











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






仔细看看,ARM的机器学习硬件具有怎样的优势?
2018年03月14日 由 nanan 发表
722183
0

几周前,ARM宣布推出第一批专用机器学习(ML)硬件。在“Project Trillium”项目中,该公司为智能手机等产品推出了专用的ML处理器,以及专门为加速对象检测(OD)用例而设计的第二款芯片。让我们更深入地研究下Project Trillium项目,以及该公司为不断增长的机器学习硬件市场制定的更广泛计划。
值得注意的是,ARM的声明完全与推理硬件有关。其ML和OD处理器被设计成能有效地在消费级硬件上运行经过训练的机器学习任务,而不是在庞大的数据集上训练算法。首先,ARM将重点放在ML推理硬件两大市场:智能手机和互联网协议/监控摄像头。
新的机器学习处理器
尽管Project Trillium发布了新的专用机器学习硬件公告,但ARM仍然致力于在其CPU和GPU上支持这些类型的任务,并在其Cortex-A75和A55内核中实现了优化的点积产品功能。Trillium通过更加优化的硬件增强了这些功能,使机器学习任务能够以更高的性能和更低的功耗完成。但是ARM的ML处理器并不仅仅是一个加速器——它本身就是一个处理器。
该处理器在1.5W的功率范围内拥有4.6 TOP/s的峰值吞吐量,使其适用于智能手机和更低功耗的产品。基于7纳米的实施,这给芯片提供了3 TOP/W的功率效率,同时,这对于节能产品开发商来说是一个很大的吸引力。
有趣的是,ARM的ML处理器与高通(Qualcomm)、华为(Huawei)和联发科技(MediaTek)采用一种不同的实现方式,所有这些处理器都重新设计了数字信号处理器(DSP),以帮助他们在高端处理器上运行机器学习任务。在MWC(全球行动通讯大会)的一次聊天中,ARM副总裁Jem Davies提到,收购DSP公司是进入这个硬件市场的一个选择,但最终,该公司决定为最常见的操作进行专门优化的地面解决方案。
ARM的ML处理器专为8位整数运算和卷积神经网络(CNNs)设计。它专门用于小字节大小数据的大量乘法,这使得它在这些类型的任务中比通用DSP更快,更高效。CNN被广泛用于图像识别,可能是目前最常见的ML任务。所有这些读取和写入外部存储器通常会成为系统中的瓶颈,因此ARM也包含了一大块内部存储器以加速执行。这个内存池的大小是可变的,ARM希望根据用例为其合作伙伴提供一系列优化设计。
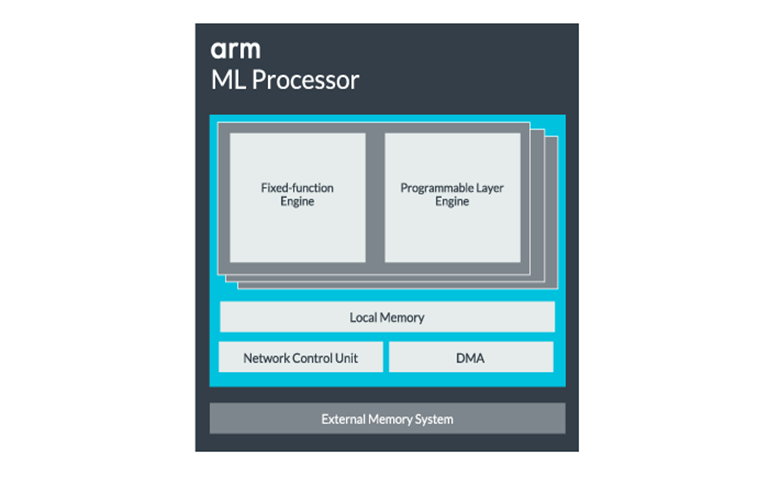
ARM的ML处理器专为8位整数运算和卷积神经网络而设计
ML处理器核心可以从单一核配置到16个核,以提高性能。每个组件包括优化的固定功能引擎和可编程层。这为开发人员提供了一定程度的灵活性,并确保处理器能够随着他们的发展而处理新的机器学习任务。该单元的控制由网络控制单元监控。
最后,处理器包含一个直接存储器访问(DMA)单元,以确保快速直接访问系统其他部分的内存。ML处理器可以作为自己的独立IP模块,具有ACE-Lite接口,可以将其并入SoC,或者作为SoC之外的固定模块运行,甚至可以与Armv8.2-A CPU(如Cortex-A75和A55)一起集成到DynamIQ集群中。集成到DynamIQ集群可能是一个非常强大的解决方案,可以为集群中的其他CPU或ML处理器提供低延迟数据访问并有效地完成任务调度。
适合所有的一切
去年ARM推出了Cortex-A75和A55 CPU处理器,以及高端的Mali-G72 GPU,但直到一年后才推出专用机器学习硬件。但是,ARM确实在其最新的硬件设备中对加速通用机器学习操作进行了相当多的关注,而这仍然是该公司未来战略的一部分。
其最新的主流设备Mali-G52图形处理器将机器学习任务的性能提高了3.6倍,这要归功于Dot产品(Int8)的支持和每个通道每个通道的四次乘法累加操作。Dot产品支持也出现在A75、A55和G72中。
即使有了新的OD和ML处理器,ARM仍在继续支持其最新CPU和GPU的加速机器学习任务。其即将推出的专用机器学习硬件的存在,使这些任务在适当的时候更加高效,但它是一个广泛的解决方案组合中的一部分,旨在满足其广泛的产品合作伙伴。
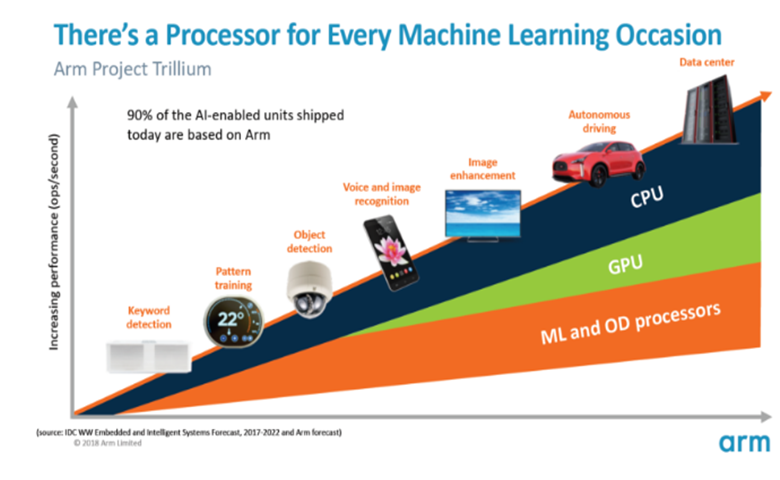
从单核到多核的CPU和GPU, 再到可以扩展到16核的可选ML处理器(可在SoC核心集群内外使用),ARM可支持从简单的智能扬声器到自动车辆和数据中心,其需要更强大的硬件。当然,该公司也提供软件来处理这种可扩展性。
该公司的Compute Library仍然是处理公司CPU、GPU和现在ML硬件组件的机器学习任务的工具。该库为图像处理、计算机视觉、语音识别等提供低级的软件功能,所有这些功能都运行在最适用的硬件上。ARM甚至用其CMSIS-NN内核为Cortex-M微处理器支持嵌入式应用程序。与基线功能相比,CMSIS-NN提供高达5.4倍的吞吐量和5.2倍的能效。
硬件和软件实现的这种广泛的可能性需要一个灵活的软件库,这正是ARM的神经网络软件的切入点。该公司并不打算取代像TensorFlow或Caffe这样的流行框架,而是将这些框架转换成与任何特定产品的硬件相关的库。因此,如果您的手机没有ARM ML处理器,则该库仍将通过在CPU或GPU上运行任务来工作。隐藏在幕后的配置以简化开发是它的目标。
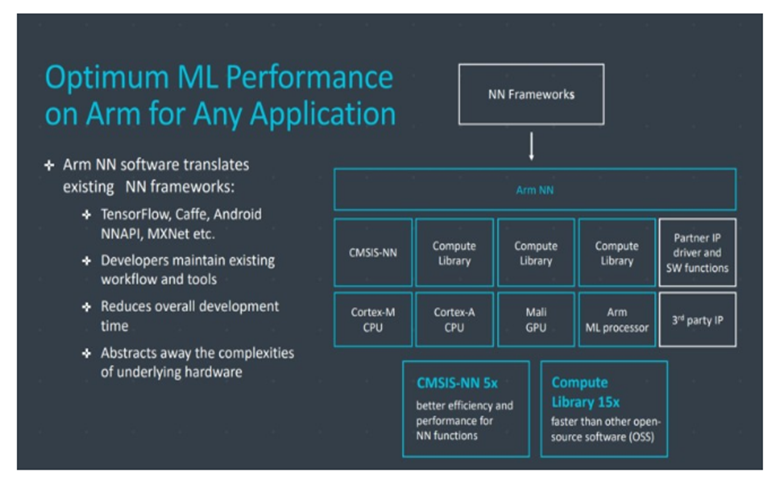
今天的机器学习
目前, ARM正专注于为机器学习领域的推理提供支持,使消费者能够在他们的设备上高效地运行复杂算法(尽管该公司并未排除参与硬件进行机器学习训练的可能性)。随着高速5G网络时代的到来,人们对隐私和安全的关注越来越多,ARM决定在边缘推动ML计算,而不是像谷歌那样聚焦在云上,这似乎是正确的选择。
最重要的是,ARM的机器学习能力并不仅限于旗舰产品。通过支持各种硬件类型和可扩展性选项,价格阶梯上下的智能手机可以受益,从低成本智能扬声器到昂贵服务器的各种产品都可以受益。甚至在ARM专用的ML硬件进入市场之前,利用它的Dot产品增强CPU和GPU的现代SoC,将会获得性能和能效的改进。
今年,我们可能不会在任何智能手机上看到ARM专用的ML和对象检测处理器,因为已经发布了大量SoC公告。相反,我们将不得不等到2019年,才能获得一些受益于Trillium项目及其相关硬件的第一批手机。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消