











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






伯克利AI实验室:看一个艺术字单词就能生成同种艺术风格的句子
2018年03月17日 由 yuxiangyu 发表
183445
0

左:给出电影海报,右:由MC-GAN生成的新电影片名。
文字是二维设计的需要突出的视觉元素。设计师花费大量时间来设计可以与其他元素的形状和纹理在视觉上兼容的字形。这个过程是劳动密集型的,设计师通常只设计标题或注释所需的字形子集,这使得设计完成之后很难更改文本,也很难将你观察到的字形设计转移到自己的项目中。
字形合成的早期研究主要集中在对于轮廓的几何建模上,这种方法使特定字形受到了拓扑的限制(例如,无法应用于装饰或手写字形),并且不能用图像做输入。随着深度神经网络的兴起,研究人员已经研究了从图像中建模字形的方法。另一方面,合成与部分观察一致的数据是计算机视觉和制图中有趣的问题。例如多视图图像生成,填补图像中的缺失区域以及生成三维图形。同时,字体数据也是一个提供风格与内容分解的例子。
因为条件生成对抗网络(cGANS)的最新进展,许多它生成的应用都取得了很好的成绩。但是,他们只在相当特化的领域才能做到最好,对于综合型或者说多领域的风格迁移却还不行。同理,当直接用于生成字体时,cGAN模型会产生显著的伪像(artifacts)。例如,输入以下五个字母,

条件GAN模型在生成具有相同样式的全部26个字母时并不成功:
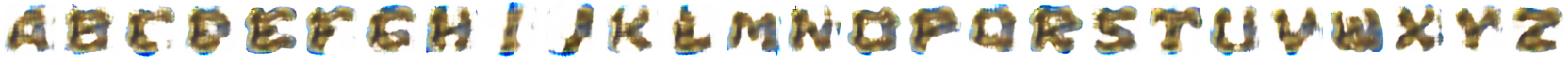
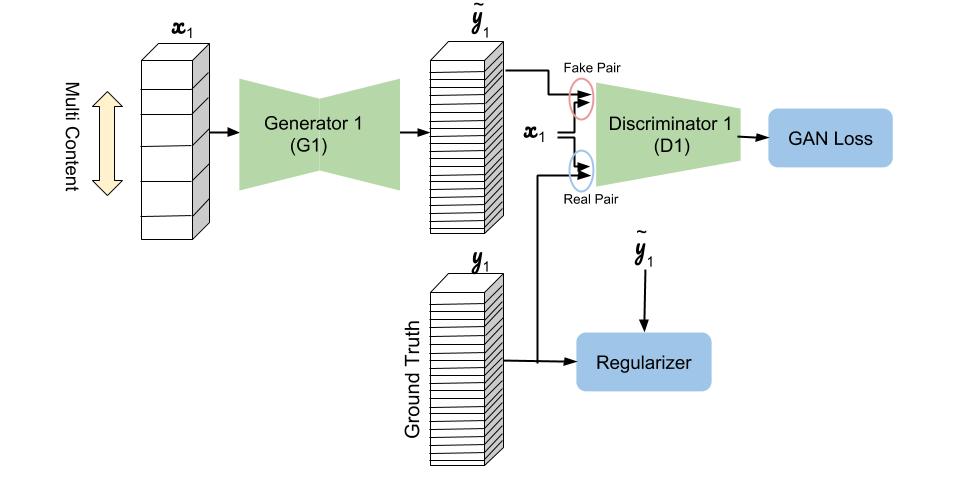
适用于少数字形风格迁移的多内容生成对抗网络
我们不为所有可能的字体装饰训练专门的网络,而是设计了一个多内容生成对抗网络(multi-content Generative Adversarial Networks,MC-GAN),为每个只少数观察到的字形字符集再训练了一个定制的神奇网络。该模型的思路是,用通道的内容(例如,字母A-Z)和网络层的风格(即字形的装饰),将给定字形的风格迁移给未见过的内容。
MC-GAN模型由一个用于预测粗字形形状的堆叠的cGAN架构,和一个预测最终字形的颜色和纹理的装饰网络组成。第一个网络称之为GlyphNet,它预测字形蒙版。第二个网络称为OrnaNet,用于对第一个网络生成的字形进行颜色和装饰的微调。每个子网络都属于条件生成对抗网络(cGAN)架构,为了修饰字形或预测装饰的特殊目的修改而来。
网络架构
下面是GlyphNet的示意图,用于从多种训练字体集合中,学习字体的大概外形。GlyphNet的输入和输出是为每个字母分配通道的字形堆栈。在每次训练迭代中,x1包括一个随机选择的y1字形子集,其余输入通道被清零。
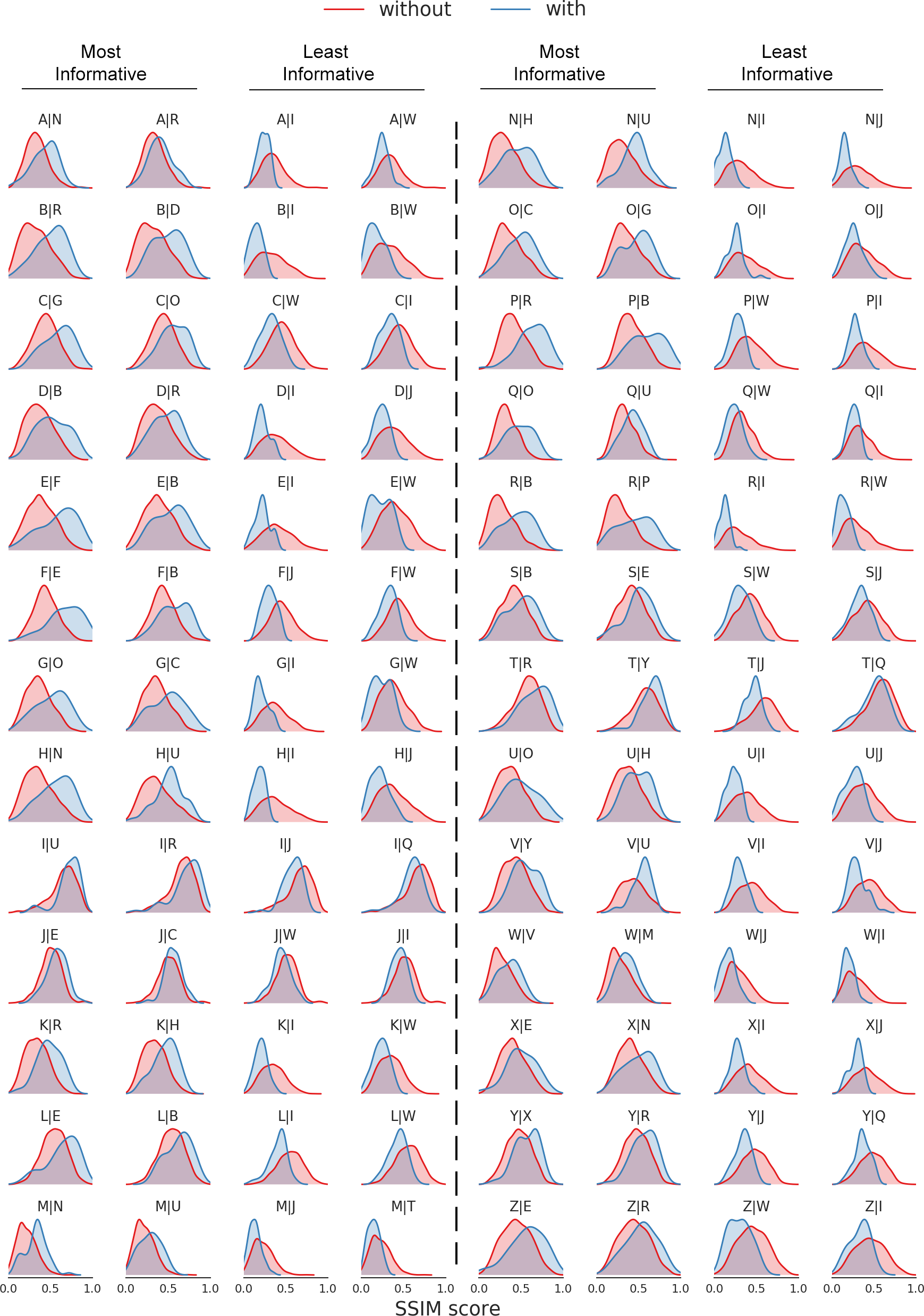
通过这种新颖的字形堆栈设计,不同字形之间的相关性可通过穿过网络的管道学习,以便自动转换其风格。下图表示通过结构相似性(SSIM)度量随机设置的1500个字体示例的这种相关性。计算每个生成的字形与其地面真值之间的结构相似性时,每次观察一个字母就可以找到25个分布。这些图显示了生成字母α的分布α|β,当字母β被观察时(蓝色)与其他字母被观察(红色)的对比。图中显示了,分别用于生成26个字母的,两个提供信息最多的字母的分布和两个提供信息最少的字母的分布。例如,图中的第五行,字母F和B在生成字母E时最有效,与其他字母相比较,而I和W提供的信息量最少。其他例子中,O和C是构造G最有效,R和B生成P最有效。
因此,对于只观察到少数字母的任何满足需要的字体,预先训练的GlyphNet都会生成全部字形。那么我们应该如何转移装饰?第二个网络OrnaNet得到这些生成的字形后,经过简单的变形和灰度重现(由下图中的T表示),使用cGAN架构生成期望中颜色和装饰的输出。OrnaNet的输入和输出是批量的RGB图像,而不是使用每一个字母的RGB通道的堆栈,作为一个图像是它对应的由GlyphNet生成的灰度字形。OrnaNet中使用多个正规化,处理了风格化字母对应字形形状的蒙版的偏差。
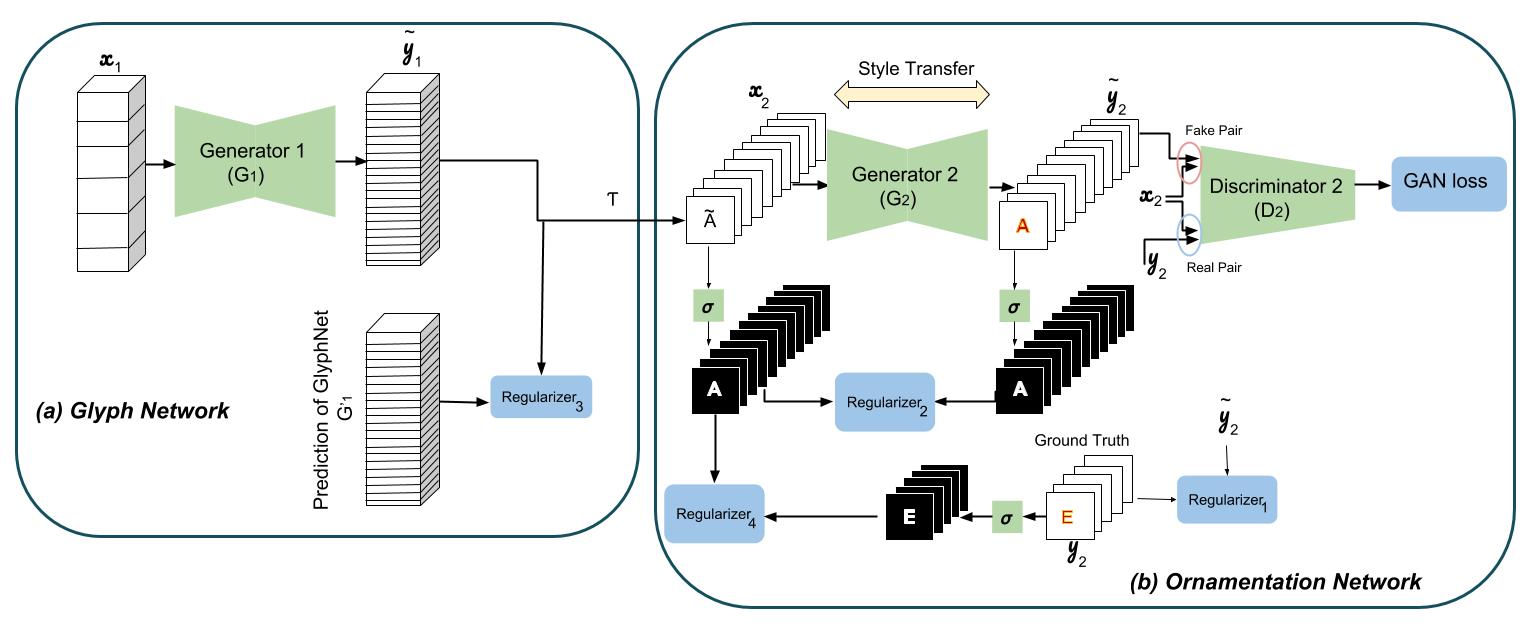
结果
下面,我们演示使用单词中给出的字体样式生成的示例句子。

节选
另外,下面是OrnaNet预测的逐步改进:
论文:https://arxiv.org/abs/1712.00516

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消