











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌开源其语义图像分割模型DeepLab-v3+
2018年03月13日 由 xiaoshan.xiang 发表
582281
0
语义图像分割是为图像中的每个像素分配诸如“道路”,“天空”,“人”,“狗”之类的语义标签,它使得许多新的应用程序在(例如Pixel 2和Pixel 2 XL的智能手机和移动实时视频分割)竖屏模式下合成浅景深效果。分配这些语义标签需要确定对象的轮廓,因此比其他视觉实体识别任务(如图像级分类或边界盒级检测)更严格地要求定位精度。

今天,谷歌宣布了他们最新的和性能最好的语义图像分割模型的开源版本, DeepLab-v3+,可在Tensorflow中实现。此版本包含基于强大的卷积神经网络(CNN)骨干架构构建的DeepLab-v3 +模型,获得最准确的结果,用于服务器端部署。作为本次发布的一部分,谷歌还分享了他们的Tensorflow模型训练和评估代码,以及已经预先训练过的Pascal VOC 2012和Cityscapes 基准语义分割任务的模型。
自从三年前谷歌的DeepLab模型第一次改版以来,改进的CNN特征提取器,更好的对象比例建模,对上下文信息的仔细同化,改进的训练过程以及越来越强大的硬件和软件导致了DeepLab-v2和DeepLab-v3的改进。借助DeepLab-v3 +,我们通过添加简单而有效的解码器模块来扩展DeepLab-v3,以细化分割结果,尤其是对象边界。我们进一步将深度可分离卷积应用于空间金字塔池(atrous spatial pyramid pooling)和解码器模块,从而形成更快更强的用于语义分割的编码器 - 解码器网络。
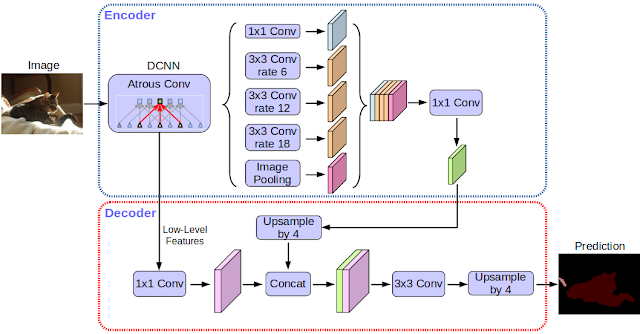
今天,谷歌宣布了他们最新的和性能最好的语义图像分割模型的开源版本, DeepLab-v3+,可在Tensorflow中实现。此版本包含基于强大的卷积神经网络(CNN)骨干架构构建的DeepLab-v3 +模型,获得最准确的结果,用于服务器端部署。作为本次发布的一部分,谷歌还分享了他们的Tensorflow模型训练和评估代码,以及已经预先训练过的Pascal VOC 2012和Cityscapes 基准语义分割任务的模型。
自从三年前谷歌的DeepLab模型第一次改版以来,改进的CNN特征提取器,更好的对象比例建模,对上下文信息的仔细同化,改进的训练过程以及越来越强大的硬件和软件导致了DeepLab-v2和DeepLab-v3的改进。借助DeepLab-v3 +,我们通过添加简单而有效的解码器模块来扩展DeepLab-v3,以细化分割结果,尤其是对象边界。我们进一步将深度可分离卷积应用于空间金字塔池(atrous spatial pyramid pooling)和解码器模块,从而形成更快更强的用于语义分割的编码器 - 解码器网络。
基于卷积神经网络(CNNs)之上的现代语义图像分割系统的精确度已经达到了难以想象的程度,这要归功于方法、硬件和数据集的进步。谷歌希望,向社区公开分享他们的系统,使学术界和业界的其他团体更容易复制和进一步改善该先进系统,训练新数据集的模型,并为这项技术设想新的应用程序。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消