的开放网络学习课程(Massive Open Online Course)简称“MOOC”,它是由许多视频讲座组成的长期课程。
对数据科学家学习路径的建议
“认知服务”中有许多不错的东西可以学习,它们可以解决你的疑惑。还有Azure ML Studio也是一个非常棒的学习路径,它类似于20年前的VB有着令人惊讶的可视化功能,可以帮助许多非专业人士学习并且看到成果。
 (AI学习路径)
(AI学习路径)
- 机器学习工程师
最终的级别是机器学习工程师,除了要熟知数据科学家的技能之外,还要能够设计模型,对超参数进行调整并对机器学习模型进行包装。
所要掌握的基本功:
- 计算机科学的基本原理和编程
- 概率与统计
- 数据建模和评估
- 应用机器学习算法和函数库
- 软件工程和系统设计
这里有一些可用的MOOCs教你必要的基本功,如果你想深度学习的话可以浏览以下课程资源
- CS231n: Convolutional Neural Networks for Visual Recognition – Stanford
- Andrej Karpathy on Medium
- Andrej Karpathy blog
- Christopher Olah (my other Hungarian countryman) blog
- Zero to Deep Learning with Python and Keras – Jose Portilla, Udemy
Microsoft Cognitive Toolkit之前以CNTK被大众所熟知,类似于谷歌的Tensorflow可以使你能够开发复杂的神经网络模型,通过USQL 和 Python分别运行在你本地的GPU,Azure, inside Azure Data Lake 和SQL Server 2017上。同时推荐一下Sayan Pathak博士和 Roland Fernandez将在6月26日开展的edX Cognitive Toolkit 课程。
 (edX Cognitive Toolkit课程)
(edX Cognitive Toolkit课程)
批次AI (Batch AI)训练
Cognitive Toolkit包括多重GPU,多服务器集群的实训。现在批次AI训练可能把ND系列Azure节点与NVIDIA Tesla P40 和P100 GPUs组合到一起。
| 大小 | CPU’s | GPU | 内存 | 网络 |
| ND6s | 6 | 1 P40 | 112 GB | Azure Network |
| ND12s | 12 | 2 P40 | 224 GB | Azure Network |
| ND24s | 24 | 4 P40 | 448 GB | Azure Network |
| ND24rs | 24 | 4 P40 | 448 GB | InfiniBand |
| 大小 | CPU’s | GPU | 内存 | 网络 |
| NC6s_v2 | 6 | 1 P100 | 112 GB | Azure Network |
| NC12s_v2 | 12 | 2 P100 | 224 GB | Azure Network |
| NC24s_v2 | 24 | 4 P100 | 448 GB | Azure Network |
| NC24rs_v2 | 24 | 4 P100 | 448 GB | InfiniBand |
感兴趣的话可以观看Navigating the AI Revolution的学习路径,教你如何从一名开发者变成AI用户,数据科学家或者机器学习工程师。
AI的发展有多快?
谷歌大脑项目在2012年夏天识别出图像中的猫咪,这个项目借助了16000个 CPU和12名科学家的努力。Geoffrey Hinton, Alex Krizhevsky 和 Ilya Sutskever三人在同年冬天通过一个名叫Convolutional Neural Network (CNN)技术只用了 3 GPU就做到了同样的事。
数据量相对较少的传统 ML 和神经网络恢复了相同的精度。然而,传统ML有点到达极限的趋势,但神经网络将会获得越来越多的数据。
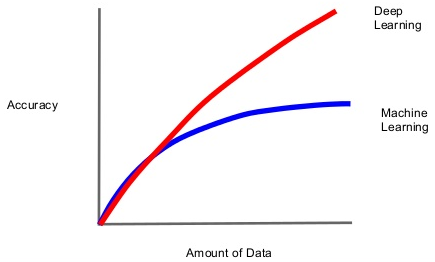
AI是无法停止的,它将发展的越来越快。思考模式的转移将会是IT历史上最大的革命,就像海啸一样将它自己原有的路径一扫而光。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消